作者:张宇,北亚服务器数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
[数据恢复故障描述]
某网站服务器,品牌为组装,使用tyan(泰安)主板,AMD CPU*4,由4块68针SCSI硬盘 RAID0组成存储体系(听说2007年花了5万元买的,而且采用RAID0,这个专业程度真是不敢恭维)。
操作系统为LINUX,重要数据为MYSQL数据库及网站数据文件。
由于电源损坏(5万元买的设备竟然没有冗余电源),重新更换了电源测试,硬件销售商竟然怕数据损坏,留下RAID卡把硬盘全部拔掉启系统(真是无语了),再次连接启动系统时,RAID信息已经损坏。
之后做了一些操作。(此部分操作可能涉及责任问题,无法询问清楚)
最后的现象是:启动操作系统时提示无效的引导记录。
需要恢复服务器数据,同时重新激活修复服务器系统。
[数据恢复分析]
更换电源后,因硬盘全部拔掉,但RAID卡依然留在主机系统里,这样,加电检测RAID控制器时,就会认为所有硬盘已经存在故障,导致RAID逻辑卷下线。
重新加电后,虽然硬盘可能还是好的,但RAID控制器作为安全考虑,不会试图重新加载所有硬盘,重建RAID卷。这时候如果有一些正确有方式还有可能恢复数据(但数据重要的话不建议,可以参考我的其它文章),但估计用户采用的错误的方式进行了重建等操作,导致所有数据不可用。
RAID0本身不会涉及同步操作,故而除非重建时清0数据,其余情况应该不会有致命性损坏,但需要分析原RAID的结构,并进行虚拟重组。
[数据恢复过程]
1、对所有硬盘按单盘方式完整镜像。
2、在镜像中分析原RAID的结构参数。
3、搭建虚拟RAID环境,组织RAID逻辑卷。
4、为保证完整性,将数据打包为TAR.GZ。
5、重新配置RAID,安装系统,将恢复后的数据迁移回原系统。
2009年4月30日星期四
2009年4月28日星期二
找回在线写博因断网丢失的已编数据
在线写博偶尔会遇到这样的问题:花了好长时间码了好多字,一按提交,发现网断了,又没有保存在草稿里,如果不想重新写(会很痛苦的),可以参考一下以下办法。
恢复这些数据的原理是:当我们按下提交按钮时,浏览器会生成POST表单数据,以HTTP(或HTTPS)协议进行发送。这些POST表单数据会首先读入内存,再进行发送,读入内存的过程与网络是否畅通无关,所以在断网后,实际的POST数据还存在于内存当中,可以从内存中取回这些数据(当然要很快,因为内存空间已经释放,如果有别的进程申请内存空间,就有可能重写数据了)
用到一个工具,WINHEX。
出现问题后,尽可能保持当前状态,千万不要关闭浏览器窗口。只打开WINHEX->TOOLS->OPEN RAM
然后在弹出的窗口,选择我们编辑文件所用的浏览器进程(如果开了多个浏览器进程,可以依次尝试),再选中"Entrie Memory",单击"OK"
在打开的编辑窗口,按下CTRL+A,在编辑区点击右键,EDIT->COPY BLOCK->INTO NEW FILE。选择一下目标文件,导出。这一过程的目的是尽快地把内存的东西保存在磁盘上,就不用担心有变化了。
但如果开的浏览器进程很多,就最好不要先保存了,可以直接查找,以尽可能少得用到内存,避免因WINHEX操作太多重写需恢复数据区。
可以直接在打开的编辑窗口或在保存下来的文件中查特征字符串,可以是我们之前编辑内容中的一段特有数字、英文或中文(涉及字符集问题,不建议查中文),也可以是博客页面的一些POST特征。查找的内容出现的次数越少越好。
以本文为例,我可以查找“INTO NEW FILE”这个字符串:
查到后。将前后一片文本保存为一个文本文件,用记事本打开。
找到已经编辑的数据,复制。
在博客上重写一文章,标题、TAG等重写一下或者从恢复出来的文本中提取,内容区切换到源码状态,把复制的内容粘贴下来。
再切换过来看看,是不是以前编辑的数据又回来了?
注意:为了尽可能避免内存变更,如果之前没有安装过WINHEX,最好使用绿色版的WINHEX。
2009年4月27日星期一
linux ext3下删除mysql数据库的数据恢复案例
作者:张宇,北亚MYSQL数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
[数据恢复故障描述]
一台重要的MYSQL数据库服务器,146GB*2,RAID1,约130GB DATA卷,存储了大约200~300个数据库。平时管理员对每个数据库dump出以后,直接压缩成.gz包,再将所有重要的.gz 包合起来压缩成一个总的.tar.gz包,这些文件每日产生一次,覆盖原来的备份。数据文件及备份文件全部存储于data卷上。
一次系统维护中,管理员不小心将data卷下的所有文件全部rm,删除后,马上停止系统,再未做其它操作,但删除时仍有大量终端在访问此服务器。
要求恢复mysql数据库文件,即myd、frm、myi(可重建)文件,或每个数据库的.gz包,或所有重要数据库总的.tar.gz备份包。
[数据恢复分析]
ext3下的数据删除,理论上,会清除inode中除节点类型、日期外的其他属性,诸如文件大小、数据存储地址等属性会全部清0,同时目录表中会以目录条目长度的方式屏蔽掉已删除文件,但会保留节点编号,最后会改变BITMAP中的空间占用标志。
即使是目录表中存在删除文件的节点编号,但因节点内容已经没有需要的东西,与数据区也是脱钩的。
从数据角度,大多数文件类型都会有特定的文件头标志,按头标志是有可能找到删除文件的起始位置的,但EXT3以块组为单位进行存储,同时数据与索引是混合存储于数据区的,所以数据连续存储的可能性非常之小,这样,按文件格式进行处理也是很困难的。
唯一的算法是结合上述几个特征,加上对日志的分析,加上对存储过程的模拟分析,尽可能地逼近真实存储结构。
[数据恢复过程]
1、对故障卷做完整备份。
2、对总.tar.gz进行恢复分析,但恢复出来的文件解压到50%左右会报错,后续文件列表也无法列出。经分析,最大的原因是删除时仍有数据写入破坏文件导致。
3、对分包的.gz文件进行恢复分析,大多数恢复成功。
4、对于未恢复成功的.gz数据库。直接恢复其myd\frm数据文件,所有数据恢复成功。
[其他]
1、LINUX EXT3数据删除后应尽快断掉文件系统IO,通常umount文件系统即可。
2、对故障卷做dd备份,确保数据恢复过程不会导致更严重的故障。
[数据恢复故障描述]
一台重要的MYSQL数据库服务器,146GB*2,RAID1,约130GB DATA卷,存储了大约200~300个数据库。平时管理员对每个数据库dump出以后,直接压缩成.gz包,再将所有重要的.gz 包合起来压缩成一个总的.tar.gz包,这些文件每日产生一次,覆盖原来的备份。数据文件及备份文件全部存储于data卷上。
一次系统维护中,管理员不小心将data卷下的所有文件全部rm,删除后,马上停止系统,再未做其它操作,但删除时仍有大量终端在访问此服务器。
要求恢复mysql数据库文件,即myd、frm、myi(可重建)文件,或每个数据库的.gz包,或所有重要数据库总的.tar.gz备份包。
[数据恢复分析]
ext3下的数据删除,理论上,会清除inode中除节点类型、日期外的其他属性,诸如文件大小、数据存储地址等属性会全部清0,同时目录表中会以目录条目长度的方式屏蔽掉已删除文件,但会保留节点编号,最后会改变BITMAP中的空间占用标志。
即使是目录表中存在删除文件的节点编号,但因节点内容已经没有需要的东西,与数据区也是脱钩的。
从数据角度,大多数文件类型都会有特定的文件头标志,按头标志是有可能找到删除文件的起始位置的,但EXT3以块组为单位进行存储,同时数据与索引是混合存储于数据区的,所以数据连续存储的可能性非常之小,这样,按文件格式进行处理也是很困难的。
唯一的算法是结合上述几个特征,加上对日志的分析,加上对存储过程的模拟分析,尽可能地逼近真实存储结构。
[数据恢复过程]
1、对故障卷做完整备份。
2、对总.tar.gz进行恢复分析,但恢复出来的文件解压到50%左右会报错,后续文件列表也无法列出。经分析,最大的原因是删除时仍有数据写入破坏文件导致。
3、对分包的.gz文件进行恢复分析,大多数恢复成功。
4、对于未恢复成功的.gz数据库。直接恢复其myd\frm数据文件,所有数据恢复成功。
[其他]
1、LINUX EXT3数据删除后应尽快断掉文件系统IO,通常umount文件系统即可。
2、对故障卷做dd备份,确保数据恢复过程不会导致更严重的故障。
2009年4月23日星期四
ESX SERVER VMFS STORAGE被破坏后的数据恢复
作者:张宇,北亚VMWARE数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
对前几天接手的一个VMWARE ESX SERVER的数据恢复案子进行一下总结
[数据恢复故障描述]
中石化某省分公司,信息管理平台,几台ESX SERVER共享一台IBM DS4100存储,大约有40~50组虚拟机,占用1.8TB空间,数据重要。
正常工作中,vc里报告虚拟磁盘丢失,ssh到ESX中执行fdisk -l查看磁盘,发现storage已经没有分区表了。重启所有设备后,ESX SERVER均无法连接到DS4100所在的STORAGE。
仔细询问当时的管理员,他们提到一点,曾经在这个存储网络里连接过一台windows 2003服务器,具体情况不详。
[数据恢复分析]
很自然地想到了,可能是那台windows 2003因对storage的独享操作导致了整个vmfs卷损坏。
以整个存储做分析发现:
1、分区表清0,有55aa有效结束标志,有硬盘ID标志。
2、简单从前向后查看,发现一个NTFS卷,但似乎并未写数据进去,像一个刚刚格式化的卷,对这个NTFS卷的BITMAP做分析,得知大小约为1.8T(全部空间),前部占用部分空间,3G左右位置占用部分空间,0.9T附近占用部分空间,但总占用空间不超过100M。
3、针对VMFS卷进行分析,发现在原1.8TB的磁盘里有2组VMFS分区,第2组是对第一组的extend,第一组约1.5T,第二组约300GB,因NTFS分区并未写数据到第二个VMFS分区里(最后一个扇区的DBR备份没有覆盖有用数据),所以重点在于第一个VMFS分区。
4、分析第一组VMFS,卷头结构丢失,一级索引、二级索引均存在,NTFS覆盖的数据区正好是某组虚拟机的临时内存镜像,损坏也无妨。
[数据恢复过程]
1、对整个STORAGE进行镜像备份。
2、分析后,连接两个VMFS分区,直接按照VMFS分析组织方式提取所有VMDK及配置文件。
3、通过nfs直接迁移回ESX SERVER。
另:本例中因已对故障存储做了安全备份,修复中同时直接重建第一组VMFS卷头,索引列表、分区表等信息,直接附加在ESX SERVER环境,算是第二个方案。
[数据恢复结果]
花费2天时间(不计之后的迁移时间),全部数据恢复成功
[其他]
1、本例中依然是因为光纤环境互斥不当导致的问题,实际上,应该是这个卷在WINDOWS系统做了重新分区,并格式化成了NTFS,之后又对分区做了删除操作。因ESX VMFS的互斥不依赖于硬件,只依赖于操作系统驱动层,所以在其他服务器接入存储网络时一定要小心,尽量考虑好存储分配权限。
2、ESX因便捷的信息集中管理,真正使用中往往数据特别重要,一定要做好备份工作,并考虑损坏时迁移的方便性。
对前几天接手的一个VMWARE ESX SERVER的数据恢复案子进行一下总结
[数据恢复故障描述]
中石化某省分公司,信息管理平台,几台ESX SERVER共享一台IBM DS4100存储,大约有40~50组虚拟机,占用1.8TB空间,数据重要。
正常工作中,vc里报告虚拟磁盘丢失,ssh到ESX中执行fdisk -l查看磁盘,发现storage已经没有分区表了。重启所有设备后,ESX SERVER均无法连接到DS4100所在的STORAGE。
仔细询问当时的管理员,他们提到一点,曾经在这个存储网络里连接过一台windows 2003服务器,具体情况不详。
[数据恢复分析]
很自然地想到了,可能是那台windows 2003因对storage的独享操作导致了整个vmfs卷损坏。
以整个存储做分析发现:
1、分区表清0,有55aa有效结束标志,有硬盘ID标志。
2、简单从前向后查看,发现一个NTFS卷,但似乎并未写数据进去,像一个刚刚格式化的卷,对这个NTFS卷的BITMAP做分析,得知大小约为1.8T(全部空间),前部占用部分空间,3G左右位置占用部分空间,0.9T附近占用部分空间,但总占用空间不超过100M。
3、针对VMFS卷进行分析,发现在原1.8TB的磁盘里有2组VMFS分区,第2组是对第一组的extend,第一组约1.5T,第二组约300GB,因NTFS分区并未写数据到第二个VMFS分区里(最后一个扇区的DBR备份没有覆盖有用数据),所以重点在于第一个VMFS分区。
4、分析第一组VMFS,卷头结构丢失,一级索引、二级索引均存在,NTFS覆盖的数据区正好是某组虚拟机的临时内存镜像,损坏也无妨。
[数据恢复过程]
1、对整个STORAGE进行镜像备份。
2、分析后,连接两个VMFS分区,直接按照VMFS分析组织方式提取所有VMDK及配置文件。
3、通过nfs直接迁移回ESX SERVER。
另:本例中因已对故障存储做了安全备份,修复中同时直接重建第一组VMFS卷头,索引列表、分区表等信息,直接附加在ESX SERVER环境,算是第二个方案。
[数据恢复结果]
花费2天时间(不计之后的迁移时间),全部数据恢复成功
[其他]
1、本例中依然是因为光纤环境互斥不当导致的问题,实际上,应该是这个卷在WINDOWS系统做了重新分区,并格式化成了NTFS,之后又对分区做了删除操作。因ESX VMFS的互斥不依赖于硬件,只依赖于操作系统驱动层,所以在其他服务器接入存储网络时一定要小心,尽量考虑好存储分配权限。
2、ESX因便捷的信息集中管理,真正使用中往往数据特别重要,一定要做好备份工作,并考虑损坏时迁移的方便性。
2009年4月22日星期三
SUN平台,光纤共享存储互斥失败导致的数据灾难恢复
作者:张宇,北亚数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
[数据恢复故障描述]
两台SPARC SOLARIS系统通过光纤交换机共享同一存储,本意是作为CLUSTER使用,但配置不当,两台SERVER并未很好地对存储互斥,设计意图为:平时A服务器正常工作,当A服务器宕掉后,关掉A,开启B接管服务。
偶然的机会,一位管理人员开启B服务器,查到B服务器连接了一组很大的磁盘(实际上就是那个共享存储),因B服务器一直闲置未用,管理员以为磁盘也是闲置的,于是将整个磁盘的某个分区做了newfs。
A服务器很快报警并宕机,重启A服务器后,发现所有的文件系统均无法mount,执行fsck后,大多数分区的数据均修复成功,只有在B机做过newfs的文件系统结果不理想,根目录下只有一个lost+found文件夹,里面有大量数字标号的文件。
故障文件系统存储了两组ORACLE实例,原结构为UFS,约有200~400个数据文件需要恢复。
[数据恢复分析]
光纤设备的共享冲突案例很多,起缘于光纤交换的灵活性。此例中,A机与B机同时对UFS这个单机文件系统进行访问是很糟糕的,两台SERVER都以想当然的独享方式对存储进行管理,A机正常管理的文件系统其实底层上已经被B机做了文件系统初始化,A机从缓冲区写入文件系统的数据也会破坏B机初始化的结果。
B机newfs实际上直接会作用于原先的文件系统之上,但此例与单纯的newfs会有些不同,在A机宕机之前,会有一小部分数据(包括元数据)回写回文件系统。newfs如果结构与之前的相同,数据区是不会被破坏的,同时如果有一小部分元数据存在,部分数据恢复的可能性还是存在的。
UFS是传统的UNIX文件系统,以块组切割,每块组分配若干固定的inode区。文件系统newfs时,如果结构与之前的相同,文件系统最重要的inode区便会全部初始化,之前的无法保留,inode管理着所有文件的重要属性,所以单纯从文件系统角度考虑,数据恢复的难度很大。
好在oracle数据文件的结构性很强,同时UFS文件系统还是有一定的存储规律性,可以通过对oracle数据文件的结构重组,直接将数据文件、控制文件、日志等恢复出来。同时oracle数据文件本身会有表名称描述,也可以反向推断原来的磁盘文件名。
[数据恢复过程]
对故障的文件系统做dd备份。
针对整个镜像文件做完全的oracle数据结构分析、重组。
对部分结构太乱,无法重组的文件,参考ufs文件系统结构特征进行辅助分析。
利用恢复的数据文件、控制文件在oracle平台恢复数据库。
[数据恢复结论]
所有数据库完全恢复。
[后记]
fsck是很致命的操作,在fsck之前最好做好备份(dd即可)。
光纤存储的不互斥是非常多的数据灾难原因,方案应谨慎部署与实施。
[数据恢复故障描述]
两台SPARC SOLARIS系统通过光纤交换机共享同一存储,本意是作为CLUSTER使用,但配置不当,两台SERVER并未很好地对存储互斥,设计意图为:平时A服务器正常工作,当A服务器宕掉后,关掉A,开启B接管服务。
偶然的机会,一位管理人员开启B服务器,查到B服务器连接了一组很大的磁盘(实际上就是那个共享存储),因B服务器一直闲置未用,管理员以为磁盘也是闲置的,于是将整个磁盘的某个分区做了newfs。
A服务器很快报警并宕机,重启A服务器后,发现所有的文件系统均无法mount,执行fsck后,大多数分区的数据均修复成功,只有在B机做过newfs的文件系统结果不理想,根目录下只有一个lost+found文件夹,里面有大量数字标号的文件。
故障文件系统存储了两组ORACLE实例,原结构为UFS,约有200~400个数据文件需要恢复。
[数据恢复分析]
光纤设备的共享冲突案例很多,起缘于光纤交换的灵活性。此例中,A机与B机同时对UFS这个单机文件系统进行访问是很糟糕的,两台SERVER都以想当然的独享方式对存储进行管理,A机正常管理的文件系统其实底层上已经被B机做了文件系统初始化,A机从缓冲区写入文件系统的数据也会破坏B机初始化的结果。
B机newfs实际上直接会作用于原先的文件系统之上,但此例与单纯的newfs会有些不同,在A机宕机之前,会有一小部分数据(包括元数据)回写回文件系统。newfs如果结构与之前的相同,数据区是不会被破坏的,同时如果有一小部分元数据存在,部分数据恢复的可能性还是存在的。
UFS是传统的UNIX文件系统,以块组切割,每块组分配若干固定的inode区。文件系统newfs时,如果结构与之前的相同,文件系统最重要的inode区便会全部初始化,之前的无法保留,inode管理着所有文件的重要属性,所以单纯从文件系统角度考虑,数据恢复的难度很大。
好在oracle数据文件的结构性很强,同时UFS文件系统还是有一定的存储规律性,可以通过对oracle数据文件的结构重组,直接将数据文件、控制文件、日志等恢复出来。同时oracle数据文件本身会有表名称描述,也可以反向推断原来的磁盘文件名。
[数据恢复过程]
对故障的文件系统做dd备份。
针对整个镜像文件做完全的oracle数据结构分析、重组。
对部分结构太乱,无法重组的文件,参考ufs文件系统结构特征进行辅助分析。
利用恢复的数据文件、控制文件在oracle平台恢复数据库。
[数据恢复结论]
所有数据库完全恢复。
[后记]
fsck是很致命的操作,在fsck之前最好做好备份(dd即可)。
光纤存储的不互斥是非常多的数据灾难原因,方案应谨慎部署与实施。
2009年4月19日星期日
在esx server VI里导入其它虚拟机
作者:张宇,北亚数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
如果重新安装了esx server,或者需要迁移其它地方的虚拟机到另一个ESX SERVER上,往往需要做的步骤是:
1、导入vmfs storage
2、导入虚拟机配置文件
导入vmfs storage的方法见:《在esx server上导入其它vmfs storage》
导入虚拟机配置文件的方法如下:
VI->configuration->storage->选中其中一个STORAGE->Browse datastore...
然后找到原先存在的虚拟机目录,在其中的vmx文件上点右键,选择"add to Inventory",按照向导处理即可。
如果重新安装了esx server,或者需要迁移其它地方的虚拟机到另一个ESX SERVER上,往往需要做的步骤是:
1、导入vmfs storage
2、导入虚拟机配置文件
导入vmfs storage的方法见:《在esx server上导入其它vmfs storage》
导入虚拟机配置文件的方法如下:
VI->configuration->storage->选中其中一个STORAGE->Browse datastore...
然后找到原先存在的虚拟机目录,在其中的vmx文件上点右键,选择"add to Inventory",按照向导处理即可。
2009年4月17日星期五
在esx server上导入其它vmfs storage
作者:张宇,北亚数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
ESX SERVER推荐使用VMFS文件系统作为虚拟机存储使用,当然好处是很多了,但VMFS仅仅是VMWARE公司专用的一种CLUSTER类文件系统,所以对VMFS文件系统的读取会稍稍麻烦一点。
当重新安装ESX SERVER,或者从其它地方迁移过来的一个VMFS STORAGE,就需要对这个新的VMFS STORAGE重新激活。
利用VI的方法:
首先在Advanced Setting--->LVM里将LVM.DisallowSnapshotLun开关设置为1,将LVM.EnableResignaturing开关设置为1,然后在Advanced Setting--->Storage Adapters--->Rescan。即可在Storage里看到。
利用命令行方式:
用SSH登录后,执行:
echo 1>/proc/vmware/config/LVM/EnableResignature echo 1>/proc/vmware/config/LVM/DisallowSnapshotLun
然后再执行:
vmkfstools -s
ESX SERVER推荐使用VMFS文件系统作为虚拟机存储使用,当然好处是很多了,但VMFS仅仅是VMWARE公司专用的一种CLUSTER类文件系统,所以对VMFS文件系统的读取会稍稍麻烦一点。
当重新安装ESX SERVER,或者从其它地方迁移过来的一个VMFS STORAGE,就需要对这个新的VMFS STORAGE重新激活。
利用VI的方法:
首先在Advanced Setting--->LVM里将LVM.DisallowSnapshotLun开关设置为1,将LVM.EnableResignaturing开关设置为1,然后在Advanced Setting--->Storage Adapters--->Rescan。即可在Storage里看到。
利用命令行方式:
用SSH登录后,执行:
echo 1>/proc/vmware/config/LVM/EnableResignature echo 1>/proc/vmware/config/LVM/DisallowSnapshotLun
然后再执行:
vmkfstools -s
2009年4月16日星期四
dd for windows详细说明
作者:张宇,北亚数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
dd for windows下载地址:http://www.chrysocome.net/dd(或从网上找)
dd是一个在LINUX、UNIX下非常重要的磁盘镜像工具,现在终于有了WINDOWS版本。虽然dd是基于命令行方式的应用程序,操作不便捷,但命令行的应用程序优点却也是图形程序不具备的,比如,希望对硬盘做批量镜像,如果用图形界面程序处理,只能等待做完一个再做一个,而用命令行的dd,就可以下一个批处理命令来批量执行了。
dd for windows的执行格式为:
dd [bs=SIZE[SUFFIX]] [count=BLOCKS[SUFFIX]] if=FILE of=FILE [seek=BLOCKS[SUFFIX]] [skip=BLOCKS[SUFFIX]] [--size] [--list] [--progress]
其中:
bs代表镜像时缓冲块的大小,通常建议设得大一点,比如1M、10M等(单位可用:c表示字节,w表示双字,d表示4字节,q表示8字节,k表示1024字节,M表示k*k字节,G表示k*k*k字节),默认为512字节
count表示镜像的块总数
if与of分别表示镜像源与镜像目标的设备文件路径
seek表示在备份时对of后面的部分也就是目标文件跳过多少块再开始写
skip表示备份时对if后面的部分也就是原文件跳过多少块再开始备份
--size表示对源设备的读取进行大小校验,以避免IO死循环等错误
--list表示列出可利用的磁盘(分区)设备文件,在if与of中指定的这是这些设备名称
--progress表示显示镜像进度
示例:
对软盘做镜像:
dd if=\\.\a: of=c:\temp\disk1.img bs=1440k
对硬盘做镜像
先用 dd --list,查到要镜像的设备路径为:\\?\device\harddisk1\dr5
然后执行:
E:\>dd if=\\?\device\harddisk1\dr5 of=r:\aa.img --sizerawwrite dd for windows version 0.5.Written by John Newbigin <jn@it.swin.edu.au>This program is covered by the GPL. See copying.txt for details250880+0 records in250880+0 records out
dd for windows下载地址:http://www.chrysocome.net/dd(或从网上找)
dd是一个在LINUX、UNIX下非常重要的磁盘镜像工具,现在终于有了WINDOWS版本。虽然dd是基于命令行方式的应用程序,操作不便捷,但命令行的应用程序优点却也是图形程序不具备的,比如,希望对硬盘做批量镜像,如果用图形界面程序处理,只能等待做完一个再做一个,而用命令行的dd,就可以下一个批处理命令来批量执行了。
dd for windows的执行格式为:
dd [bs=SIZE[SUFFIX]] [count=BLOCKS[SUFFIX]] if=FILE of=FILE [seek=BLOCKS[SUFFIX]] [skip=BLOCKS[SUFFIX]] [--size] [--list] [--progress]
其中:
bs代表镜像时缓冲块的大小,通常建议设得大一点,比如1M、10M等(单位可用:c表示字节,w表示双字,d表示4字节,q表示8字节,k表示1024字节,M表示k*k字节,G表示k*k*k字节),默认为512字节
count表示镜像的块总数
if与of分别表示镜像源与镜像目标的设备文件路径
seek表示在备份时对of后面的部分也就是目标文件跳过多少块再开始写
skip表示备份时对if后面的部分也就是原文件跳过多少块再开始备份
--size表示对源设备的读取进行大小校验,以避免IO死循环等错误
--list表示列出可利用的磁盘(分区)设备文件,在if与of中指定的这是这些设备名称
--progress表示显示镜像进度
示例:
对软盘做镜像:
dd if=\\.\a: of=c:\temp\disk1.img bs=1440k
对硬盘做镜像
先用 dd --list,查到要镜像的设备路径为:\\?\device\harddisk1\dr5
然后执行:
E:\>dd if=\\?\device\harddisk1\dr5 of=r:\aa.img --sizerawwrite dd for windows version 0.5.Written by John Newbigin <jn@it.swin.edu.au>This program is covered by the GPL. See copying.txt for details250880+0 records in250880+0 records out
2009年4月8日星期三
IBM DS3200数据恢复手记,12块300GB sas raid5
作者:张宇,北亚数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
某医院DCOM成像系统存储,IBM DS3200,12块300GB SAS硬盘组成,RAID5,无 hot-spare,划分成两组logical driver,容量分别为2TB与1.3TB,存储数据量约1TB。
因集群系统(双机)故障,切换时RAID信息丢失,IBM工程师激活不成功,需恢复数据。
大致流程如下:
1、关闭DS3200电源,将所有12块硬盘全部拆下,标好号(以确定操作是可逆的,对于数据恢复而言不必需)。之后不再开启DS3200电源。
2、按《RAID损坏后 对数据的完整备份》中的备份方式,对源盘做完整备份,备份完成后交回原盘,确保恢复过程完全无风险。备份时选择具备RAID5的目标存储体,以确保备份数据安全,避免因数据故障导致的恢复周期延长,我们的目标存储为DELL MD3000(12*1TB RAID5)。如果数据特别急,可以在征求客户同意的前提下,直接以只读的方式恢复数据到另外的存储介质,恢复方式见下面。
3、对做好的12块硬盘镜像进行逻辑分析,重点在于:盘充(这12块硬盘在原控制器上的组合顺序)、块大小(即组成原RAID的条带大小)、校验方式(校验的循环走向、同一条带的数据排序方式等)、logical driver在每块单盘上的起始位置、是否有数据满后(是否需要剔除陈旧盘)。 4、按照分析好的RAID参数,搭建虚拟RAID控制器(软件模拟),通过虚拟RAID控制器对单盘(或镜像)进行组织,形成虚拟卷(只读)。
5、对虚拟卷做文件系统解释,导出数据(只读),即完成所有数据恢复过程。
本例中,镜像花费约10小时,分析结构花费约半小时,恢复数据花费约10小时
某医院DCOM成像系统存储,IBM DS3200,12块300GB SAS硬盘组成,RAID5,无 hot-spare,划分成两组logical driver,容量分别为2TB与1.3TB,存储数据量约1TB。
因集群系统(双机)故障,切换时RAID信息丢失,IBM工程师激活不成功,需恢复数据。
大致流程如下:
1、关闭DS3200电源,将所有12块硬盘全部拆下,标好号(以确定操作是可逆的,对于数据恢复而言不必需)。之后不再开启DS3200电源。
2、按《RAID损坏后 对数据的完整备份》中的备份方式,对源盘做完整备份,备份完成后交回原盘,确保恢复过程完全无风险。备份时选择具备RAID5的目标存储体,以确保备份数据安全,避免因数据故障导致的恢复周期延长,我们的目标存储为DELL MD3000(12*1TB RAID5)。如果数据特别急,可以在征求客户同意的前提下,直接以只读的方式恢复数据到另外的存储介质,恢复方式见下面。
3、对做好的12块硬盘镜像进行逻辑分析,重点在于:盘充(这12块硬盘在原控制器上的组合顺序)、块大小(即组成原RAID的条带大小)、校验方式(校验的循环走向、同一条带的数据排序方式等)、logical driver在每块单盘上的起始位置、是否有数据满后(是否需要剔除陈旧盘)。 4、按照分析好的RAID参数,搭建虚拟RAID控制器(软件模拟),通过虚拟RAID控制器对单盘(或镜像)进行组织,形成虚拟卷(只读)。
5、对虚拟卷做文件系统解释,导出数据(只读),即完成所有数据恢复过程。
本例中,镜像花费约10小时,分析结构花费约半小时,恢复数据花费约10小时
2009年4月6日星期一
问专家:U盘突然无法识别了,数据还能恢复吗
作者:张宇,北亚数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
U盘插入USB HUB后无法识别,再接到其他USB口时依然提示:“跟这台计算机连接的一个USB设备运行不正常。。。”需要恢复数据。
导致 “跟这台计算机连接的一个USB设备运行不正常。。。”故障的原因大致有几个:
1、USB接口电压不足
2、U盘接口电路松动或损坏
3、晶振损坏
4、主控芯片(驱动芯片)损坏
如果是接口电压不足,可以更换环境再试。
如果是电路故障,需要拆开进行电路检查。
如果是晶振损坏,更换即可
如果是主控芯片损坏,可以更换相同或兼容的主控芯片来恢复数据,有时候同一型号的U盘,主控芯片也不一定相同。如果无法找到匹配的主控芯片,可以用PC3K FALSE等解码工具对存储芯片直接解码,但需要工具支持。如果没有工具可以对存储芯片进行解码,最后可通过编程器读取芯片内容后进行人工反向解码,再进行数据恢复,复杂程度很高。
针对文章开始的案例,后来得知,在同一USB HUB上接过的其他U盘也有损坏,可知是因USB HUB故障导致,很大可能是因电流、电压的错误导致U盘内部物理结构。
这类情况也算起个警示作用,最好的避免数据灾难的办法只有备份!
U盘插入USB HUB后无法识别,再接到其他USB口时依然提示:“跟这台计算机连接的一个USB设备运行不正常。。。”需要恢复数据。
导致 “跟这台计算机连接的一个USB设备运行不正常。。。”故障的原因大致有几个:
1、USB接口电压不足
2、U盘接口电路松动或损坏
3、晶振损坏
4、主控芯片(驱动芯片)损坏
如果是接口电压不足,可以更换环境再试。
如果是电路故障,需要拆开进行电路检查。
如果是晶振损坏,更换即可
如果是主控芯片损坏,可以更换相同或兼容的主控芯片来恢复数据,有时候同一型号的U盘,主控芯片也不一定相同。如果无法找到匹配的主控芯片,可以用PC3K FALSE等解码工具对存储芯片直接解码,但需要工具支持。如果没有工具可以对存储芯片进行解码,最后可通过编程器读取芯片内容后进行人工反向解码,再进行数据恢复,复杂程度很高。
针对文章开始的案例,后来得知,在同一USB HUB上接过的其他U盘也有损坏,可知是因USB HUB故障导致,很大可能是因电流、电压的错误导致U盘内部物理结构。
这类情况也算起个警示作用,最好的避免数据灾难的办法只有备份!
2009年4月5日星期日
问专家:有关一例EXT3文件系统故障
作者:张宇,北亚数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
一个网站服务器。数据卷为1TB硬盘一块,未做RAID,EXT3文件系统,未知原因,远程无法访问,到机房查询故障后发现文件系统无法mount,未做fsck。管理员为了安全,试图将整个硬盘dd到另一块相同的硬盘上再做分析及数据恢复工作,但dd备份时只能备份前320M数据,后面的无法读取,试图调整起始位置依然无济于事。因机房环境很吵,无法分辨硬盘是否有异响。
用户问了几个问题:
1、初步估计的故障是什么?数据恢复的可能性有多大?
答:最有可能的情况有两个:坏道或磁头不稳定。如果是坏道原因,可以通过专业的读取设备(如PC3K DE)进行读取,通常除绝对物理损坏的扇区无法读取外,其它扇区都有很大机会可读。如果是磁头不稳定,需要更换磁头方可读取数据,开盘换磁头的成功率取决于:工程师的能力、开盘的物理环境、备份的匹配程度、开盘后对数据的镜像方式(用设备读取成功率很高),但决定性因素是硬盘盘面是否刮伤,如果存在刮伤,即使其它方式做到最好,也无法恢复成功。
2、我的数据量很小,大约几十G,照EXT3的格式看,会不会存储于硬盘的最前端。这样,如果是坏道,是否可挑着恢复,比如只恢复前面数据?
答:ext3的格式的确是按照块组为单位,以渐减的方式存储数据与节点的,通常的确是从前向后存储的,但如果数据在存储过程中有删除、增加操作,其存储位置可能会有变化。
对于坏道,如果文件系统结构区可以一级一级地读出来,是可以按选择进行恢复的,或者确定数据就在前面几十G,也可以按这个区段进行读取。
3、这种情况是怎么产生的?应该如何避免?
答:即使是用SAS硬盘,作单盘存储本身也是不安全的,更何况是SATA硬盘(1TB的硬盘目前不可能是SAS,也不可能是IDE或SCSI)。单硬盘在长时间使用环境中,很难保证不出任何故障。如果需要避免,可选择用RAID的方式进行数据保护,同时需要做好备份工作(备份策略等)。
一个网站服务器。数据卷为1TB硬盘一块,未做RAID,EXT3文件系统,未知原因,远程无法访问,到机房查询故障后发现文件系统无法mount,未做fsck。管理员为了安全,试图将整个硬盘dd到另一块相同的硬盘上再做分析及数据恢复工作,但dd备份时只能备份前320M数据,后面的无法读取,试图调整起始位置依然无济于事。因机房环境很吵,无法分辨硬盘是否有异响。
用户问了几个问题:
1、初步估计的故障是什么?数据恢复的可能性有多大?
答:最有可能的情况有两个:坏道或磁头不稳定。如果是坏道原因,可以通过专业的读取设备(如PC3K DE)进行读取,通常除绝对物理损坏的扇区无法读取外,其它扇区都有很大机会可读。如果是磁头不稳定,需要更换磁头方可读取数据,开盘换磁头的成功率取决于:工程师的能力、开盘的物理环境、备份的匹配程度、开盘后对数据的镜像方式(用设备读取成功率很高),但决定性因素是硬盘盘面是否刮伤,如果存在刮伤,即使其它方式做到最好,也无法恢复成功。
2、我的数据量很小,大约几十G,照EXT3的格式看,会不会存储于硬盘的最前端。这样,如果是坏道,是否可挑着恢复,比如只恢复前面数据?
答:ext3的格式的确是按照块组为单位,以渐减的方式存储数据与节点的,通常的确是从前向后存储的,但如果数据在存储过程中有删除、增加操作,其存储位置可能会有变化。
对于坏道,如果文件系统结构区可以一级一级地读出来,是可以按选择进行恢复的,或者确定数据就在前面几十G,也可以按这个区段进行读取。
3、这种情况是怎么产生的?应该如何避免?
答:即使是用SAS硬盘,作单盘存储本身也是不安全的,更何况是SATA硬盘(1TB的硬盘目前不可能是SAS,也不可能是IDE或SCSI)。单硬盘在长时间使用环境中,很难保证不出任何故障。如果需要避免,可选择用RAID的方式进行数据保护,同时需要做好备份工作(备份策略等)。
2009年4月2日星期四
使用Handy Backup 6.2进行数据备份与还原(多图)
这几天比较了几个面向普通用户(文件级),位于WINDOWS平台自动备份软件,大致从几个方面进行测试:易用性、安全性、备份与还原的速度。先说说Handy Backup。
概括说一下,Handy Backup是一款功能强大的备份软件,支持自动备份到:CD-RW/DVD,硬盘或网络驱动器,ZIP、JAZ、MO和 FTP、LAN服务器,支持备份压缩(ZIP),支持备份加密(BLOWFISH 128位加密),可自动备份MS Outlook、注册表和ICQ文件,可增加插件增加备份数据源,同时支持备份硬盘镜像,支持多语言集(简体中文)。
安装过程很简单,这里不做介绍了。装好后,会在系统任务托盘常驻一个图标,双击此图标激活主界面:
选择语言为中文。

先制定一个测试用的备份计划:单击"文件"->"新建任务",调出任务对话框。

选择"备份任务"后,点下一步。

单击添加按钮,加入需要备份的数据源。

可选择的数据源真是很多,选择文件夹,测试备份一个文件夹。

单击下一步,选择备份方式,可选完全备份与增量备份,视情况选择。













单击下一步后,选择备份目的地:
备份目的有很多种,可以是本地可访问的文件夹,也可以是FTP\SFTP(利用这一点,就可以做在线备份了,还原也可以),也可以是CD-R/CD-RW/BLU-RAY/HD-DVD/DVD(软件本身支持刻录功能),或者是在线备份服务(国内暂时不必考虑,价格不低,速度不快,也没有handy backup的代理商)
这里我暂选本地备份(如上图所示,备份目的地为F:\),下一步继续。
上图的选项中可选择压缩与加密,压缩采用ZIP算法,会影响性能,本地备份建议不要选。非对称的加密算法可提供对文件备份的安全保护,如果数据重要,或者在线备份,可以加上密码,实际测量备份时的速度会低很多(尤其是处理大量小文件),但多数支持加密的软件速度都不会快到哪里去,视需求选择吧。
选择后,单击下一步。
出现备份时机对话框,有两个选项,立即运行是非计划的方案,只运行一次,编排计划可设定备份策略。这里选择编排计划。单击下一步。

上图意味着我们要每天12:33:20执行一次对"d:\qq files" 的增量备份。单击下一步进入结束页:
单击完成,返回主界面。
这样,备份策略便设定好了,在设定的时间内,备份计划将实施。
还原策略的设定与备份相似,只连续截图说明:

Handy Backup的使用感受:
1、方便使用,设置简单,支持简体中文
2、支持介质与数据源较多,支持备份到光盘。
3、可加密备份。
4、备份时生成索引文件,使增量备份/还原时速度更快。但感觉索引文件太重要了,尤其是加密后,如果没有索引文件将无法解开数据,还得注意多备份索引文件。
5、备份速度在不加密时很快,但加密后速度很慢(北亚数据恢复中心张宇曾经测试,500M的网站数据,本地加密备份,花了1小时)
6、支持FTP备份与还原,可做在线备份/还原使用。
7、还原时无法选择部分还原,只能全部还原或增量还原。如果备份包数据太多,可能是很麻烦的事情,尤其是在加密备份时,建议按功能拆成多个小包进行备份。
[问专家]误GHOST之后的数据还能恢复吗?
一个用户的咨询电话整理:
[用户]
我的硬盘用GHOST重做了系统,结构分区数目与分区大小与原来都不相同了,原来的文件系统是NTFS的,有5个分区,现在变成了4个FAT32的分区。
我的硬盘用GHOST重做了系统,结构分区数目与分区大小与原来都不相同了,原来的文件系统是NTFS的,有5个分区,现在变成了4个FAT32的分区。
这种情况能否恢复数据?成功率有多高?
[张宇]
硬盘在重新GHOST,变成4个分区之后,格式化了吗?有没有写过数据进去?
硬盘在重新GHOST,变成4个分区之后,格式化了吗?有没有写过数据进去?
[用户]
没有写过数据进去,不知道是否格式化了,能打开4个分区,但里面的空的。
没有写过数据进去,不知道是否格式化了,能打开4个分区,但里面的空的。
[张宇]
那是分区后,又做了格式化。
那是分区后,又做了格式化。
[用户]
那这种数据还能恢复吗?另外,有GHOST之前,我做错的操作,把C盘的数据全部GHOST到D盘了,这个还影响吗?实际上,最初我是想对C盘做个备份,结果不太熟,做完后,发现D盘和C 盘一模一样了,于是想自己恢复一下,重新用GHOST做了后,发现变成了4个分区,原来的E,F,G也没有了。这时候,就再也没敢动过了。
那这种数据还能恢复吗?另外,有GHOST之前,我做错的操作,把C盘的数据全部GHOST到D盘了,这个还影响吗?实际上,最初我是想对C盘做个备份,结果不太熟,做完后,发现D盘和C 盘一模一样了,于是想自己恢复一下,重新用GHOST做了后,发现变成了4个分区,原来的E,F,G也没有了。这时候,就再也没敢动过了。
[张宇]
如果是这样,那D盘的数据通常会麻烦一点,其他分区的数据应该问题不大,是有机会恢复的,当然,具体情况是需要做分析的,一个最简单的原则是,如果数据没有覆盖,就有机会恢复,如果数据被覆盖,数据就没希望了。你的情况,第一步做了C到D的GHOST,这时候不会影响其他分区的数据。但第二步做完后,因为有新的分区结构产生了,又做了格式化,操作系统会在为每个分区写一些数据,格式化也是写数据的一个过程,可能会有一些破坏。如果是FAT32,每个分区大约会写十几M或几十M的数据。至于恢复的可靠性,要看写入的这些数据的位置,如果正好位于原来硬盘的自由空间上,就不会有任何影响;如果正好位于数据区,那可能会影响这个数据区原先存储的文件,就是几M或几十M的影响;如果正好位于文件系统区,就要进一步分析,情况会多一些,是差的情况,可能会影响大量数据,不仅仅是几M或几十M,这个因为涉及的因素很多,暂不多谈,只说一点:覆盖文件系统核心区的概念是很低的,通常不必太焦虑。
如果是这样,那D盘的数据通常会麻烦一点,其他分区的数据应该问题不大,是有机会恢复的,当然,具体情况是需要做分析的,一个最简单的原则是,如果数据没有覆盖,就有机会恢复,如果数据被覆盖,数据就没希望了。你的情况,第一步做了C到D的GHOST,这时候不会影响其他分区的数据。但第二步做完后,因为有新的分区结构产生了,又做了格式化,操作系统会在为每个分区写一些数据,格式化也是写数据的一个过程,可能会有一些破坏。如果是FAT32,每个分区大约会写十几M或几十M的数据。至于恢复的可靠性,要看写入的这些数据的位置,如果正好位于原来硬盘的自由空间上,就不会有任何影响;如果正好位于数据区,那可能会影响这个数据区原先存储的文件,就是几M或几十M的影响;如果正好位于文件系统区,就要进一步分析,情况会多一些,是差的情况,可能会影响大量数据,不仅仅是几M或几十M,这个因为涉及的因素很多,暂不多谈,只说一点:覆盖文件系统核心区的概念是很低的,通常不必太焦虑。
D盘的数据涉及的问题也是很复杂的,通常这已经产生的覆盖,恢复的机率在分析之前无法判断。通常一个不一定很正确、但概率最大的理解方式是:如果原来有10个G的数据量,现在写进去了3个G,那有可能还能恢复10-3=7G的数据。但这样的算法其实是很不科学的,只能说明数据恢复的大致原则。
[用户]
那这样的数据恢复,如果做不成功,会不会对硬盘造成破坏,在一家数据恢复公司恢复完后,如果做不成,是否会影响下次恢复?
那这样的数据恢复,如果做不成功,会不会对硬盘造成破坏,在一家数据恢复公司恢复完后,如果做不成,是否会影响下次恢复?
[张宇]
正规的做法是不会对硬盘有任何破坏的,我们的做法是以不加载硬盘盘符的方式进行读操作,通过虚拟方式进行分析还原。即便是数据已经恢复出来了,在确认之前也仅仅是在虚拟环境下的,不会对原来的结构有任何不可逆的操作。如果无法恢复,或者用户确定不需要恢复了。硬盘完全和我们恢复之前是一模一样的。
正规的做法是不会对硬盘有任何破坏的,我们的做法是以不加载硬盘盘符的方式进行读操作,通过虚拟方式进行分析还原。即便是数据已经恢复出来了,在确认之前也仅仅是在虚拟环境下的,不会对原来的结构有任何不可逆的操作。如果无法恢复,或者用户确定不需要恢复了。硬盘完全和我们恢复之前是一模一样的。
当然,我们前提也有申明,恢复过程中也有可能出现人力无法避免的灾难,比如硬盘突然非人为损坏了,但这个可能性是极低的。我们的恢复也是完全在客户监督下完成的。
[用户]
恢复的时间,价格以及付款方式是什么?
恢复的时间,价格以及付款方式是什么?
2009年4月1日星期三
RAID损坏后,对数据的完整备份
作者:张宇,北亚数据恢复中心,创作于2007年7月31日,最初发布于51CTO博客上.转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
RAID中对单盘做镜像的方式(以SAS硬盘为例):
-、关闭磁盘阵列,将所有硬盘依次拔下来(最好标记好顺序号),挂接在不含RAID功能的SAS适配器上。
下图为拔下硬盘的正面及背面图(SAS硬盘有2.5与3.5寸两种接口,图中为3.5寸)


下图为其接口放大:

上图接口为SAS接口。只能用SAS适配器连接。RAID损坏后,要想完整备份源数据,必须保证对所有硬盘的读写都是可回溯的。为此,只能使用不含RAID功能的SAS适配器进行连接后镜像,这样才能以单硬盘的方式进行访问。
下图为PCI-E接口的SAS适配卡。

上图中的卡,已连接好数据线。可以最多连接4块SAS硬盘(末端的接口可直接连接硬盘),此卡为PCI-E 8×接口。
连接好硬盘的示意图如下:

下图中的卡为PCI-X接口SAS适配卡。

使用下图连线可直接连接SAS硬盘

连接好线后的图如下:

全部连接好的图如下所示:




二、保证挂接服务器使用操作系统为WIN2003(其他系统也可以,本例以 WINDOWS为例)。
进入系统后,磁盘管理里会看到多个单独的硬盘,此时切记不可初始化磁盘、分区或分配盘符给可能的磁盘分区(如果不确定是否可避免,建议不要进入磁盘管理)。
推荐的作法是利用直接可访问磁盘底层扇区内容的16进制编辑器。以WINHEX为例,安装好WINHEX后,进入WINHEX,如下图所示:
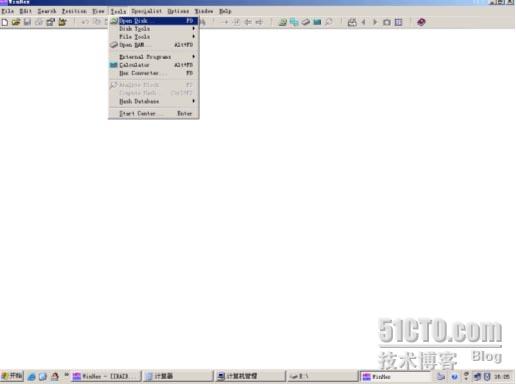
点击Tools—>Open disk菜单,如下图:
点击后出现如下图所示:
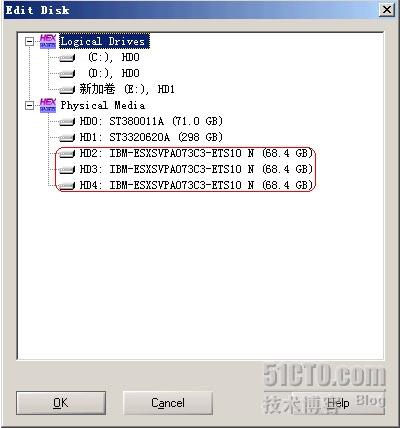
上图中Physical Media下列出的便是当前系统挂接到的所有物理存储设备,不经过RAID,以单盘的方式挂接,此列表就会出现物理硬盘的MODEL号及容量。上图中红色框内的便是3块IBM73G 单盘的ID显示。如果选中某块硬盘,点击OK按钮便可以以物理地址16进制的方式打开磁盘(此时不管有没有分区,什么文件系统,都无关重要。打开的便是硬盘73G 的存储空间内容),当然,在做镜像时,并不需要打开。我们只是打开这个对话框确定一下硬盘是否挂上。选择Cancel退出。
开始做镜像:
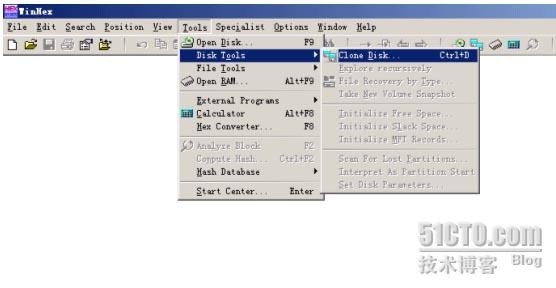
点击Tools->Disk tools->Clone Disk,如下图所示:
弹出的对话框如下图:
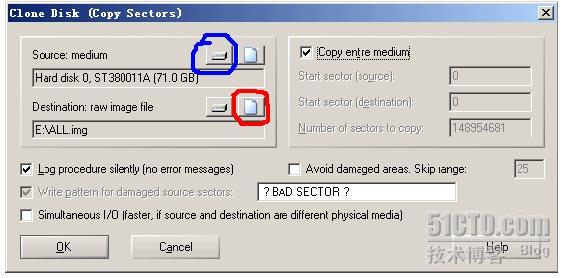
点击图中兰色所圈按钮,选择源磁盘。选中红色所圈按钮,选择目标文件。(我们的目的是将源硬盘镜像为一个文件,此后,这个文件就是对源硬盘的完整镜像了,大小等于源硬盘的大小,此例中,完成后,目标文件即有73G 之大)如下图
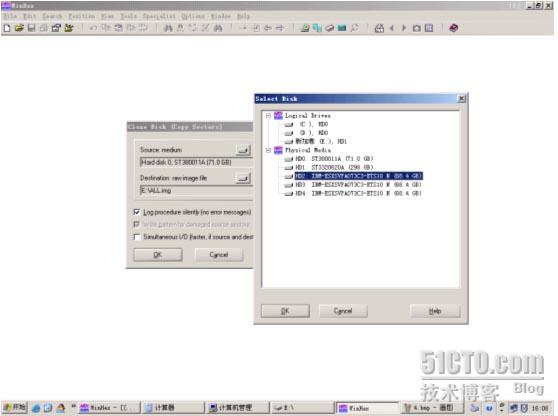
此例中选中HD2(即3块IBM SAS硬盘的第一块),点击OK后返回刚才的对话框,此时Source medium列表中便会出来选中的HD2 IBM…..
相同的方式,选择目标文件。如下图:
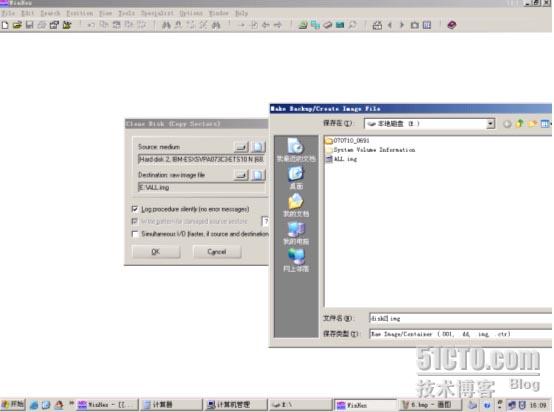
选好目标文件路径及文件名后。确定返回。
此时,Clone disk对话框如下图。
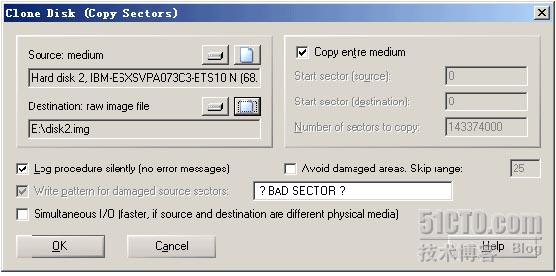
请再次确认,Source(源)及Destination(目标)是否正确。
对话框中的其他值应该为:点中Copy entire medium(意为做全盘的镜像),Log procedure…可选(选中后,会在拷贝结束后展示摘要,推荐使用,可以知道硬盘是否有坏道等),其他参数不要管(其他参数通常适用于严重坏道等情形)
选好后(一定要确认源和目标),按下OK按钮便开始镜像操作了(WINHEX第一次做此操作,当按下OK按钮时会弹出一个帮助框,意在提醒用户,此操作是有风险的。无碍,可关掉。之后不会再出现)
拷贝的过程如下图:
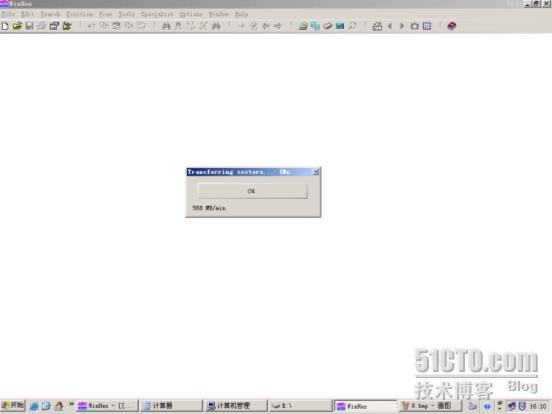
此过程完成后,镜像就完成了。目标文件即等同于源硬盘,之后可以使用WINHEX用逆向还原回原硬盘。
RAID中对单盘做镜像的方式(以SAS硬盘为例):
-、关闭磁盘阵列,将所有硬盘依次拔下来(最好标记好顺序号),挂接在不含RAID功能的SAS适配器上。
下图为拔下硬盘的正面及背面图(SAS硬盘有2.5与3.5寸两种接口,图中为3.5寸)
下图为其接口放大:
上图接口为SAS接口。只能用SAS适配器连接。RAID损坏后,要想完整备份源数据,必须保证对所有硬盘的读写都是可回溯的。为此,只能使用不含RAID功能的SAS适配器进行连接后镜像,这样才能以单硬盘的方式进行访问。
下图为PCI-E接口的SAS适配卡。
上图中的卡,已连接好数据线。可以最多连接4块SAS硬盘(末端的接口可直接连接硬盘),此卡为PCI-E 8×接口。
连接好硬盘的示意图如下:
下图中的卡为PCI-X接口SAS适配卡。
使用下图连线可直接连接SAS硬盘
连接好线后的图如下:
全部连接好的图如下所示:
二、保证挂接服务器使用操作系统为WIN2003(其他系统也可以,本例以 WINDOWS为例)。
进入系统后,磁盘管理里会看到多个单独的硬盘,此时切记不可初始化磁盘、分区或分配盘符给可能的磁盘分区(如果不确定是否可避免,建议不要进入磁盘管理)。
推荐的作法是利用直接可访问磁盘底层扇区内容的16进制编辑器。以WINHEX为例,安装好WINHEX后,进入WINHEX,如下图所示:
点击Tools—>Open disk菜单,如下图:
点击后出现如下图所示:
上图中Physical Media下列出的便是当前系统挂接到的所有物理存储设备,不经过RAID,以单盘的方式挂接,此列表就会出现物理硬盘的MODEL号及容量。上图中红色框内的便是3块IBM
开始做镜像:
点击Tools->Disk tools->Clone Disk,如下图所示:
弹出的对话框如下图:
点击图中兰色所圈按钮,选择源磁盘。选中红色所圈按钮,选择目标文件。(我们的目的是将源硬盘镜像为一个文件,此后,这个文件就是对源硬盘的完整镜像了,大小等于源硬盘的大小,此例中,完成后,目标文件即有
此例中选中HD2(即3块IBM SAS硬盘的第一块),点击OK后返回刚才的对话框,此时Source medium列表中便会出来选中的HD2 IBM…..
相同的方式,选择目标文件。如下图:
选好目标文件路径及文件名后。确定返回。
此时,Clone disk对话框如下图。
请再次确认,Source(源)及Destination(目标)是否正确。
对话框中的其他值应该为:点中Copy entire medium(意为做全盘的镜像),Log procedure…可选(选中后,会在拷贝结束后展示摘要,推荐使用,可以知道硬盘是否有坏道等),其他参数不要管(其他参数通常适用于严重坏道等情形)
选好后(一定要确认源和目标),按下OK按钮便开始镜像操作了(WINHEX第一次做此操作,当按下OK按钮时会弹出一个帮助框,意在提醒用户,此操作是有风险的。无碍,可关掉。之后不会再出现)
拷贝的过程如下图:
此过程完成后,镜像就完成了。目标文件即等同于源硬盘,之后可以使用WINHEX用逆向还原回原硬盘。
订阅:
评论 (Atom)