作者:张宇,北亚服务器数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
[数据恢复故障描述]
一台HP DL380 G4服务器,使用hp smart array控制器挂载了一台国产磁盘阵列,磁盘阵列由14块146G SCSI硬盘组成一组RAID5。
操作系统为LINUX,构建了NFS+FTP,作为公司内部文件服务器使用。
因机房搬迁时,管理员顺便打扫了一下机器,到新机房后接好线后,无法识别RAID,未做初始化。
[数据恢复分析]
HP smart array系列控制器源自康柏,RAID中的冗余采用双循环的校验方式。
此例中实际上是RAID信息丢失导致。
[数据恢复过程]
1、将SCSI硬盘柜直接接到不含RAID功能的SCSI扩展卡上。
2、在专用(windows2003改装后)修复平台上以单盘方式连接所有硬盘。
3、对所有硬盘以只读方式做完整镜像,同时镜像亦存储于带冗余保护的设备上。
4、从镜像中分析原RAID的双循环校验参数。
5、在虚拟RAID平台去掉早离线的盘,解释文件系统,已经可以导出数据了。
6、在客户原HP 服务器上连接盘阵,重新配置RAID。
7、通过网络dd、NFS、SAMBA、FTP、SSH等方式将数据传回新建好的磁盘阵列。
[数据恢复结果]
全部工作历时2 天,100%数据恢复成功。
2009年5月12日星期二
2009年5月9日星期六
分析案例:哪些操作导致IBM X225上无法成功恢复数据
作者:张宇,北亚服务器数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
[数据恢复故障描述]
新疆某政府机构,MS SQL SERVER服务器,硬件环境为:IBM X225,由4块73G SCSI硬盘组成RAID5,RAID中只划分了一个逻辑卷。操作系统为WINDOWS 2003。
A、之前未发现故障,直至服务器瘫痪,再查服务器时,发现有3块硬盘离线。
B、随便强制上线2块硬盘后,无法启动操作系统。
C、使用WINPE光盘启动操作系统后,可以看到数据,将备份好的ZIP数据库文件拷贝到移动硬盘上。
D、ZIP文件在另外的机器上测试,无法正确解压。
E、请对应维保公司帮助恢复。
F、其维保公司更换了一块新的RAID卡,直接重建成了一组RAID5。
G、客户认为ZIP文件大小、名称都正确,应该可以修好,所以直接先在RAID上重装了系统并正常工作,同时试图修复ZIP文件,尝试了1天后,没有结果。这时,向数据恢复公司寻求帮助。
[数据恢复结论]
与以往我叙述的数据恢复安全不同,我直接说数据恢复的最后结论:
因数据破坏严重,数据最终无法按客户要求恢复。
[案例分析]
针对上面的故障描述作如下分析:
故障描述A中,在使用RAID5做存储时,一定要及时维护RAID的正常状态,当RAID5一块硬盘掉线后,要及时备份数据到另外的存储体上,再及时REBUILD故障RAID。
故障描述B中,RAID5存在2块以上硬盘离线时,一定要可以随意选择硬盘上线,如果选择错了,有些情况下,一启动系统,整个RAID的状态就会改变,有可能会破坏重要数据。参考《RAID损坏后,我们该如何紧急应对?》
故障描述C中,用PE可以看到目录是因为目录区正常或部分正常,并不见得数据区正常,其实系统无法启动就意味着强制上线的操作是错误的,不应该继续下去。在PE里读到目录,实际上已经对文件系统进行了载入,已经破坏了正常文件系统的元数据区(只是有可能破坏的不影响要恢复的数据)
故障描述D中,ZIP文件无法解压即意味着RAID结构是错误的,实际上强制上线了2块盘(这时候有3块盘在线,仅有一块盘离线),但这3块盘里有一块是早就离线了的,所以合起来的数据是新鲜与陈旧的混合在一起的,虽然目录是正确的,但数据区是混乱的。这时候并未对这3块硬盘有全面的数据同步,基本还是可以完整恢复的。
故障描述E中,如果和维保公司签订协议中确定有数据恢复的项目,可以让其代为处理(但最好还是咨询几家专业的数据恢复公司,确定一下处理方式)。如果维保公司并无数据恢复的服务范围,最好直接选择数据恢复公司。大多数情况下,如果客户直接找维保公司,维保公司再找数据恢复公司,可能会导致费用增加(有时候大得可怕),同时对数据安全、数据恢复流程的规范方面无法直接控制。
故障描述F中,重建RAID5是此例中最致命的操作。IBM X225使用SERVER RAID SUPPORT CD重建RAID时,默认会清0所有数据。即使是其它服务器,重建RAID时一般也会重新同步校验,也会打乱原来的数据结构。但这个过程全部完成需要一段时间,如果没完成,可能剩余部分数据还有机会恢复。
故障描述G中,经过了一天,73G的RAID成员盘都已经同步完成了。数据完全毁掉了。
[数据恢复故障描述]
新疆某政府机构,MS SQL SERVER服务器,硬件环境为:IBM X225,由4块73G SCSI硬盘组成RAID5,RAID中只划分了一个逻辑卷。操作系统为WINDOWS 2003。
A、之前未发现故障,直至服务器瘫痪,再查服务器时,发现有3块硬盘离线。
B、随便强制上线2块硬盘后,无法启动操作系统。
C、使用WINPE光盘启动操作系统后,可以看到数据,将备份好的ZIP数据库文件拷贝到移动硬盘上。
D、ZIP文件在另外的机器上测试,无法正确解压。
E、请对应维保公司帮助恢复。
F、其维保公司更换了一块新的RAID卡,直接重建成了一组RAID5。
G、客户认为ZIP文件大小、名称都正确,应该可以修好,所以直接先在RAID上重装了系统并正常工作,同时试图修复ZIP文件,尝试了1天后,没有结果。这时,向数据恢复公司寻求帮助。
[数据恢复结论]
与以往我叙述的数据恢复安全不同,我直接说数据恢复的最后结论:
因数据破坏严重,数据最终无法按客户要求恢复。
[案例分析]
针对上面的故障描述作如下分析:
故障描述A中,在使用RAID5做存储时,一定要及时维护RAID的正常状态,当RAID5一块硬盘掉线后,要及时备份数据到另外的存储体上,再及时REBUILD故障RAID。
故障描述B中,RAID5存在2块以上硬盘离线时,一定要可以随意选择硬盘上线,如果选择错了,有些情况下,一启动系统,整个RAID的状态就会改变,有可能会破坏重要数据。参考《RAID损坏后,我们该如何紧急应对?》
故障描述C中,用PE可以看到目录是因为目录区正常或部分正常,并不见得数据区正常,其实系统无法启动就意味着强制上线的操作是错误的,不应该继续下去。在PE里读到目录,实际上已经对文件系统进行了载入,已经破坏了正常文件系统的元数据区(只是有可能破坏的不影响要恢复的数据)
故障描述D中,ZIP文件无法解压即意味着RAID结构是错误的,实际上强制上线了2块盘(这时候有3块盘在线,仅有一块盘离线),但这3块盘里有一块是早就离线了的,所以合起来的数据是新鲜与陈旧的混合在一起的,虽然目录是正确的,但数据区是混乱的。这时候并未对这3块硬盘有全面的数据同步,基本还是可以完整恢复的。
故障描述E中,如果和维保公司签订协议中确定有数据恢复的项目,可以让其代为处理(但最好还是咨询几家专业的数据恢复公司,确定一下处理方式)。如果维保公司并无数据恢复的服务范围,最好直接选择数据恢复公司。大多数情况下,如果客户直接找维保公司,维保公司再找数据恢复公司,可能会导致费用增加(有时候大得可怕),同时对数据安全、数据恢复流程的规范方面无法直接控制。
故障描述F中,重建RAID5是此例中最致命的操作。IBM X225使用SERVER RAID SUPPORT CD重建RAID时,默认会清0所有数据。即使是其它服务器,重建RAID时一般也会重新同步校验,也会打乱原来的数据结构。但这个过程全部完成需要一段时间,如果没完成,可能剩余部分数据还有机会恢复。
故障描述G中,经过了一天,73G的RAID成员盘都已经同步完成了。数据完全毁掉了。
2009年5月7日星期四
solaris ufs文件系统故障后恢复oracle数据库过程记录
作者:张宇,北亚服务器数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
[数据恢复故障描述]
1台sun sparc solaris系统,安装有oracle数据库,未知原因(有人为操作可能,但限于多方原因,无法得知),装载数据库的文件系统无法挂载,需要恢复oracle数据库。
[数据恢复过程]
首先对故障硬盘进行全面的完整备份,使用dd命令备份成nfs上的一个镜像文件。
对镜像文件进行完整分析,发现超级块存在故障。
抛开超级块,进行文件系统分析:
1、查找及分析根目录记录,找到。
2、根据根目录查找第一个节点区,找到,并以此分析块大小。
3、根据根据节点区特点,确定节点区大小。
4、查找第二个节点区,随之确定整个文件系统结构。
5、发现/lost+found文件夹里有大量以数字命名的目录及文件,通常就是由于fsck造成的。
6、按用户提供的目录信息从底层进入分析,找到数据库所在目录,再返回分析需恢复文件的节点区,发现节点区有错误,部分节点的索引位置清0。
通过文件系统的分析,无法全部重组数据库文件。
按sparc solaris上的oracle数据文件组织结构,对全盘进行分析处理。
根据重组好的数据库结构加上部分文件系统信息,成功导出所有数据库。
100%数据库恢复成功。
[后记]
1、此例的故障原因无从考评,但明显的,fsck是不应该执行的。当UFS文件系统出现故障后,如果条件允许,尽可能先对故障盘做备份操作,如果无法做备份,至少应该先以只读的方式测试fsck修复,或选择向导式修复,同时在发现导演时尽快停下操作。
2、UFS文件系统是个不太健壮的文件系统,推荐条件允许的话,使用Vxfs(ZFS本人没测试,不敢妄言,按理应该不错)
3、做好备份策略,也不要把备份放在同一存储体上。
[数据恢复故障描述]
1台sun sparc solaris系统,安装有oracle数据库,未知原因(有人为操作可能,但限于多方原因,无法得知),装载数据库的文件系统无法挂载,需要恢复oracle数据库。
[数据恢复过程]
首先对故障硬盘进行全面的完整备份,使用dd命令备份成nfs上的一个镜像文件。
对镜像文件进行完整分析,发现超级块存在故障。
抛开超级块,进行文件系统分析:
1、查找及分析根目录记录,找到。
2、根据根目录查找第一个节点区,找到,并以此分析块大小。
3、根据根据节点区特点,确定节点区大小。
4、查找第二个节点区,随之确定整个文件系统结构。
5、发现/lost+found文件夹里有大量以数字命名的目录及文件,通常就是由于fsck造成的。
6、按用户提供的目录信息从底层进入分析,找到数据库所在目录,再返回分析需恢复文件的节点区,发现节点区有错误,部分节点的索引位置清0。
通过文件系统的分析,无法全部重组数据库文件。
按sparc solaris上的oracle数据文件组织结构,对全盘进行分析处理。
根据重组好的数据库结构加上部分文件系统信息,成功导出所有数据库。
100%数据库恢复成功。
[后记]
1、此例的故障原因无从考评,但明显的,fsck是不应该执行的。当UFS文件系统出现故障后,如果条件允许,尽可能先对故障盘做备份操作,如果无法做备份,至少应该先以只读的方式测试fsck修复,或选择向导式修复,同时在发现导演时尽快停下操作。
2、UFS文件系统是个不太健壮的文件系统,推荐条件允许的话,使用Vxfs(ZFS本人没测试,不敢妄言,按理应该不错)
3、做好备份策略,也不要把备份放在同一存储体上。
2009年5月5日星期二
硬盘坏道引起的LINUX ext3故障的数据恢复过程记录
作者:张宇,北亚服务器数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
[数据恢复故障描述]
一台linux网站服务器,管理约50个左右网站,使用一块SATA 160GB硬盘。正常使用中突然宕机,尝试再次启动失败,将硬盘拆下检测时发现存在约100个坏扇区。
某数据恢复公司修复坏道后,尝试了约3天时间,未恢复成功。
[数据恢复过程]
接到盘后,首先通过PC3K with DE对故障盘进行完整镜像操作,在镜像中进行数据分析。
整块硬盘由两个分区组成:100M的boot分区及剩余空间的/分区(通过LVM管理),文件系统均为EXT3。
根分区超级块正常,根据超级块查看第一块组描述表正常,但节点区全为0。
根据块组描述表分析其他块组,发现前27个块组全部为0,但块组前后的数据区明显有用户数据存在。
中间块组区元数据正常(描述表、节点、BITMAP等)
最后部分块组的元数据区全部为0。
试图查找根目录,找到。
以根目录为线索,恢复根目录节点区,成功。
以生成的根目录节点区与根目录记录生成文件系统树,成功后已经可以看到大量数据,文件系统结构正常。但部分文件或文件夹的节点为0,通过节点跟踪,发现节点区位于文件系统前部分及后部分。
试图恢复节点区为0的文件与文件夹,文件夹大部分恢复成功,但文件大部分无法恢复。
试图恢复用户曾做过的.TAR.GZ备份包,恢复成功,但打开时提示出错,中间数据被破坏,只能有限导出部分网站。
最终评估约70%的数据恢复成功。
[数据恢复故障原因推断]
数据恢复的故障原因往往无法明确得知,此例中仅仅推断如下:
1、出现坏道后,用户可能试图进行自动或手工的fsck操作,导致进一步的灾难。
2、以部分块组全为0看,有可能做过未完成的mkfs。
3、送修的数据恢复公司并不专业,有破坏数据的可能性。
[给用户的建议]
1、重要的数据一定不要用单盘做存储环境,目前构架一套简单的RAID并不需要很大的投入。
2、一定要做好备份工作,最起码,备份包不要放到同一存储体上,退而求其次,也一定不要放到同一分区下。
3、硬盘出现故障后,一定不要反复尝试处理,应尽快做完整备份操作。
4、尽可能选择专业一点的数据恢复公司进行处理,不专业的公司或个人公司部分做事相当无耻,无意或有意的会对故障盘进行破坏(有意的目的是为了提高报价要挟或维持名声)。
[数据恢复故障描述]
一台linux网站服务器,管理约50个左右网站,使用一块SATA 160GB硬盘。正常使用中突然宕机,尝试再次启动失败,将硬盘拆下检测时发现存在约100个坏扇区。
某数据恢复公司修复坏道后,尝试了约3天时间,未恢复成功。
[数据恢复过程]
接到盘后,首先通过PC3K with DE对故障盘进行完整镜像操作,在镜像中进行数据分析。
整块硬盘由两个分区组成:100M的boot分区及剩余空间的/分区(通过LVM管理),文件系统均为EXT3。
根分区超级块正常,根据超级块查看第一块组描述表正常,但节点区全为0。
根据块组描述表分析其他块组,发现前27个块组全部为0,但块组前后的数据区明显有用户数据存在。
中间块组区元数据正常(描述表、节点、BITMAP等)
最后部分块组的元数据区全部为0。
试图查找根目录,找到。
以根目录为线索,恢复根目录节点区,成功。
以生成的根目录节点区与根目录记录生成文件系统树,成功后已经可以看到大量数据,文件系统结构正常。但部分文件或文件夹的节点为0,通过节点跟踪,发现节点区位于文件系统前部分及后部分。
试图恢复节点区为0的文件与文件夹,文件夹大部分恢复成功,但文件大部分无法恢复。
试图恢复用户曾做过的.TAR.GZ备份包,恢复成功,但打开时提示出错,中间数据被破坏,只能有限导出部分网站。
最终评估约70%的数据恢复成功。
[数据恢复故障原因推断]
数据恢复的故障原因往往无法明确得知,此例中仅仅推断如下:
1、出现坏道后,用户可能试图进行自动或手工的fsck操作,导致进一步的灾难。
2、以部分块组全为0看,有可能做过未完成的mkfs。
3、送修的数据恢复公司并不专业,有破坏数据的可能性。
[给用户的建议]
1、重要的数据一定不要用单盘做存储环境,目前构架一套简单的RAID并不需要很大的投入。
2、一定要做好备份工作,最起码,备份包不要放到同一存储体上,退而求其次,也一定不要放到同一分区下。
3、硬盘出现故障后,一定不要反复尝试处理,应尽快做完整备份操作。
4、尽可能选择专业一点的数据恢复公司进行处理,不专业的公司或个人公司部分做事相当无耻,无意或有意的会对故障盘进行破坏(有意的目的是为了提高报价要挟或维持名声)。
2009年4月30日星期四
某网站服务器4*136G RAID数据恢复过程
作者:张宇,北亚服务器数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
[数据恢复故障描述]
某网站服务器,品牌为组装,使用tyan(泰安)主板,AMD CPU*4,由4块68针SCSI硬盘 RAID0组成存储体系(听说2007年花了5万元买的,而且采用RAID0,这个专业程度真是不敢恭维)。
操作系统为LINUX,重要数据为MYSQL数据库及网站数据文件。
由于电源损坏(5万元买的设备竟然没有冗余电源),重新更换了电源测试,硬件销售商竟然怕数据损坏,留下RAID卡把硬盘全部拔掉启系统(真是无语了),再次连接启动系统时,RAID信息已经损坏。
之后做了一些操作。(此部分操作可能涉及责任问题,无法询问清楚)
最后的现象是:启动操作系统时提示无效的引导记录。
需要恢复服务器数据,同时重新激活修复服务器系统。
[数据恢复分析]
更换电源后,因硬盘全部拔掉,但RAID卡依然留在主机系统里,这样,加电检测RAID控制器时,就会认为所有硬盘已经存在故障,导致RAID逻辑卷下线。
重新加电后,虽然硬盘可能还是好的,但RAID控制器作为安全考虑,不会试图重新加载所有硬盘,重建RAID卷。这时候如果有一些正确有方式还有可能恢复数据(但数据重要的话不建议,可以参考我的其它文章),但估计用户采用的错误的方式进行了重建等操作,导致所有数据不可用。
RAID0本身不会涉及同步操作,故而除非重建时清0数据,其余情况应该不会有致命性损坏,但需要分析原RAID的结构,并进行虚拟重组。
[数据恢复过程]
1、对所有硬盘按单盘方式完整镜像。
2、在镜像中分析原RAID的结构参数。
3、搭建虚拟RAID环境,组织RAID逻辑卷。
4、为保证完整性,将数据打包为TAR.GZ。
5、重新配置RAID,安装系统,将恢复后的数据迁移回原系统。
[数据恢复故障描述]
某网站服务器,品牌为组装,使用tyan(泰安)主板,AMD CPU*4,由4块68针SCSI硬盘 RAID0组成存储体系(听说2007年花了5万元买的,而且采用RAID0,这个专业程度真是不敢恭维)。
操作系统为LINUX,重要数据为MYSQL数据库及网站数据文件。
由于电源损坏(5万元买的设备竟然没有冗余电源),重新更换了电源测试,硬件销售商竟然怕数据损坏,留下RAID卡把硬盘全部拔掉启系统(真是无语了),再次连接启动系统时,RAID信息已经损坏。
之后做了一些操作。(此部分操作可能涉及责任问题,无法询问清楚)
最后的现象是:启动操作系统时提示无效的引导记录。
需要恢复服务器数据,同时重新激活修复服务器系统。
[数据恢复分析]
更换电源后,因硬盘全部拔掉,但RAID卡依然留在主机系统里,这样,加电检测RAID控制器时,就会认为所有硬盘已经存在故障,导致RAID逻辑卷下线。
重新加电后,虽然硬盘可能还是好的,但RAID控制器作为安全考虑,不会试图重新加载所有硬盘,重建RAID卷。这时候如果有一些正确有方式还有可能恢复数据(但数据重要的话不建议,可以参考我的其它文章),但估计用户采用的错误的方式进行了重建等操作,导致所有数据不可用。
RAID0本身不会涉及同步操作,故而除非重建时清0数据,其余情况应该不会有致命性损坏,但需要分析原RAID的结构,并进行虚拟重组。
[数据恢复过程]
1、对所有硬盘按单盘方式完整镜像。
2、在镜像中分析原RAID的结构参数。
3、搭建虚拟RAID环境,组织RAID逻辑卷。
4、为保证完整性,将数据打包为TAR.GZ。
5、重新配置RAID,安装系统,将恢复后的数据迁移回原系统。
2009年4月28日星期二
找回在线写博因断网丢失的已编数据
在线写博偶尔会遇到这样的问题:花了好长时间码了好多字,一按提交,发现网断了,又没有保存在草稿里,如果不想重新写(会很痛苦的),可以参考一下以下办法。
恢复这些数据的原理是:当我们按下提交按钮时,浏览器会生成POST表单数据,以HTTP(或HTTPS)协议进行发送。这些POST表单数据会首先读入内存,再进行发送,读入内存的过程与网络是否畅通无关,所以在断网后,实际的POST数据还存在于内存当中,可以从内存中取回这些数据(当然要很快,因为内存空间已经释放,如果有别的进程申请内存空间,就有可能重写数据了)
用到一个工具,WINHEX。
出现问题后,尽可能保持当前状态,千万不要关闭浏览器窗口。只打开WINHEX->TOOLS->OPEN RAM
然后在弹出的窗口,选择我们编辑文件所用的浏览器进程(如果开了多个浏览器进程,可以依次尝试),再选中"Entrie Memory",单击"OK"
在打开的编辑窗口,按下CTRL+A,在编辑区点击右键,EDIT->COPY BLOCK->INTO NEW FILE。选择一下目标文件,导出。这一过程的目的是尽快地把内存的东西保存在磁盘上,就不用担心有变化了。
但如果开的浏览器进程很多,就最好不要先保存了,可以直接查找,以尽可能少得用到内存,避免因WINHEX操作太多重写需恢复数据区。
可以直接在打开的编辑窗口或在保存下来的文件中查特征字符串,可以是我们之前编辑内容中的一段特有数字、英文或中文(涉及字符集问题,不建议查中文),也可以是博客页面的一些POST特征。查找的内容出现的次数越少越好。
以本文为例,我可以查找“INTO NEW FILE”这个字符串:
查到后。将前后一片文本保存为一个文本文件,用记事本打开。
找到已经编辑的数据,复制。
在博客上重写一文章,标题、TAG等重写一下或者从恢复出来的文本中提取,内容区切换到源码状态,把复制的内容粘贴下来。
再切换过来看看,是不是以前编辑的数据又回来了?
注意:为了尽可能避免内存变更,如果之前没有安装过WINHEX,最好使用绿色版的WINHEX。
2009年4月27日星期一
linux ext3下删除mysql数据库的数据恢复案例
作者:张宇,北亚MYSQL数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
[数据恢复故障描述]
一台重要的MYSQL数据库服务器,146GB*2,RAID1,约130GB DATA卷,存储了大约200~300个数据库。平时管理员对每个数据库dump出以后,直接压缩成.gz包,再将所有重要的.gz 包合起来压缩成一个总的.tar.gz包,这些文件每日产生一次,覆盖原来的备份。数据文件及备份文件全部存储于data卷上。
一次系统维护中,管理员不小心将data卷下的所有文件全部rm,删除后,马上停止系统,再未做其它操作,但删除时仍有大量终端在访问此服务器。
要求恢复mysql数据库文件,即myd、frm、myi(可重建)文件,或每个数据库的.gz包,或所有重要数据库总的.tar.gz备份包。
[数据恢复分析]
ext3下的数据删除,理论上,会清除inode中除节点类型、日期外的其他属性,诸如文件大小、数据存储地址等属性会全部清0,同时目录表中会以目录条目长度的方式屏蔽掉已删除文件,但会保留节点编号,最后会改变BITMAP中的空间占用标志。
即使是目录表中存在删除文件的节点编号,但因节点内容已经没有需要的东西,与数据区也是脱钩的。
从数据角度,大多数文件类型都会有特定的文件头标志,按头标志是有可能找到删除文件的起始位置的,但EXT3以块组为单位进行存储,同时数据与索引是混合存储于数据区的,所以数据连续存储的可能性非常之小,这样,按文件格式进行处理也是很困难的。
唯一的算法是结合上述几个特征,加上对日志的分析,加上对存储过程的模拟分析,尽可能地逼近真实存储结构。
[数据恢复过程]
1、对故障卷做完整备份。
2、对总.tar.gz进行恢复分析,但恢复出来的文件解压到50%左右会报错,后续文件列表也无法列出。经分析,最大的原因是删除时仍有数据写入破坏文件导致。
3、对分包的.gz文件进行恢复分析,大多数恢复成功。
4、对于未恢复成功的.gz数据库。直接恢复其myd\frm数据文件,所有数据恢复成功。
[其他]
1、LINUX EXT3数据删除后应尽快断掉文件系统IO,通常umount文件系统即可。
2、对故障卷做dd备份,确保数据恢复过程不会导致更严重的故障。
[数据恢复故障描述]
一台重要的MYSQL数据库服务器,146GB*2,RAID1,约130GB DATA卷,存储了大约200~300个数据库。平时管理员对每个数据库dump出以后,直接压缩成.gz包,再将所有重要的.gz 包合起来压缩成一个总的.tar.gz包,这些文件每日产生一次,覆盖原来的备份。数据文件及备份文件全部存储于data卷上。
一次系统维护中,管理员不小心将data卷下的所有文件全部rm,删除后,马上停止系统,再未做其它操作,但删除时仍有大量终端在访问此服务器。
要求恢复mysql数据库文件,即myd、frm、myi(可重建)文件,或每个数据库的.gz包,或所有重要数据库总的.tar.gz备份包。
[数据恢复分析]
ext3下的数据删除,理论上,会清除inode中除节点类型、日期外的其他属性,诸如文件大小、数据存储地址等属性会全部清0,同时目录表中会以目录条目长度的方式屏蔽掉已删除文件,但会保留节点编号,最后会改变BITMAP中的空间占用标志。
即使是目录表中存在删除文件的节点编号,但因节点内容已经没有需要的东西,与数据区也是脱钩的。
从数据角度,大多数文件类型都会有特定的文件头标志,按头标志是有可能找到删除文件的起始位置的,但EXT3以块组为单位进行存储,同时数据与索引是混合存储于数据区的,所以数据连续存储的可能性非常之小,这样,按文件格式进行处理也是很困难的。
唯一的算法是结合上述几个特征,加上对日志的分析,加上对存储过程的模拟分析,尽可能地逼近真实存储结构。
[数据恢复过程]
1、对故障卷做完整备份。
2、对总.tar.gz进行恢复分析,但恢复出来的文件解压到50%左右会报错,后续文件列表也无法列出。经分析,最大的原因是删除时仍有数据写入破坏文件导致。
3、对分包的.gz文件进行恢复分析,大多数恢复成功。
4、对于未恢复成功的.gz数据库。直接恢复其myd\frm数据文件,所有数据恢复成功。
[其他]
1、LINUX EXT3数据删除后应尽快断掉文件系统IO,通常umount文件系统即可。
2、对故障卷做dd备份,确保数据恢复过程不会导致更严重的故障。
2009年4月23日星期四
ESX SERVER VMFS STORAGE被破坏后的数据恢复
作者:张宇,北亚VMWARE数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
对前几天接手的一个VMWARE ESX SERVER的数据恢复案子进行一下总结
[数据恢复故障描述]
中石化某省分公司,信息管理平台,几台ESX SERVER共享一台IBM DS4100存储,大约有40~50组虚拟机,占用1.8TB空间,数据重要。
正常工作中,vc里报告虚拟磁盘丢失,ssh到ESX中执行fdisk -l查看磁盘,发现storage已经没有分区表了。重启所有设备后,ESX SERVER均无法连接到DS4100所在的STORAGE。
仔细询问当时的管理员,他们提到一点,曾经在这个存储网络里连接过一台windows 2003服务器,具体情况不详。
[数据恢复分析]
很自然地想到了,可能是那台windows 2003因对storage的独享操作导致了整个vmfs卷损坏。
以整个存储做分析发现:
1、分区表清0,有55aa有效结束标志,有硬盘ID标志。
2、简单从前向后查看,发现一个NTFS卷,但似乎并未写数据进去,像一个刚刚格式化的卷,对这个NTFS卷的BITMAP做分析,得知大小约为1.8T(全部空间),前部占用部分空间,3G左右位置占用部分空间,0.9T附近占用部分空间,但总占用空间不超过100M。
3、针对VMFS卷进行分析,发现在原1.8TB的磁盘里有2组VMFS分区,第2组是对第一组的extend,第一组约1.5T,第二组约300GB,因NTFS分区并未写数据到第二个VMFS分区里(最后一个扇区的DBR备份没有覆盖有用数据),所以重点在于第一个VMFS分区。
4、分析第一组VMFS,卷头结构丢失,一级索引、二级索引均存在,NTFS覆盖的数据区正好是某组虚拟机的临时内存镜像,损坏也无妨。
[数据恢复过程]
1、对整个STORAGE进行镜像备份。
2、分析后,连接两个VMFS分区,直接按照VMFS分析组织方式提取所有VMDK及配置文件。
3、通过nfs直接迁移回ESX SERVER。
另:本例中因已对故障存储做了安全备份,修复中同时直接重建第一组VMFS卷头,索引列表、分区表等信息,直接附加在ESX SERVER环境,算是第二个方案。
[数据恢复结果]
花费2天时间(不计之后的迁移时间),全部数据恢复成功
[其他]
1、本例中依然是因为光纤环境互斥不当导致的问题,实际上,应该是这个卷在WINDOWS系统做了重新分区,并格式化成了NTFS,之后又对分区做了删除操作。因ESX VMFS的互斥不依赖于硬件,只依赖于操作系统驱动层,所以在其他服务器接入存储网络时一定要小心,尽量考虑好存储分配权限。
2、ESX因便捷的信息集中管理,真正使用中往往数据特别重要,一定要做好备份工作,并考虑损坏时迁移的方便性。
对前几天接手的一个VMWARE ESX SERVER的数据恢复案子进行一下总结
[数据恢复故障描述]
中石化某省分公司,信息管理平台,几台ESX SERVER共享一台IBM DS4100存储,大约有40~50组虚拟机,占用1.8TB空间,数据重要。
正常工作中,vc里报告虚拟磁盘丢失,ssh到ESX中执行fdisk -l查看磁盘,发现storage已经没有分区表了。重启所有设备后,ESX SERVER均无法连接到DS4100所在的STORAGE。
仔细询问当时的管理员,他们提到一点,曾经在这个存储网络里连接过一台windows 2003服务器,具体情况不详。
[数据恢复分析]
很自然地想到了,可能是那台windows 2003因对storage的独享操作导致了整个vmfs卷损坏。
以整个存储做分析发现:
1、分区表清0,有55aa有效结束标志,有硬盘ID标志。
2、简单从前向后查看,发现一个NTFS卷,但似乎并未写数据进去,像一个刚刚格式化的卷,对这个NTFS卷的BITMAP做分析,得知大小约为1.8T(全部空间),前部占用部分空间,3G左右位置占用部分空间,0.9T附近占用部分空间,但总占用空间不超过100M。
3、针对VMFS卷进行分析,发现在原1.8TB的磁盘里有2组VMFS分区,第2组是对第一组的extend,第一组约1.5T,第二组约300GB,因NTFS分区并未写数据到第二个VMFS分区里(最后一个扇区的DBR备份没有覆盖有用数据),所以重点在于第一个VMFS分区。
4、分析第一组VMFS,卷头结构丢失,一级索引、二级索引均存在,NTFS覆盖的数据区正好是某组虚拟机的临时内存镜像,损坏也无妨。
[数据恢复过程]
1、对整个STORAGE进行镜像备份。
2、分析后,连接两个VMFS分区,直接按照VMFS分析组织方式提取所有VMDK及配置文件。
3、通过nfs直接迁移回ESX SERVER。
另:本例中因已对故障存储做了安全备份,修复中同时直接重建第一组VMFS卷头,索引列表、分区表等信息,直接附加在ESX SERVER环境,算是第二个方案。
[数据恢复结果]
花费2天时间(不计之后的迁移时间),全部数据恢复成功
[其他]
1、本例中依然是因为光纤环境互斥不当导致的问题,实际上,应该是这个卷在WINDOWS系统做了重新分区,并格式化成了NTFS,之后又对分区做了删除操作。因ESX VMFS的互斥不依赖于硬件,只依赖于操作系统驱动层,所以在其他服务器接入存储网络时一定要小心,尽量考虑好存储分配权限。
2、ESX因便捷的信息集中管理,真正使用中往往数据特别重要,一定要做好备份工作,并考虑损坏时迁移的方便性。
2009年4月22日星期三
SUN平台,光纤共享存储互斥失败导致的数据灾难恢复
作者:张宇,北亚数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
[数据恢复故障描述]
两台SPARC SOLARIS系统通过光纤交换机共享同一存储,本意是作为CLUSTER使用,但配置不当,两台SERVER并未很好地对存储互斥,设计意图为:平时A服务器正常工作,当A服务器宕掉后,关掉A,开启B接管服务。
偶然的机会,一位管理人员开启B服务器,查到B服务器连接了一组很大的磁盘(实际上就是那个共享存储),因B服务器一直闲置未用,管理员以为磁盘也是闲置的,于是将整个磁盘的某个分区做了newfs。
A服务器很快报警并宕机,重启A服务器后,发现所有的文件系统均无法mount,执行fsck后,大多数分区的数据均修复成功,只有在B机做过newfs的文件系统结果不理想,根目录下只有一个lost+found文件夹,里面有大量数字标号的文件。
故障文件系统存储了两组ORACLE实例,原结构为UFS,约有200~400个数据文件需要恢复。
[数据恢复分析]
光纤设备的共享冲突案例很多,起缘于光纤交换的灵活性。此例中,A机与B机同时对UFS这个单机文件系统进行访问是很糟糕的,两台SERVER都以想当然的独享方式对存储进行管理,A机正常管理的文件系统其实底层上已经被B机做了文件系统初始化,A机从缓冲区写入文件系统的数据也会破坏B机初始化的结果。
B机newfs实际上直接会作用于原先的文件系统之上,但此例与单纯的newfs会有些不同,在A机宕机之前,会有一小部分数据(包括元数据)回写回文件系统。newfs如果结构与之前的相同,数据区是不会被破坏的,同时如果有一小部分元数据存在,部分数据恢复的可能性还是存在的。
UFS是传统的UNIX文件系统,以块组切割,每块组分配若干固定的inode区。文件系统newfs时,如果结构与之前的相同,文件系统最重要的inode区便会全部初始化,之前的无法保留,inode管理着所有文件的重要属性,所以单纯从文件系统角度考虑,数据恢复的难度很大。
好在oracle数据文件的结构性很强,同时UFS文件系统还是有一定的存储规律性,可以通过对oracle数据文件的结构重组,直接将数据文件、控制文件、日志等恢复出来。同时oracle数据文件本身会有表名称描述,也可以反向推断原来的磁盘文件名。
[数据恢复过程]
对故障的文件系统做dd备份。
针对整个镜像文件做完全的oracle数据结构分析、重组。
对部分结构太乱,无法重组的文件,参考ufs文件系统结构特征进行辅助分析。
利用恢复的数据文件、控制文件在oracle平台恢复数据库。
[数据恢复结论]
所有数据库完全恢复。
[后记]
fsck是很致命的操作,在fsck之前最好做好备份(dd即可)。
光纤存储的不互斥是非常多的数据灾难原因,方案应谨慎部署与实施。
[数据恢复故障描述]
两台SPARC SOLARIS系统通过光纤交换机共享同一存储,本意是作为CLUSTER使用,但配置不当,两台SERVER并未很好地对存储互斥,设计意图为:平时A服务器正常工作,当A服务器宕掉后,关掉A,开启B接管服务。
偶然的机会,一位管理人员开启B服务器,查到B服务器连接了一组很大的磁盘(实际上就是那个共享存储),因B服务器一直闲置未用,管理员以为磁盘也是闲置的,于是将整个磁盘的某个分区做了newfs。
A服务器很快报警并宕机,重启A服务器后,发现所有的文件系统均无法mount,执行fsck后,大多数分区的数据均修复成功,只有在B机做过newfs的文件系统结果不理想,根目录下只有一个lost+found文件夹,里面有大量数字标号的文件。
故障文件系统存储了两组ORACLE实例,原结构为UFS,约有200~400个数据文件需要恢复。
[数据恢复分析]
光纤设备的共享冲突案例很多,起缘于光纤交换的灵活性。此例中,A机与B机同时对UFS这个单机文件系统进行访问是很糟糕的,两台SERVER都以想当然的独享方式对存储进行管理,A机正常管理的文件系统其实底层上已经被B机做了文件系统初始化,A机从缓冲区写入文件系统的数据也会破坏B机初始化的结果。
B机newfs实际上直接会作用于原先的文件系统之上,但此例与单纯的newfs会有些不同,在A机宕机之前,会有一小部分数据(包括元数据)回写回文件系统。newfs如果结构与之前的相同,数据区是不会被破坏的,同时如果有一小部分元数据存在,部分数据恢复的可能性还是存在的。
UFS是传统的UNIX文件系统,以块组切割,每块组分配若干固定的inode区。文件系统newfs时,如果结构与之前的相同,文件系统最重要的inode区便会全部初始化,之前的无法保留,inode管理着所有文件的重要属性,所以单纯从文件系统角度考虑,数据恢复的难度很大。
好在oracle数据文件的结构性很强,同时UFS文件系统还是有一定的存储规律性,可以通过对oracle数据文件的结构重组,直接将数据文件、控制文件、日志等恢复出来。同时oracle数据文件本身会有表名称描述,也可以反向推断原来的磁盘文件名。
[数据恢复过程]
对故障的文件系统做dd备份。
针对整个镜像文件做完全的oracle数据结构分析、重组。
对部分结构太乱,无法重组的文件,参考ufs文件系统结构特征进行辅助分析。
利用恢复的数据文件、控制文件在oracle平台恢复数据库。
[数据恢复结论]
所有数据库完全恢复。
[后记]
fsck是很致命的操作,在fsck之前最好做好备份(dd即可)。
光纤存储的不互斥是非常多的数据灾难原因,方案应谨慎部署与实施。
2009年4月19日星期日
在esx server VI里导入其它虚拟机
作者:张宇,北亚数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
如果重新安装了esx server,或者需要迁移其它地方的虚拟机到另一个ESX SERVER上,往往需要做的步骤是:
1、导入vmfs storage
2、导入虚拟机配置文件
导入vmfs storage的方法见:《在esx server上导入其它vmfs storage》
导入虚拟机配置文件的方法如下:
VI->configuration->storage->选中其中一个STORAGE->Browse datastore...
然后找到原先存在的虚拟机目录,在其中的vmx文件上点右键,选择"add to Inventory",按照向导处理即可。
如果重新安装了esx server,或者需要迁移其它地方的虚拟机到另一个ESX SERVER上,往往需要做的步骤是:
1、导入vmfs storage
2、导入虚拟机配置文件
导入vmfs storage的方法见:《在esx server上导入其它vmfs storage》
导入虚拟机配置文件的方法如下:
VI->configuration->storage->选中其中一个STORAGE->Browse datastore...
然后找到原先存在的虚拟机目录,在其中的vmx文件上点右键,选择"add to Inventory",按照向导处理即可。
2009年4月17日星期五
在esx server上导入其它vmfs storage
作者:张宇,北亚数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
ESX SERVER推荐使用VMFS文件系统作为虚拟机存储使用,当然好处是很多了,但VMFS仅仅是VMWARE公司专用的一种CLUSTER类文件系统,所以对VMFS文件系统的读取会稍稍麻烦一点。
当重新安装ESX SERVER,或者从其它地方迁移过来的一个VMFS STORAGE,就需要对这个新的VMFS STORAGE重新激活。
利用VI的方法:
首先在Advanced Setting--->LVM里将LVM.DisallowSnapshotLun开关设置为1,将LVM.EnableResignaturing开关设置为1,然后在Advanced Setting--->Storage Adapters--->Rescan。即可在Storage里看到。
利用命令行方式:
用SSH登录后,执行:
echo 1>/proc/vmware/config/LVM/EnableResignature echo 1>/proc/vmware/config/LVM/DisallowSnapshotLun
然后再执行:
vmkfstools -s
ESX SERVER推荐使用VMFS文件系统作为虚拟机存储使用,当然好处是很多了,但VMFS仅仅是VMWARE公司专用的一种CLUSTER类文件系统,所以对VMFS文件系统的读取会稍稍麻烦一点。
当重新安装ESX SERVER,或者从其它地方迁移过来的一个VMFS STORAGE,就需要对这个新的VMFS STORAGE重新激活。
利用VI的方法:
首先在Advanced Setting--->LVM里将LVM.DisallowSnapshotLun开关设置为1,将LVM.EnableResignaturing开关设置为1,然后在Advanced Setting--->Storage Adapters--->Rescan。即可在Storage里看到。
利用命令行方式:
用SSH登录后,执行:
echo 1>/proc/vmware/config/LVM/EnableResignature echo 1>/proc/vmware/config/LVM/DisallowSnapshotLun
然后再执行:
vmkfstools -s
2009年4月16日星期四
dd for windows详细说明
作者:张宇,北亚数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
dd for windows下载地址:http://www.chrysocome.net/dd(或从网上找)
dd是一个在LINUX、UNIX下非常重要的磁盘镜像工具,现在终于有了WINDOWS版本。虽然dd是基于命令行方式的应用程序,操作不便捷,但命令行的应用程序优点却也是图形程序不具备的,比如,希望对硬盘做批量镜像,如果用图形界面程序处理,只能等待做完一个再做一个,而用命令行的dd,就可以下一个批处理命令来批量执行了。
dd for windows的执行格式为:
dd [bs=SIZE[SUFFIX]] [count=BLOCKS[SUFFIX]] if=FILE of=FILE [seek=BLOCKS[SUFFIX]] [skip=BLOCKS[SUFFIX]] [--size] [--list] [--progress]
其中:
bs代表镜像时缓冲块的大小,通常建议设得大一点,比如1M、10M等(单位可用:c表示字节,w表示双字,d表示4字节,q表示8字节,k表示1024字节,M表示k*k字节,G表示k*k*k字节),默认为512字节
count表示镜像的块总数
if与of分别表示镜像源与镜像目标的设备文件路径
seek表示在备份时对of后面的部分也就是目标文件跳过多少块再开始写
skip表示备份时对if后面的部分也就是原文件跳过多少块再开始备份
--size表示对源设备的读取进行大小校验,以避免IO死循环等错误
--list表示列出可利用的磁盘(分区)设备文件,在if与of中指定的这是这些设备名称
--progress表示显示镜像进度
示例:
对软盘做镜像:
dd if=\\.\a: of=c:\temp\disk1.img bs=1440k
对硬盘做镜像
先用 dd --list,查到要镜像的设备路径为:\\?\device\harddisk1\dr5
然后执行:
E:\>dd if=\\?\device\harddisk1\dr5 of=r:\aa.img --sizerawwrite dd for windows version 0.5.Written by John Newbigin <jn@it.swin.edu.au>This program is covered by the GPL. See copying.txt for details250880+0 records in250880+0 records out
dd for windows下载地址:http://www.chrysocome.net/dd(或从网上找)
dd是一个在LINUX、UNIX下非常重要的磁盘镜像工具,现在终于有了WINDOWS版本。虽然dd是基于命令行方式的应用程序,操作不便捷,但命令行的应用程序优点却也是图形程序不具备的,比如,希望对硬盘做批量镜像,如果用图形界面程序处理,只能等待做完一个再做一个,而用命令行的dd,就可以下一个批处理命令来批量执行了。
dd for windows的执行格式为:
dd [bs=SIZE[SUFFIX]] [count=BLOCKS[SUFFIX]] if=FILE of=FILE [seek=BLOCKS[SUFFIX]] [skip=BLOCKS[SUFFIX]] [--size] [--list] [--progress]
其中:
bs代表镜像时缓冲块的大小,通常建议设得大一点,比如1M、10M等(单位可用:c表示字节,w表示双字,d表示4字节,q表示8字节,k表示1024字节,M表示k*k字节,G表示k*k*k字节),默认为512字节
count表示镜像的块总数
if与of分别表示镜像源与镜像目标的设备文件路径
seek表示在备份时对of后面的部分也就是目标文件跳过多少块再开始写
skip表示备份时对if后面的部分也就是原文件跳过多少块再开始备份
--size表示对源设备的读取进行大小校验,以避免IO死循环等错误
--list表示列出可利用的磁盘(分区)设备文件,在if与of中指定的这是这些设备名称
--progress表示显示镜像进度
示例:
对软盘做镜像:
dd if=\\.\a: of=c:\temp\disk1.img bs=1440k
对硬盘做镜像
先用 dd --list,查到要镜像的设备路径为:\\?\device\harddisk1\dr5
然后执行:
E:\>dd if=\\?\device\harddisk1\dr5 of=r:\aa.img --sizerawwrite dd for windows version 0.5.Written by John Newbigin <jn@it.swin.edu.au>This program is covered by the GPL. See copying.txt for details250880+0 records in250880+0 records out
2009年4月8日星期三
IBM DS3200数据恢复手记,12块300GB sas raid5
作者:张宇,北亚数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
某医院DCOM成像系统存储,IBM DS3200,12块300GB SAS硬盘组成,RAID5,无 hot-spare,划分成两组logical driver,容量分别为2TB与1.3TB,存储数据量约1TB。
因集群系统(双机)故障,切换时RAID信息丢失,IBM工程师激活不成功,需恢复数据。
大致流程如下:
1、关闭DS3200电源,将所有12块硬盘全部拆下,标好号(以确定操作是可逆的,对于数据恢复而言不必需)。之后不再开启DS3200电源。
2、按《RAID损坏后 对数据的完整备份》中的备份方式,对源盘做完整备份,备份完成后交回原盘,确保恢复过程完全无风险。备份时选择具备RAID5的目标存储体,以确保备份数据安全,避免因数据故障导致的恢复周期延长,我们的目标存储为DELL MD3000(12*1TB RAID5)。如果数据特别急,可以在征求客户同意的前提下,直接以只读的方式恢复数据到另外的存储介质,恢复方式见下面。
3、对做好的12块硬盘镜像进行逻辑分析,重点在于:盘充(这12块硬盘在原控制器上的组合顺序)、块大小(即组成原RAID的条带大小)、校验方式(校验的循环走向、同一条带的数据排序方式等)、logical driver在每块单盘上的起始位置、是否有数据满后(是否需要剔除陈旧盘)。 4、按照分析好的RAID参数,搭建虚拟RAID控制器(软件模拟),通过虚拟RAID控制器对单盘(或镜像)进行组织,形成虚拟卷(只读)。
5、对虚拟卷做文件系统解释,导出数据(只读),即完成所有数据恢复过程。
本例中,镜像花费约10小时,分析结构花费约半小时,恢复数据花费约10小时
某医院DCOM成像系统存储,IBM DS3200,12块300GB SAS硬盘组成,RAID5,无 hot-spare,划分成两组logical driver,容量分别为2TB与1.3TB,存储数据量约1TB。
因集群系统(双机)故障,切换时RAID信息丢失,IBM工程师激活不成功,需恢复数据。
大致流程如下:
1、关闭DS3200电源,将所有12块硬盘全部拆下,标好号(以确定操作是可逆的,对于数据恢复而言不必需)。之后不再开启DS3200电源。
2、按《RAID损坏后 对数据的完整备份》中的备份方式,对源盘做完整备份,备份完成后交回原盘,确保恢复过程完全无风险。备份时选择具备RAID5的目标存储体,以确保备份数据安全,避免因数据故障导致的恢复周期延长,我们的目标存储为DELL MD3000(12*1TB RAID5)。如果数据特别急,可以在征求客户同意的前提下,直接以只读的方式恢复数据到另外的存储介质,恢复方式见下面。
3、对做好的12块硬盘镜像进行逻辑分析,重点在于:盘充(这12块硬盘在原控制器上的组合顺序)、块大小(即组成原RAID的条带大小)、校验方式(校验的循环走向、同一条带的数据排序方式等)、logical driver在每块单盘上的起始位置、是否有数据满后(是否需要剔除陈旧盘)。 4、按照分析好的RAID参数,搭建虚拟RAID控制器(软件模拟),通过虚拟RAID控制器对单盘(或镜像)进行组织,形成虚拟卷(只读)。
5、对虚拟卷做文件系统解释,导出数据(只读),即完成所有数据恢复过程。
本例中,镜像花费约10小时,分析结构花费约半小时,恢复数据花费约10小时
2009年4月6日星期一
问专家:U盘突然无法识别了,数据还能恢复吗
作者:张宇,北亚数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
U盘插入USB HUB后无法识别,再接到其他USB口时依然提示:“跟这台计算机连接的一个USB设备运行不正常。。。”需要恢复数据。
导致 “跟这台计算机连接的一个USB设备运行不正常。。。”故障的原因大致有几个:
1、USB接口电压不足
2、U盘接口电路松动或损坏
3、晶振损坏
4、主控芯片(驱动芯片)损坏
如果是接口电压不足,可以更换环境再试。
如果是电路故障,需要拆开进行电路检查。
如果是晶振损坏,更换即可
如果是主控芯片损坏,可以更换相同或兼容的主控芯片来恢复数据,有时候同一型号的U盘,主控芯片也不一定相同。如果无法找到匹配的主控芯片,可以用PC3K FALSE等解码工具对存储芯片直接解码,但需要工具支持。如果没有工具可以对存储芯片进行解码,最后可通过编程器读取芯片内容后进行人工反向解码,再进行数据恢复,复杂程度很高。
针对文章开始的案例,后来得知,在同一USB HUB上接过的其他U盘也有损坏,可知是因USB HUB故障导致,很大可能是因电流、电压的错误导致U盘内部物理结构。
这类情况也算起个警示作用,最好的避免数据灾难的办法只有备份!
U盘插入USB HUB后无法识别,再接到其他USB口时依然提示:“跟这台计算机连接的一个USB设备运行不正常。。。”需要恢复数据。
导致 “跟这台计算机连接的一个USB设备运行不正常。。。”故障的原因大致有几个:
1、USB接口电压不足
2、U盘接口电路松动或损坏
3、晶振损坏
4、主控芯片(驱动芯片)损坏
如果是接口电压不足,可以更换环境再试。
如果是电路故障,需要拆开进行电路检查。
如果是晶振损坏,更换即可
如果是主控芯片损坏,可以更换相同或兼容的主控芯片来恢复数据,有时候同一型号的U盘,主控芯片也不一定相同。如果无法找到匹配的主控芯片,可以用PC3K FALSE等解码工具对存储芯片直接解码,但需要工具支持。如果没有工具可以对存储芯片进行解码,最后可通过编程器读取芯片内容后进行人工反向解码,再进行数据恢复,复杂程度很高。
针对文章开始的案例,后来得知,在同一USB HUB上接过的其他U盘也有损坏,可知是因USB HUB故障导致,很大可能是因电流、电压的错误导致U盘内部物理结构。
这类情况也算起个警示作用,最好的避免数据灾难的办法只有备份!
2009年4月5日星期日
问专家:有关一例EXT3文件系统故障
作者:张宇,北亚数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
一个网站服务器。数据卷为1TB硬盘一块,未做RAID,EXT3文件系统,未知原因,远程无法访问,到机房查询故障后发现文件系统无法mount,未做fsck。管理员为了安全,试图将整个硬盘dd到另一块相同的硬盘上再做分析及数据恢复工作,但dd备份时只能备份前320M数据,后面的无法读取,试图调整起始位置依然无济于事。因机房环境很吵,无法分辨硬盘是否有异响。
用户问了几个问题:
1、初步估计的故障是什么?数据恢复的可能性有多大?
答:最有可能的情况有两个:坏道或磁头不稳定。如果是坏道原因,可以通过专业的读取设备(如PC3K DE)进行读取,通常除绝对物理损坏的扇区无法读取外,其它扇区都有很大机会可读。如果是磁头不稳定,需要更换磁头方可读取数据,开盘换磁头的成功率取决于:工程师的能力、开盘的物理环境、备份的匹配程度、开盘后对数据的镜像方式(用设备读取成功率很高),但决定性因素是硬盘盘面是否刮伤,如果存在刮伤,即使其它方式做到最好,也无法恢复成功。
2、我的数据量很小,大约几十G,照EXT3的格式看,会不会存储于硬盘的最前端。这样,如果是坏道,是否可挑着恢复,比如只恢复前面数据?
答:ext3的格式的确是按照块组为单位,以渐减的方式存储数据与节点的,通常的确是从前向后存储的,但如果数据在存储过程中有删除、增加操作,其存储位置可能会有变化。
对于坏道,如果文件系统结构区可以一级一级地读出来,是可以按选择进行恢复的,或者确定数据就在前面几十G,也可以按这个区段进行读取。
3、这种情况是怎么产生的?应该如何避免?
答:即使是用SAS硬盘,作单盘存储本身也是不安全的,更何况是SATA硬盘(1TB的硬盘目前不可能是SAS,也不可能是IDE或SCSI)。单硬盘在长时间使用环境中,很难保证不出任何故障。如果需要避免,可选择用RAID的方式进行数据保护,同时需要做好备份工作(备份策略等)。
一个网站服务器。数据卷为1TB硬盘一块,未做RAID,EXT3文件系统,未知原因,远程无法访问,到机房查询故障后发现文件系统无法mount,未做fsck。管理员为了安全,试图将整个硬盘dd到另一块相同的硬盘上再做分析及数据恢复工作,但dd备份时只能备份前320M数据,后面的无法读取,试图调整起始位置依然无济于事。因机房环境很吵,无法分辨硬盘是否有异响。
用户问了几个问题:
1、初步估计的故障是什么?数据恢复的可能性有多大?
答:最有可能的情况有两个:坏道或磁头不稳定。如果是坏道原因,可以通过专业的读取设备(如PC3K DE)进行读取,通常除绝对物理损坏的扇区无法读取外,其它扇区都有很大机会可读。如果是磁头不稳定,需要更换磁头方可读取数据,开盘换磁头的成功率取决于:工程师的能力、开盘的物理环境、备份的匹配程度、开盘后对数据的镜像方式(用设备读取成功率很高),但决定性因素是硬盘盘面是否刮伤,如果存在刮伤,即使其它方式做到最好,也无法恢复成功。
2、我的数据量很小,大约几十G,照EXT3的格式看,会不会存储于硬盘的最前端。这样,如果是坏道,是否可挑着恢复,比如只恢复前面数据?
答:ext3的格式的确是按照块组为单位,以渐减的方式存储数据与节点的,通常的确是从前向后存储的,但如果数据在存储过程中有删除、增加操作,其存储位置可能会有变化。
对于坏道,如果文件系统结构区可以一级一级地读出来,是可以按选择进行恢复的,或者确定数据就在前面几十G,也可以按这个区段进行读取。
3、这种情况是怎么产生的?应该如何避免?
答:即使是用SAS硬盘,作单盘存储本身也是不安全的,更何况是SATA硬盘(1TB的硬盘目前不可能是SAS,也不可能是IDE或SCSI)。单硬盘在长时间使用环境中,很难保证不出任何故障。如果需要避免,可选择用RAID的方式进行数据保护,同时需要做好备份工作(备份策略等)。
2009年4月2日星期四
使用Handy Backup 6.2进行数据备份与还原(多图)
这几天比较了几个面向普通用户(文件级),位于WINDOWS平台自动备份软件,大致从几个方面进行测试:易用性、安全性、备份与还原的速度。先说说Handy Backup。
概括说一下,Handy Backup是一款功能强大的备份软件,支持自动备份到:CD-RW/DVD,硬盘或网络驱动器,ZIP、JAZ、MO和 FTP、LAN服务器,支持备份压缩(ZIP),支持备份加密(BLOWFISH 128位加密),可自动备份MS Outlook、注册表和ICQ文件,可增加插件增加备份数据源,同时支持备份硬盘镜像,支持多语言集(简体中文)。
安装过程很简单,这里不做介绍了。装好后,会在系统任务托盘常驻一个图标,双击此图标激活主界面:
选择语言为中文。

先制定一个测试用的备份计划:单击"文件"->"新建任务",调出任务对话框。

选择"备份任务"后,点下一步。

单击添加按钮,加入需要备份的数据源。

可选择的数据源真是很多,选择文件夹,测试备份一个文件夹。

单击下一步,选择备份方式,可选完全备份与增量备份,视情况选择。













单击下一步后,选择备份目的地:
备份目的有很多种,可以是本地可访问的文件夹,也可以是FTP\SFTP(利用这一点,就可以做在线备份了,还原也可以),也可以是CD-R/CD-RW/BLU-RAY/HD-DVD/DVD(软件本身支持刻录功能),或者是在线备份服务(国内暂时不必考虑,价格不低,速度不快,也没有handy backup的代理商)
这里我暂选本地备份(如上图所示,备份目的地为F:\),下一步继续。
上图的选项中可选择压缩与加密,压缩采用ZIP算法,会影响性能,本地备份建议不要选。非对称的加密算法可提供对文件备份的安全保护,如果数据重要,或者在线备份,可以加上密码,实际测量备份时的速度会低很多(尤其是处理大量小文件),但多数支持加密的软件速度都不会快到哪里去,视需求选择吧。
选择后,单击下一步。
出现备份时机对话框,有两个选项,立即运行是非计划的方案,只运行一次,编排计划可设定备份策略。这里选择编排计划。单击下一步。

上图意味着我们要每天12:33:20执行一次对"d:\qq files" 的增量备份。单击下一步进入结束页:
单击完成,返回主界面。
这样,备份策略便设定好了,在设定的时间内,备份计划将实施。
还原策略的设定与备份相似,只连续截图说明:

Handy Backup的使用感受:
1、方便使用,设置简单,支持简体中文
2、支持介质与数据源较多,支持备份到光盘。
3、可加密备份。
4、备份时生成索引文件,使增量备份/还原时速度更快。但感觉索引文件太重要了,尤其是加密后,如果没有索引文件将无法解开数据,还得注意多备份索引文件。
5、备份速度在不加密时很快,但加密后速度很慢(北亚数据恢复中心张宇曾经测试,500M的网站数据,本地加密备份,花了1小时)
6、支持FTP备份与还原,可做在线备份/还原使用。
7、还原时无法选择部分还原,只能全部还原或增量还原。如果备份包数据太多,可能是很麻烦的事情,尤其是在加密备份时,建议按功能拆成多个小包进行备份。
[问专家]误GHOST之后的数据还能恢复吗?
一个用户的咨询电话整理:
[用户]
我的硬盘用GHOST重做了系统,结构分区数目与分区大小与原来都不相同了,原来的文件系统是NTFS的,有5个分区,现在变成了4个FAT32的分区。
我的硬盘用GHOST重做了系统,结构分区数目与分区大小与原来都不相同了,原来的文件系统是NTFS的,有5个分区,现在变成了4个FAT32的分区。
这种情况能否恢复数据?成功率有多高?
[张宇]
硬盘在重新GHOST,变成4个分区之后,格式化了吗?有没有写过数据进去?
硬盘在重新GHOST,变成4个分区之后,格式化了吗?有没有写过数据进去?
[用户]
没有写过数据进去,不知道是否格式化了,能打开4个分区,但里面的空的。
没有写过数据进去,不知道是否格式化了,能打开4个分区,但里面的空的。
[张宇]
那是分区后,又做了格式化。
那是分区后,又做了格式化。
[用户]
那这种数据还能恢复吗?另外,有GHOST之前,我做错的操作,把C盘的数据全部GHOST到D盘了,这个还影响吗?实际上,最初我是想对C盘做个备份,结果不太熟,做完后,发现D盘和C 盘一模一样了,于是想自己恢复一下,重新用GHOST做了后,发现变成了4个分区,原来的E,F,G也没有了。这时候,就再也没敢动过了。
那这种数据还能恢复吗?另外,有GHOST之前,我做错的操作,把C盘的数据全部GHOST到D盘了,这个还影响吗?实际上,最初我是想对C盘做个备份,结果不太熟,做完后,发现D盘和C 盘一模一样了,于是想自己恢复一下,重新用GHOST做了后,发现变成了4个分区,原来的E,F,G也没有了。这时候,就再也没敢动过了。
[张宇]
如果是这样,那D盘的数据通常会麻烦一点,其他分区的数据应该问题不大,是有机会恢复的,当然,具体情况是需要做分析的,一个最简单的原则是,如果数据没有覆盖,就有机会恢复,如果数据被覆盖,数据就没希望了。你的情况,第一步做了C到D的GHOST,这时候不会影响其他分区的数据。但第二步做完后,因为有新的分区结构产生了,又做了格式化,操作系统会在为每个分区写一些数据,格式化也是写数据的一个过程,可能会有一些破坏。如果是FAT32,每个分区大约会写十几M或几十M的数据。至于恢复的可靠性,要看写入的这些数据的位置,如果正好位于原来硬盘的自由空间上,就不会有任何影响;如果正好位于数据区,那可能会影响这个数据区原先存储的文件,就是几M或几十M的影响;如果正好位于文件系统区,就要进一步分析,情况会多一些,是差的情况,可能会影响大量数据,不仅仅是几M或几十M,这个因为涉及的因素很多,暂不多谈,只说一点:覆盖文件系统核心区的概念是很低的,通常不必太焦虑。
如果是这样,那D盘的数据通常会麻烦一点,其他分区的数据应该问题不大,是有机会恢复的,当然,具体情况是需要做分析的,一个最简单的原则是,如果数据没有覆盖,就有机会恢复,如果数据被覆盖,数据就没希望了。你的情况,第一步做了C到D的GHOST,这时候不会影响其他分区的数据。但第二步做完后,因为有新的分区结构产生了,又做了格式化,操作系统会在为每个分区写一些数据,格式化也是写数据的一个过程,可能会有一些破坏。如果是FAT32,每个分区大约会写十几M或几十M的数据。至于恢复的可靠性,要看写入的这些数据的位置,如果正好位于原来硬盘的自由空间上,就不会有任何影响;如果正好位于数据区,那可能会影响这个数据区原先存储的文件,就是几M或几十M的影响;如果正好位于文件系统区,就要进一步分析,情况会多一些,是差的情况,可能会影响大量数据,不仅仅是几M或几十M,这个因为涉及的因素很多,暂不多谈,只说一点:覆盖文件系统核心区的概念是很低的,通常不必太焦虑。
D盘的数据涉及的问题也是很复杂的,通常这已经产生的覆盖,恢复的机率在分析之前无法判断。通常一个不一定很正确、但概率最大的理解方式是:如果原来有10个G的数据量,现在写进去了3个G,那有可能还能恢复10-3=7G的数据。但这样的算法其实是很不科学的,只能说明数据恢复的大致原则。
[用户]
那这样的数据恢复,如果做不成功,会不会对硬盘造成破坏,在一家数据恢复公司恢复完后,如果做不成,是否会影响下次恢复?
那这样的数据恢复,如果做不成功,会不会对硬盘造成破坏,在一家数据恢复公司恢复完后,如果做不成,是否会影响下次恢复?
[张宇]
正规的做法是不会对硬盘有任何破坏的,我们的做法是以不加载硬盘盘符的方式进行读操作,通过虚拟方式进行分析还原。即便是数据已经恢复出来了,在确认之前也仅仅是在虚拟环境下的,不会对原来的结构有任何不可逆的操作。如果无法恢复,或者用户确定不需要恢复了。硬盘完全和我们恢复之前是一模一样的。
正规的做法是不会对硬盘有任何破坏的,我们的做法是以不加载硬盘盘符的方式进行读操作,通过虚拟方式进行分析还原。即便是数据已经恢复出来了,在确认之前也仅仅是在虚拟环境下的,不会对原来的结构有任何不可逆的操作。如果无法恢复,或者用户确定不需要恢复了。硬盘完全和我们恢复之前是一模一样的。
当然,我们前提也有申明,恢复过程中也有可能出现人力无法避免的灾难,比如硬盘突然非人为损坏了,但这个可能性是极低的。我们的恢复也是完全在客户监督下完成的。
[用户]
恢复的时间,价格以及付款方式是什么?
恢复的时间,价格以及付款方式是什么?
2009年4月1日星期三
RAID损坏后,对数据的完整备份
作者:张宇,北亚数据恢复中心,创作于2007年7月31日,最初发布于51CTO博客上.转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
RAID中对单盘做镜像的方式(以SAS硬盘为例):
-、关闭磁盘阵列,将所有硬盘依次拔下来(最好标记好顺序号),挂接在不含RAID功能的SAS适配器上。
下图为拔下硬盘的正面及背面图(SAS硬盘有2.5与3.5寸两种接口,图中为3.5寸)


下图为其接口放大:

上图接口为SAS接口。只能用SAS适配器连接。RAID损坏后,要想完整备份源数据,必须保证对所有硬盘的读写都是可回溯的。为此,只能使用不含RAID功能的SAS适配器进行连接后镜像,这样才能以单硬盘的方式进行访问。
下图为PCI-E接口的SAS适配卡。

上图中的卡,已连接好数据线。可以最多连接4块SAS硬盘(末端的接口可直接连接硬盘),此卡为PCI-E 8×接口。
连接好硬盘的示意图如下:

下图中的卡为PCI-X接口SAS适配卡。

使用下图连线可直接连接SAS硬盘

连接好线后的图如下:

全部连接好的图如下所示:




二、保证挂接服务器使用操作系统为WIN2003(其他系统也可以,本例以 WINDOWS为例)。
进入系统后,磁盘管理里会看到多个单独的硬盘,此时切记不可初始化磁盘、分区或分配盘符给可能的磁盘分区(如果不确定是否可避免,建议不要进入磁盘管理)。
推荐的作法是利用直接可访问磁盘底层扇区内容的16进制编辑器。以WINHEX为例,安装好WINHEX后,进入WINHEX,如下图所示:
点击Tools—>Open disk菜单,如下图:
点击后出现如下图所示:
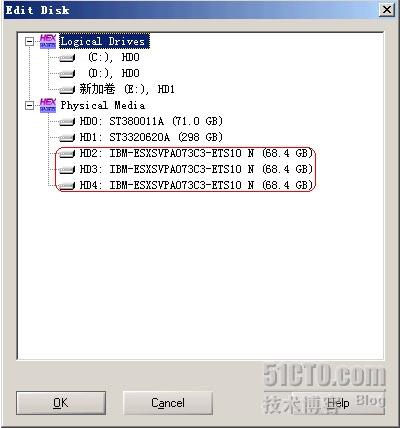
上图中Physical Media下列出的便是当前系统挂接到的所有物理存储设备,不经过RAID,以单盘的方式挂接,此列表就会出现物理硬盘的MODEL号及容量。上图中红色框内的便是3块IBM73G 单盘的ID显示。如果选中某块硬盘,点击OK按钮便可以以物理地址16进制的方式打开磁盘(此时不管有没有分区,什么文件系统,都无关重要。打开的便是硬盘73G 的存储空间内容),当然,在做镜像时,并不需要打开。我们只是打开这个对话框确定一下硬盘是否挂上。选择Cancel退出。
开始做镜像:
点击Tools->Disk tools->Clone Disk,如下图所示:
弹出的对话框如下图:
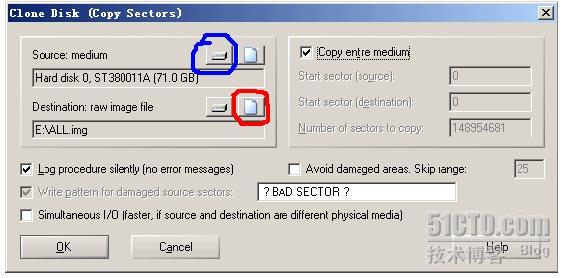
点击图中兰色所圈按钮,选择源磁盘。选中红色所圈按钮,选择目标文件。(我们的目的是将源硬盘镜像为一个文件,此后,这个文件就是对源硬盘的完整镜像了,大小等于源硬盘的大小,此例中,完成后,目标文件即有73G 之大)如下图
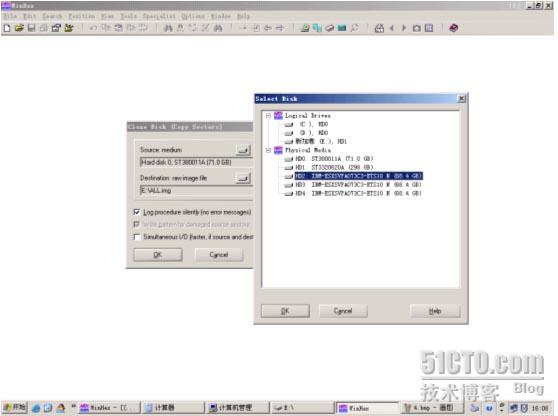
此例中选中HD2(即3块IBM SAS硬盘的第一块),点击OK后返回刚才的对话框,此时Source medium列表中便会出来选中的HD2 IBM…..
相同的方式,选择目标文件。如下图:
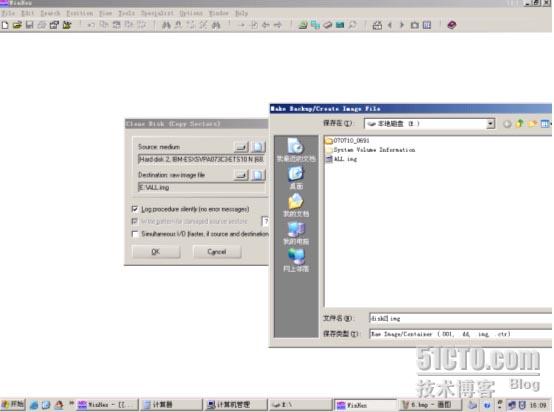
选好目标文件路径及文件名后。确定返回。
此时,Clone disk对话框如下图。
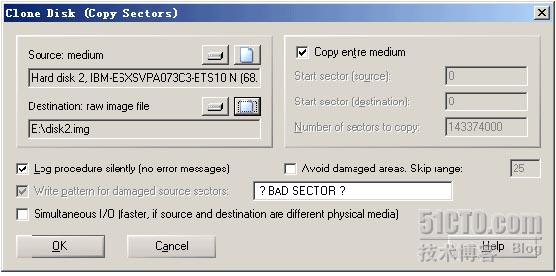
请再次确认,Source(源)及Destination(目标)是否正确。
对话框中的其他值应该为:点中Copy entire medium(意为做全盘的镜像),Log procedure…可选(选中后,会在拷贝结束后展示摘要,推荐使用,可以知道硬盘是否有坏道等),其他参数不要管(其他参数通常适用于严重坏道等情形)
选好后(一定要确认源和目标),按下OK按钮便开始镜像操作了(WINHEX第一次做此操作,当按下OK按钮时会弹出一个帮助框,意在提醒用户,此操作是有风险的。无碍,可关掉。之后不会再出现)
拷贝的过程如下图:
此过程完成后,镜像就完成了。目标文件即等同于源硬盘,之后可以使用WINHEX用逆向还原回原硬盘。
RAID中对单盘做镜像的方式(以SAS硬盘为例):
-、关闭磁盘阵列,将所有硬盘依次拔下来(最好标记好顺序号),挂接在不含RAID功能的SAS适配器上。
下图为拔下硬盘的正面及背面图(SAS硬盘有2.5与3.5寸两种接口,图中为3.5寸)
下图为其接口放大:
上图接口为SAS接口。只能用SAS适配器连接。RAID损坏后,要想完整备份源数据,必须保证对所有硬盘的读写都是可回溯的。为此,只能使用不含RAID功能的SAS适配器进行连接后镜像,这样才能以单硬盘的方式进行访问。
下图为PCI-E接口的SAS适配卡。
上图中的卡,已连接好数据线。可以最多连接4块SAS硬盘(末端的接口可直接连接硬盘),此卡为PCI-E 8×接口。
连接好硬盘的示意图如下:
下图中的卡为PCI-X接口SAS适配卡。
使用下图连线可直接连接SAS硬盘
连接好线后的图如下:
全部连接好的图如下所示:
二、保证挂接服务器使用操作系统为WIN2003(其他系统也可以,本例以 WINDOWS为例)。
进入系统后,磁盘管理里会看到多个单独的硬盘,此时切记不可初始化磁盘、分区或分配盘符给可能的磁盘分区(如果不确定是否可避免,建议不要进入磁盘管理)。
推荐的作法是利用直接可访问磁盘底层扇区内容的16进制编辑器。以WINHEX为例,安装好WINHEX后,进入WINHEX,如下图所示:
点击Tools—>Open disk菜单,如下图:
点击后出现如下图所示:
上图中Physical Media下列出的便是当前系统挂接到的所有物理存储设备,不经过RAID,以单盘的方式挂接,此列表就会出现物理硬盘的MODEL号及容量。上图中红色框内的便是3块IBM
开始做镜像:
点击Tools->Disk tools->Clone Disk,如下图所示:
弹出的对话框如下图:
点击图中兰色所圈按钮,选择源磁盘。选中红色所圈按钮,选择目标文件。(我们的目的是将源硬盘镜像为一个文件,此后,这个文件就是对源硬盘的完整镜像了,大小等于源硬盘的大小,此例中,完成后,目标文件即有
此例中选中HD2(即3块IBM SAS硬盘的第一块),点击OK后返回刚才的对话框,此时Source medium列表中便会出来选中的HD2 IBM…..
相同的方式,选择目标文件。如下图:
选好目标文件路径及文件名后。确定返回。
此时,Clone disk对话框如下图。
请再次确认,Source(源)及Destination(目标)是否正确。
对话框中的其他值应该为:点中Copy entire medium(意为做全盘的镜像),Log procedure…可选(选中后,会在拷贝结束后展示摘要,推荐使用,可以知道硬盘是否有坏道等),其他参数不要管(其他参数通常适用于严重坏道等情形)
选好后(一定要确认源和目标),按下OK按钮便开始镜像操作了(WINHEX第一次做此操作,当按下OK按钮时会弹出一个帮助框,意在提醒用户,此操作是有风险的。无碍,可关掉。之后不会再出现)
拷贝的过程如下图:
此过程完成后,镜像就完成了。目标文件即等同于源硬盘,之后可以使用WINHEX用逆向还原回原硬盘。
2009年3月31日星期二
windows下解压linux、unix平台TAR包的乱码问题
作者:张宇,北亚硬盘数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
这篇文章的部分观点是我的个人看法,可能会有错误,希望大家指正。
WINDOWS与LINUX/UNIX对文件系统字符集的处理方式是不相同的。WINDOWS文件系统驱动层本身就有对字符集转换、处理的模块,无论从操作系统上下达的是什么字符集,最后要统一转换到不同文件系统的字符处理模块上,比如存储在NTFS上的文件名称,现在几乎统一以$I30方式索引,采用UNICODE方式存储。而LINUX/UNIX则不同,文件系统驱动层本身并不负责对字符集的处理,操作系统传下来的文件名称以字节流的方式直接记录进文件系统索引结构,并不去理解字符集,所以,在同一个LINUX/UNIX文件系统中,可以允许目录结构中有多种不同的字符集存在。
如果在LINUX/UNIX下对某些文件做了tar包,tar包里便直接记录从文件系统上读到的名称字节流,那如果这个TAR包在WINDOWS下解压,便很有可能会出现乱码,或无法解压。其实解决的办法很简单,只要把WINDOWS调整成不同的字符集,解压对应的文件即可,只是这个对应需要人工去判断了。
打开WINDOWS的控制面板,选择“区域和语言选项”,再移至“高级”选项卡上,在“选择一种语言,使之与您使用的非UNICODE程序的语言。。。。”一项上选择相应的字符集。然后,将tar包里对应这个字符集的文件解压到NTFS文件系统上,这些文件就会自动转换成UNICODE通用字符集。再换成其他字符集,解压,就可以把别的字符集也转换成UNICODE了。
很多NAS设备,由于用户使用的字符集可能不同(典型的,香港、台湾地区、大陆的联合企业使用的NAS),这样如果对NAS数据做备份后,想在WINDOWS上解开,网管对LINUX又不熟,用这个方法可能能容易的解决。
这篇文章的部分观点是我的个人看法,可能会有错误,希望大家指正。
WINDOWS与LINUX/UNIX对文件系统字符集的处理方式是不相同的。WINDOWS文件系统驱动层本身就有对字符集转换、处理的模块,无论从操作系统上下达的是什么字符集,最后要统一转换到不同文件系统的字符处理模块上,比如存储在NTFS上的文件名称,现在几乎统一以$I30方式索引,采用UNICODE方式存储。而LINUX/UNIX则不同,文件系统驱动层本身并不负责对字符集的处理,操作系统传下来的文件名称以字节流的方式直接记录进文件系统索引结构,并不去理解字符集,所以,在同一个LINUX/UNIX文件系统中,可以允许目录结构中有多种不同的字符集存在。
如果在LINUX/UNIX下对某些文件做了tar包,tar包里便直接记录从文件系统上读到的名称字节流,那如果这个TAR包在WINDOWS下解压,便很有可能会出现乱码,或无法解压。其实解决的办法很简单,只要把WINDOWS调整成不同的字符集,解压对应的文件即可,只是这个对应需要人工去判断了。
打开WINDOWS的控制面板,选择“区域和语言选项”,再移至“高级”选项卡上,在“选择一种语言,使之与您使用的非UNICODE程序的语言。。。。”一项上选择相应的字符集。然后,将tar包里对应这个字符集的文件解压到NTFS文件系统上,这些文件就会自动转换成UNICODE通用字符集。再换成其他字符集,解压,就可以把别的字符集也转换成UNICODE了。
很多NAS设备,由于用户使用的字符集可能不同(典型的,香港、台湾地区、大陆的联合企业使用的NAS),这样如果对NAS数据做备份后,想在WINDOWS上解开,网管对LINUX又不熟,用这个方法可能能容易的解决。
2009年3月30日星期一
WINDOWS是如何在注册表里记录盘符分配的
windows在加载一个之前从未加载过的分区时,首先要将这个分区的设备序号信息记录在注册表里,如果对这个分区进行了盘符(或路径)分配,那么在下次加载这个分区的时候就不用再次指定盘符(或路径)了。
这些信息记录在:[HKEY_LOCAL_MACHINE\SYSTEM\MountedDevices]键值下,内容大致为(从我的电脑里导出的):附件1
这里面重要的是这几个:
"\\DosDevices\\R:"=hex:eb,f8,b2,92,00,7e,00,00,00,00,00,00
上面的R:表示盘符为R,后面的HEX值中分成两个部分,第一部分是前4个HEX值,表示R分区所属硬盘的序号,后面8个HEX表示R分区在这个硬盘的偏移起始位置,以字节为单位。对照上面的R,看一下R分区所属的硬盘的0扇区:
Offset 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F
000000000 33 C0 8E D0 BC 00 7C FB 50 07 50 1F FC BE 1B 7C
000000010 BF 1B 06 50 57 B9 E5 01 F3 A4 CB BD BE 07 B1 04
000000020 38 6E 00 7C 09 75 13 83 C5 10 E2 F4 CD 18 8B F5
000000030 83 C6 10 49 74 19 38 2C 74 F6 A0 B5 07 B4 07 8B
000000040 F0 AC 3C 00 74 FC BB 07 00 B4 0E CD 10 EB F2 88
000000050 4E 10 E8 46 00 73 2A FE 46 10 80 7E 04 0B 74 0B
000000060 80 7E 04 0C 74 05 A0 B6 07 75 D2 80 46 02 06 83
000000070 46 08 06 83 56 0A 00 E8 21 00 73 05 A0 B6 07 EB
000000080 BC 81 3E FE 7D 55 AA 74 0B 80 7E 10 00 74 C8 A0
000000090 B7 07 EB A9 8B FC 1E 57 8B F5 CB BF 05 00 8A 56
0000000A0 00 B4 08 CD 13 72 23 8A C1 24 3F 98 8A DE 8A FC
0000000B0 43 F7 E3 8B D1 86 D6 B1 06 D2 EE 42 F7 E2 39 56
0000000C0 0A 77 23 72 05 39 46 08 73 1C B8 01 02 BB 00 7C
0000000D0 8B 4E 02 8B 56 00 CD 13 73 51 4F 74 4E 32 E4 8A
0000000E0 56 00 CD 13 EB E4 8A 56 00 60 BB AA 55 B4 41 CD
0000000F0 13 72 36 81 FB 55 AA 75 30 F6 C1 01 74 2B 61 60
000000100 6A 00 6A 00 FF 76 0A FF 76 08 6A 00 68 00 7C 6A
000000110 01 6A 10 B4 42 8B F4 CD 13 61 61 73 0E 4F 74 0B
000000120 32 E4 8A 56 00 CD 13 EB D6 61 F9 C3 49 6E 76 61
000000130 6C 69 64 20 70 61 72 74 69 74 69 6F 6E 20 74 61
000000140 62 6C 65 00 45 72 72 6F 72 20 6C 6F 61 64 69 6E
000000150 67 20 6F 70 65 72 61 74 69 6E 67 20 73 79 73 74
000000160 65 6D 00 4D 69 73 73 69 6E 67 20 6F 70 65 72 61
000000170 74 69 6E 67 20 73 79 73 74 65 6D 00 00 00 00 00
000000180 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
000000190 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0000001A0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0000001B0 00 00 00 00 00 2C 44 63 EB F8 B2 92 00 00 00 01
0000001C0 01 00 07 FE FF FF 3F 00 00 00 3F F5 7F 0C 00 00
0000001D0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0000001E0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0000001F0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 55 AA
000000010 BF 1B 06 50 57 B9 E5 01 F3 A4 CB BD BE 07 B1 04
000000020 38 6E 00 7C 09 75 13 83 C5 10 E2 F4 CD 18 8B F5
000000030 83 C6 10 49 74 19 38 2C 74 F6 A0 B5 07 B4 07 8B
000000040 F0 AC 3C 00 74 FC BB 07 00 B4 0E CD 10 EB F2 88
000000050 4E 10 E8 46 00 73 2A FE 46 10 80 7E 04 0B 74 0B
000000060 80 7E 04 0C 74 05 A0 B6 07 75 D2 80 46 02 06 83
000000070 46 08 06 83 56 0A 00 E8 21 00 73 05 A0 B6 07 EB
000000080 BC 81 3E FE 7D 55 AA 74 0B 80 7E 10 00 74 C8 A0
000000090 B7 07 EB A9 8B FC 1E 57 8B F5 CB BF 05 00 8A 56
0000000A0 00 B4 08 CD 13 72 23 8A C1 24 3F 98 8A DE 8A FC
0000000B0 43 F7 E3 8B D1 86 D6 B1 06 D2 EE 42 F7 E2 39 56
0000000C0 0A 77 23 72 05 39 46 08 73 1C B8 01 02 BB 00 7C
0000000D0 8B 4E 02 8B 56 00 CD 13 73 51 4F 74 4E 32 E4 8A
0000000E0 56 00 CD 13 EB E4 8A 56 00 60 BB AA 55 B4 41 CD
0000000F0 13 72 36 81 FB 55 AA 75 30 F6 C1 01 74 2B 61 60
000000100 6A 00 6A 00 FF 76 0A FF 76 08 6A 00 68 00 7C 6A
000000110 01 6A 10 B4 42 8B F4 CD 13 61 61 73 0E 4F 74 0B
000000120 32 E4 8A 56 00 CD 13 EB D6 61 F9 C3 49 6E 76 61
000000130 6C 69 64 20 70 61 72 74 69 74 69 6F 6E 20 74 61
000000140 62 6C 65 00 45 72 72 6F 72 20 6C 6F 61 64 69 6E
000000150 67 20 6F 70 65 72 61 74 69 6E 67 20 73 79 73 74
000000160 65 6D 00 4D 69 73 73 69 6E 67 20 6F 70 65 72 61
000000170 74 69 6E 67 20 73 79 73 74 65 6D 00 00 00 00 00
000000180 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
000000190 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0000001A0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0000001B0 00 00 00 00 00 2C 44 63 EB F8 B2 92 00 00 00 01
0000001C0 01 00 07 FE FF FF 3F 00 00 00 3F F5 7F 0C 00 00
0000001D0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0000001E0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0000001F0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 55 AA
图中偏移为0x1B8~0x1BB,内容为HEX:EB F8 B2 92就是注册表中记录的R分区的硬盘序号。而从偏移0x1be~0x1ce中的第一组分区表可以看出,唯一的分区起始位置为0x3F,以扇区为单位,换成字节就是0x3F*0x200=0x7E00,如果用8字节的64位值表示,HEX就是00 7E 00 00 00 00 00 00 ,就是注册表中记录的键值的后半部分。
2009年3月29日星期日
离线方式读写WINDOWS注册表
作者:张宇,北亚硬盘数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
本文仅在WINDOWS XP及WINDOWS 2003上测试通过,其他平台未知。
我在2007年曾经草拟了一篇文章《成功修复一例WINDOWS系统反复登陆,无法启动》,当时的想法是觉得这个过程很有意义,想把解决过程记录下来,结果是日复一日的忙碌,最终不了了之。其实在解决问题的过程中,体会最深的便是在系统无法启动的情况下,同时又没有注册表备份,如何修改它的错误的注册表键值。
一个简单的方法是利用注册表编辑器的加载配置单元。
WINDOWS XP和WINDOWS 2003的注册表文件通常在%SystemRoot%\system32\config 文件夹下:SAM、SECURITY、SOFTWARE、SYSTEM,当操作系统无法启动时,可以把这块无法启动的硬盘挂载在另外的WINDOWS上,或者通过PE进入系统,然后加载原先系统错误的注册表文件,再对相应键值进行修改。
具体流程为:
打开“注册表编辑器”。
在注册表树(左侧)中,单击 HKEY_USERS 或者 HKEY_LOCAL_MACHINE 项。
在“文件”菜单上,单击“加载配置单元”。
在“查找范围”中,单击包含要加载的配置单元的驱动器、文件夹、网络计算机和文件夹。
单击“打开”。
在“项名称”中,键入要指派给配置单元的名称(随意起个名称就行了,作为子键名称),然后单击“确定”。
注意事项: 1、“加载配置单元”和“卸载配置单元”只影响 HKEY_USERS 和 HKEY_LOCAL_MACHINE 项,并且只有选中这些预定义项时它们才是活动的。在将配置单元加载到注册表中时,配置单元成为其中一个项的子项。 2、修改完成后,别忘记卸载配置单元(在regedit中选择先前加载到系统中的配置单元,再打开文件菜单,选择“卸载配置单元”)
本文仅在WINDOWS XP及WINDOWS 2003上测试通过,其他平台未知。
我在2007年曾经草拟了一篇文章《成功修复一例WINDOWS系统反复登陆,无法启动》,当时的想法是觉得这个过程很有意义,想把解决过程记录下来,结果是日复一日的忙碌,最终不了了之。其实在解决问题的过程中,体会最深的便是在系统无法启动的情况下,同时又没有注册表备份,如何修改它的错误的注册表键值。
一个简单的方法是利用注册表编辑器的加载配置单元。
WINDOWS XP和WINDOWS 2003的注册表文件通常在%SystemRoot%\system32\config 文件夹下:SAM、SECURITY、SOFTWARE、SYSTEM,当操作系统无法启动时,可以把这块无法启动的硬盘挂载在另外的WINDOWS上,或者通过PE进入系统,然后加载原先系统错误的注册表文件,再对相应键值进行修改。
具体流程为:
打开“注册表编辑器”。
在注册表树(左侧)中,单击 HKEY_USERS 或者 HKEY_LOCAL_MACHINE 项。
在“文件”菜单上,单击“加载配置单元”。
在“查找范围”中,单击包含要加载的配置单元的驱动器、文件夹、网络计算机和文件夹。
单击“打开”。
在“项名称”中,键入要指派给配置单元的名称(随意起个名称就行了,作为子键名称),然后单击“确定”。
注意事项: 1、“加载配置单元”和“卸载配置单元”只影响 HKEY_USERS 和 HKEY_LOCAL_MACHINE 项,并且只有选中这些预定义项时它们才是活动的。在将配置单元加载到注册表中时,配置单元成为其中一个项的子项。 2、修改完成后,别忘记卸载配置单元(在regedit中选择先前加载到系统中的配置单元,再打开文件菜单,选择“卸载配置单元”)
2009年3月28日星期六
linux ext3 fsck一定要慎用
作者:张宇,北亚硬盘数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
不管是哪种文件系统,其根本目的都是相同的:如何把文件存在系统给定的区域里,如何有效地管理文件的读与写。为实现这样的目的,驱动层需要完善、周密地应付附加在文件系统上的各种操作。这些操作通常不会是一条指令完成的,如果一个过程需要多条指令完成,在执行这些操作时,全部指令未完成的情况下产生中断,那这个文件系统便会出现一致性错误(或者叫连续性错误)。
为了保证尽可以少的出现一致性错误,现在主流的文件系统都会设计成日志型的。日志型文件系统的主要特点就是把一个操作的所有指令执行过程都另外缓冲下来,如果全部执行完成再清除日志标志,如果操作没有执行完成,可以在重新激活后通过日志回溯或继续完成。
EXT3的日志功能通过在EXT2的设计基础上增加一个特殊的文件(通常是8号节点文件),在这个文件中记录文件系统的操作过程。但EXT系统文件系统本身在节点、间接索引块、目录节点方面没有冗余保护,所以当文件系统除日志外的其他结构并不一致,却又要通过fsck来进行修复,这种一致性有可能将原本正确的结构也错误化。(就像原来是1+2=3,现在错成了1+3=3,也许改完后变成了1+3=4,就完全没办法还原成最早的1+2=3)。
数据恢复领域经常会遇到这类情况:一次RAID出故障后,下次启动系统提示做fsck,但做完后,也无法mount分区或者mount 分区后数据全是错的。需要对这类情况进行数据修复的难度是很大的,从一个完整的结构(fsck后实际上从系统角度看已经是完整的了)再构建另一个完全不同的结构要比修正一个错误的结构更难以下手。其实这类情况,很多是因为RAID5有早离线的盘加入了两个逻辑磁盘组,导致所有的数据流是以新+旧的方式交错组成的,自然会有太多错误。这时候如果做fsck后,有可能数据都无法恢复了。
所以,在EXT3(实际上其他文件系统也类似)无法mount,或者提示fsck时,如果有重要数据,应该慎重对待,千万不可贸然执行"fsck -f -y "这样的自动修复功能。如果可能,先对故障区域做dd全镜像后再执行,或者以只读方式执行,并仔细看修复过程,如果提示大量inode错误、需要重建树、或大小不对等就不可再继续下去了。
不管是哪种文件系统,其根本目的都是相同的:如何把文件存在系统给定的区域里,如何有效地管理文件的读与写。为实现这样的目的,驱动层需要完善、周密地应付附加在文件系统上的各种操作。这些操作通常不会是一条指令完成的,如果一个过程需要多条指令完成,在执行这些操作时,全部指令未完成的情况下产生中断,那这个文件系统便会出现一致性错误(或者叫连续性错误)。
为了保证尽可以少的出现一致性错误,现在主流的文件系统都会设计成日志型的。日志型文件系统的主要特点就是把一个操作的所有指令执行过程都另外缓冲下来,如果全部执行完成再清除日志标志,如果操作没有执行完成,可以在重新激活后通过日志回溯或继续完成。
EXT3的日志功能通过在EXT2的设计基础上增加一个特殊的文件(通常是8号节点文件),在这个文件中记录文件系统的操作过程。但EXT系统文件系统本身在节点、间接索引块、目录节点方面没有冗余保护,所以当文件系统除日志外的其他结构并不一致,却又要通过fsck来进行修复,这种一致性有可能将原本正确的结构也错误化。(就像原来是1+2=3,现在错成了1+3=3,也许改完后变成了1+3=4,就完全没办法还原成最早的1+2=3)。
数据恢复领域经常会遇到这类情况:一次RAID出故障后,下次启动系统提示做fsck,但做完后,也无法mount分区或者mount 分区后数据全是错的。需要对这类情况进行数据修复的难度是很大的,从一个完整的结构(fsck后实际上从系统角度看已经是完整的了)再构建另一个完全不同的结构要比修正一个错误的结构更难以下手。其实这类情况,很多是因为RAID5有早离线的盘加入了两个逻辑磁盘组,导致所有的数据流是以新+旧的方式交错组成的,自然会有太多错误。这时候如果做fsck后,有可能数据都无法恢复了。
所以,在EXT3(实际上其他文件系统也类似)无法mount,或者提示fsck时,如果有重要数据,应该慎重对待,千万不可贸然执行"fsck -f -y "这样的自动修复功能。如果可能,先对故障区域做dd全镜像后再执行,或者以只读方式执行,并仔细看修复过程,如果提示大量inode错误、需要重建树、或大小不对等就不可再继续下去了。
2009年3月27日星期五
也谈WINDOWS 下分区类型变为 RAW
作者:张宇,北亚硬盘数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
看到网上有很多人提到,在正常使用电脑的情况下,分区类型变为RAW,双击时提示"驱动器X未被格式化,是否格式化",导致数据无法读取。应对这类情况,网友们的恢复方案往往是各执一词,各有各的道理,大家似乎都有恢复成功的理论依据。但实际上,所有的解决方案都是建立在适当的数据结构理论基础上的,并不能一概而论。
开门见山地说吧。既然提示"驱动器X未被格式化,是否格式化",那重点就在于这个X(就用这个盘符假定吧)是未被格式化的,或者说不知道是什么格式。那格式又是什么呢?简单的解释,把一个分区划分出结构,以便于组织文件。这个"格式"实际上就是文件系统。合起来,把这句话翻译一下,就是"X分区不知道是什么文件系统,是不是强制规划一个文件系统?"
那系统为什么不知道X是一个什么文件系统呢?(再通俗一点,就是分区格式,如FAT还是NTFS)
FAT或是NTFS(或是LINUX UNIX下的文件系统)实际上是一种把文件如何放到连续(有时候是逻辑连续,但我们认为他连续就可以了)的一片磁盘空间的一种方法。这个方法听起来简单,真正做起来要考虑的事情是很多的,比如放进去怎么取出来?怎么很高效的取出来?删了数据怎么把空间挪出来等等。这些做法我们不详细说明(有兴趣看看我写过的《FAT文件系统原理》,地址网上一查,到处都有)。单单说一个事情,既然FAT和NTFS都是组织文件的不同形式,那系统在读的时候肯定是要知道它是FAT还是NTFS,再调用不同的驱动去解释它。这部分用来标记是NTFS还是FAT,包括NTFS或FAT的参数的结构,一般叫做DBR(LINUX/UNIX里叫做SUPER BLOCK)。
因为DBR是申明文件系统类型的结构,所以FAT/NTFS的DBR一定要位置相同。毕竟驱动要先到一个固定的地方读出DBR,才能判断是NTFS还是FAT。这个固定的地方是分区的最前面,即0扇区。
如果0扇区是错的,文件系统驱动读取0扇区时,发现既不满足FAT规则,也不满足NTFS规则,那自然地会抛出异常,询问用户"我不知道是什么文件系统,是不是要强制规划一个指定的文件系统?",就是文中的错误提示。
知道问题所在了,看如何解决?
既然0扇区是错的,那把结构改成原来的0扇区不就可以了吗?
是的,大多数情况这样就可以搞定了。FAT32系统的6扇区会有一个格式化后便做好的DBR的备份,NTFS同样在分区的最后留有一个DBR的备份。用磁盘编辑工具,找到这个备份,把它贴回0扇区,重新识别文件系统即可。
当然事情有时候不是这样简单的。比如如果是FAT就没有DBR的备份,或者如果FAT32的6扇区也被破坏(这是非常正常的),或者不光DBR损坏,其它结构也有问题(结构不匹配,即使DBR正确,系统照样不知道是什么文件系统)。如果不幸真得被我言中的话,事情会变得稍麻烦一些。专业的做法是根据文件系统数据区的存储结构,重新计算出原来是什么文件系统,文件系统的参数是什么,但这个对普通用户而言是困难的。那只能用数据恢复软件了吗?
用什么软件,以及软件的用法我不详述,网上能查到的我没必要再费力去写。但有时候你还是会发现软件也解决不了,归一下原因,事实上是大部分数据恢复软件也要依靠DBR去进行扫描(很傻),那这样就惨了,排除找专业数据恢复公司恢复以外,我只能给出这样的建议了:
1、在磁盘管理里,先把盘符删掉。
2、无论如何,有空间的话,先对故障区域或全盘做完整备份。见:《如何对磁盘做完整的全盘镜像备份? 》
3、按原来的文件系统结构对一个无用的大小相等或稍大的分区做格式化(希望你记得对,也希望你运气好,这实在不是专业的做法),然后把0扇区拷贝到故障分区里。或者备份后对故障分区直接格式化,格完后,从镜像把前3.5G数据还原回来。(注:做完后最好不要急着加盘符)
4、可以在CMD下执行CHKDSK(没有备份过的,可千万别贸然做)。或者再用数据恢复软件进行处理。
5、如果用第4步处理不成功,比如导出来的文件名称都对,就是数据全部不对,那应该是格式化参数不对,可以手动重新格式化一下。如果没有专业分析方法,那就只能簇大小512B,1KB,2KB,4KB,8KB,16KB,32KB这样试试了。
辟几个谣:
1、出现此类故障后,按系统提示,格式化后,用数据恢复软件就能全部恢复出来了。
结论:大错特错,完全不重视数据安全。
原因:格式化是一定会写一些数据进去的,只是写进去的这些数据会不会覆盖你所需的数据。有些人成功过,只是因为格式化操作没有覆盖他需要的数据,或者说命好,但如果格式化覆盖了重要数据,那可就麻烦大了(目前找谁都没用)。尤其是FAT文件系统,格式化后数据的恢复很难做到100%,而且越是重要的频繁修改的文件越不容易恢复。
2、出现此类故障后,在CMD下直接执行CHKDSK。
结论:错误,依然是危险操作
原因:CHKDSK的目的是将结构不一致的文件系统一致化,那这中间便会有一套算法。为了傻瓜型操作,微软并不会提供更专业的修正建议,所以程序难免会“一根筋”,修好皆大欢喜,修不好哭都来不及。如果不幸执行了CHKDSK,同时屏幕上出现大量的错误提示,那就赶紧强制结束吧,否则,就等着给数据收尸吧。
2009年3月26日星期四
WINHEX Scripts
Most of the functionality of WinHex can be used in an automated way, e.g. to speed up recurring routine tasks or to perform certain tasks on unattended remote computers. The ability to execute scripts other than the supplied sample scripts is limited to owners of a professional or specialist license. Scripts can be run from the Start Center or the command line. While a script is executed, you may press Esc to abort. Because of their superior possibilities, scripts supersede routines, which were the only method of automation in previous versions of WinHex.
WinHex scripts are text files with the filename extension ".whs". They can be edited using any text editor and simply consist of a sequence of commands. It is recommended to enter one command per line only, for reasons of visual clarity. Depending on the command, you may need to specify parameters next to a command. Most commands affect the file or disk presented in the currently active window.
Also see: WinHex API
Script commands are case-insensitive. Comments may occur anywhere in a script file and must be preceded by two slashes. Parameters may be 255 characters long at most. Where in doubt because hex values, text strings (or even integer numbers) are accepted as parameters, you may use inverted commas (quotation marks) to enforce the interpretation of a parameter as text. Inverted commas are required if a text string or variable name contains one or more space characters, so that all characters between the inverted commas are recognized as constituting one parameter.
The following is a description of currently supported script commands, including example parameters.
Create "D:\My File.txt" 1000
Creates the specified file with an initial file size of 1000 bytes. If the file already exists, it is overwritten.
Open "D:\My File.txt"
Open "D:\*.txt"
Opens the specified file(s).
Open C:
Open D:
Opens the specified logical drive.
Open 80h
Open 81h
Open 9Eh
Opens the specified physical media. Floppy disk numbering starts with 00h, fixed and removable drive numbering with 80h, optical media numbering with 9Eh.
Optionally, you may pass a second parameter with the Open command that defines the edit mode in which to open the file or media ("in-place" or "read-only").
CreateBackup
Creates a backup of the active file in its current state.
CreateBackupEx 0 100000 650 true "F:\My backup.whx"
Creates a backup of the active disk, from sector 0 through sector 1,000,000. The backup file will be split automatically at a size of 650 MB. Compression is enabled ("true"). The output file is specified as the last parameter.
If the backup file should not be split, specify 0 as the third parameter. To disable compression, specify "false". To have the Backup Manager automatically assign a filename and place the file in the folder for backup files, specify "" as the last parameter.
Goto 0x128
Goto MyVariable
Moves the current cursor position to the hexadecimal offset 0x128. Alternatively, an existing variable (up to 8 bytes large) can be interpreted as a numeric value, too.
Move -100
Moves the current cursor position 100 bytes back (decimal).
Write "Test"
Write 0x0D0A
Write MyVariable
Writes the four ASCII characters "Test" or the two hexadecimal values "0D0A" at the current position (in overwrite mode) and moves the current position forward accordingly (i.e. by 4 bytes). Can also write the contents of a variable specified as the parameter.
Insert "Test"
Functions just as the "Write" command, but in insert mode. Must only be used with files.
Read MyVariable 10
Reads the 10 bytes from the current position into a variable named "MyVariable". If this variable does not yet exist, it will be created. Up to 16 different variables allowed. Another way to create a variable is the Assign command.
ReadLn MyVariable
Reads from the current position into a variable named "MyVariable" until the next line break is encountered. If the variable already exists, its size will be adjusted accordingly.
Close
Closes the active window without saving.
CloseAll
Closes all windows without saving.
Save
Saves changes to the file or disk in the active window.
SaveAs "C:\New Name.txt"
Saves the file in the active window under the specified path. Specify "?" as the parameter to let the user specify the destination.
SaveAll
Saves changes in all windows.
Exit
Terminates script execution and ends WinHex.
ExitIfNoFilesOpen
Aborts script execution if no files are already opened in WinHex.
Block 100 200
Block "My Variable 1" "My Variable 2"
Defines the block in the active window to run from offset 100 to offset 200 (decimal). Alternatively, existing variables (each up to 8 bytes large) can be interpreted as numeric values.
Block1 0x100
Defines the block beginning to be at the hexadecimal offset 0x100. A variable is allowed as the parameter as well.
Block2 0x200
Defines the block end to be at the hexadecimal offset 0x200. A variable is allowed as the parameter as well.
Copy
Copies the currently defined block into the clipboard. If no block is defined, it works as known from the Copy command in the Edit menu.
Cut
Cuts the currently defined block from the file and puts it into the clipboard.
Remove
Removes the currently defined block from the file.
CopyIntoNewFile "D:\New File.dat"
CopyIntoNewFile "D:\File +MyVariable+.dat"
Copies the currently defined block into the specified new file, without using the clipboard. If no block is defined, it works as known from the Copy command in the Edit menu. Can copy disk sectors as well as files. The new file will not be automatically opened in another edit window. Allows an unlimited number of "+" concatenations in the parameter. A variable name will be interpreted as an integer if not be larger than 2^24 (~16 Mio.). Useful for loops and file recovery.
Paste
Pastes the current clipboard contents at the current position in a file, without changing the current position.
WriteClipboard
Writes the current clipboard contents at the current position in a file or within disk sectors, without changing the current position, by overwriting the data at the current position.
Convert Param1 Param2
Converts the data in the active file from one format into another one. Valid parameters are ANSI, IBM, EBCDIC, Binary, HexASCII, IntelHex, and MotorolaS, in combinations as known from the conventional Convert menu command.
Encrypt "My Password"
Encrypts the active file or disk, or selected block thereof, with the specified key (up to 16 characters long) using the PC1 algorithm (128 bit).
Decrypt "My Password"
Decrypts the active file or disk.
Find "John" [MatchCase MatchWord Down Up BlockOnly SaveAllPos Unicode Wildcards]
Find 0x1234 [Down Up BlockOnly SaveAllPos Wildcards]
Searches in the active window for the name John or the hexadecimal values 0x1234, respectively, and stops at the first occurrence. Other parameters are opional. By default, WinHex searches the entire file/disk. The optional parameters work as known from usual WinHex search options.
ReplaceAll "Jon" "Don" [MatchCase MatchWord Down Up BlockOnly Unicode Wildcards]
ReplaceAll 0x0A 0x0D0A [Down Up BlockOnly Wildcards]
Replaces all occurrences of either a string or hexadecimal values in the active file with something else. Can only be applied to a disk if in in-place mode.
IfFound
A boolean value that depends on whether or not the last Find or ReplaceAll command was successful. Place commands that shall be executed if something was found after the IfFound command.
IfEqual MyVariable "constant string"
IfEqual 0x12345678 MyVariable
IfEqual MyVariable MyOtherVariable
Compares two variables, ASCII strings, or hexadecimal values at the binary level. Comparing two objects with a different length always returns False as the result. If equal, the following commands will be executed.
IfGreater 0x12345678 MyVariable
IfGreater MyVariable MyOtherVariable
Compares two variables and interprets them as integer values (64-bit signed). Such an integer comparison is not appropriate for comparing strings of different lengths alphabetically. If the first one is greater than the second one, the following commands will be executed.
Else
May occur after IfFound or IfEqual. Place commands that shall be executed if nothing was found or if the compared objects are not equal after the Else command.
EndIf
Ends conditional command execution (after IfFound or IfEqual).
{...
ExitLoop
...}
Exits a loop. A loop is defined by braces. Closing braces may be followed by an integer number in square brackets, which determines the number of loops to execute. This is may also be a variable or the keyword "unlimited" (so the loop can only be terminated with an ExitLoop command). Loops must not be nested.
Example of a loop:
{ Write "Loop" }[10] will write the word "Loop" ten times.
Label ContinueHere
Creates a label named "ContinueHere"
JumpTo ContinueHere
Continues script execution with the command following that label.
NextObj
Switches cyclically to the next open window and makes it the "active" window. E.g. if 3 windows are open, and window #3 is active, NextObj will make #1 the active window.
ForAllObjDo
The following block of script commands (until EndDo occurs) will be applied to all open files and disks.
CopyFile C:\A.dat D:\B.dat
Copies the contents of C:\A.dat into the file D:\B.dat.
MoveFile C:\A.dat D:\B.dat
Moves the file C:\A.dat to D:\B.dat.
DeleteFile C:\A.dat
Surprisingly, deletes C:\A.dat.
InitFreeSpace
InitSlackSpace
Clears free space or slack on the current logical drive, respectively, using the currently set initialization settings. InitSlackSpace switches the drive temporarily to in-place mode, thus saving all pending changes.
Assign MyVariable 12345
Assign MyVariable 0x0D0A
Assign MyVariable "I like WinHex"
Assign MyVariable MyOtherVariable
Stores the specified integer number, binary data, ASCII text, or other variable's contents in a variable named "MyVariable". If this variable does not yet exist, it will be created. Up to 16 different variables allowed. Another way to create a variable is the Read command.
Inc MyVariable
Interprets the variable as an integer (if not larger than 8 bytes) and increments it by one. Useful for loops.
Dec MyVariable
Interprets the variable as an integer (if not larger than 8 bytes) and decrements it by one.
MessageBox "Caution"
Displays a message box with the text "Caution" and offers the user an OK and a Cancel button. Pressing the Cancel button will abort script execution.
ExecuteScript "ScriptName"
Executes another script from within a running script, at the current execution point, e.g. depending on a conditional statement. Calls to other scripts may be nested. When the called script is finished, execution of the original script will be resumed with the next command. This feature can help you structure your scripts more clearly.
Turbo On
Turbo Off
In turbo mode, most screen elements are not updated during script execution and you are not able to abort (e.g. by pressing Esc). This accelerates the script by up to 75% if a lot of simple commands such as Move and NextObj are executed in a loop.
Debug
All the following commands must be confirmed individually by the user.
UseLogFile
Error messages are written into the log file "Scripting.log" in the folder for temporary files. These messages are not shown in a message box that requires user interaction. Useful especially when running scripts on unattended remote computers.
CurrentPos
GetSize
unlimited
are keywords that act as a placeholders and may be used where numeric parameters are required. On script execution, CurrentPos stands for the current offset in the active file or disk window and GetSize for its size in bytes. unlimited actually stands for the number 2,147,483,647.
附:一个sample script.whs
// WinHex sample script, demonstrating various script commands.
// Can only be executed by the evaluation version if unchanged.
MessageBox "Attention: all windows will now be closed without prompting."
CloseAll
// Create a file named "abcdefgh.dat" with 123456 bytes in the root directory of drive C:.
// Will overwrite this file in case it already exists.
Create "C:\abcdefgh.dat" 123456
MessageBox "The sample file 'abcdefgh.dat' has been created."
// Write some text at offset 0.
Write "This file was created by a WinHex sample script."
// Write 16 magic hex values at offset 0x100.
Goto 0x100
Write 0x57696E48657820697320677265617421
Move -16
// Now we are back at offset 0x100.
// Open drive C:
Open C:
// To find out whether this drive has a FAT file system, search for
// the string "FAT" in the boot sector. Could also be implemented as
// Goto 0x36
// Read "A three-character variable" 3
// IfEqual "A three-character variable" "FAT"
Block 0 511
Find "FAT" BlockOnly
IfFound
// Search for the directory entry "abcdefghdat". This only works on FAT drives.
MessageBox "Drive C: has a FAT file system. Now looking for the directory entry of 'abcdefgh.dat'."
Find "abcdefghdat"
Else
// Search for the filename "abcdefgh.dat" in Unicode, as stored on NTFS drives.
MessageBox "Drive C: does not have a FAT file system. Now looking for an NTFS entry of 'abcdefgh.dat'."
Find "abcdefgh.dat" Unicode
EndIf
// Now go back to the file.
NextObj
// We know that the only other open window is the file we created,
// since initially all other possibly open windows were closed.
// Convert the file from Binary to HexASCII and back 3 times.
{
Convert Binary HexASCII
Convert HexASCII Binary
}[3]
// Now make drive C: the active window again, to show
// that the directory entry of "abcdefgh.dat" has been
// found.
NextObj
MessageBox "Sample script execution complete. The file has been converted a few times, and its directory entry has hopefully been found in the file system."
WinHex scripts are text files with the filename extension ".whs". They can be edited using any text editor and simply consist of a sequence of commands. It is recommended to enter one command per line only, for reasons of visual clarity. Depending on the command, you may need to specify parameters next to a command. Most commands affect the file or disk presented in the currently active window.
Also see: WinHex API
Script commands are case-insensitive. Comments may occur anywhere in a script file and must be preceded by two slashes. Parameters may be 255 characters long at most. Where in doubt because hex values, text strings (or even integer numbers) are accepted as parameters, you may use inverted commas (quotation marks) to enforce the interpretation of a parameter as text. Inverted commas are required if a text string or variable name contains one or more space characters, so that all characters between the inverted commas are recognized as constituting one parameter.
The following is a description of currently supported script commands, including example parameters.
Create "D:\My File.txt" 1000
Creates the specified file with an initial file size of 1000 bytes. If the file already exists, it is overwritten.
Open "D:\My File.txt"
Open "D:\*.txt"
Opens the specified file(s).
Open C:
Open D:
Opens the specified logical drive.
Open 80h
Open 81h
Open 9Eh
Opens the specified physical media. Floppy disk numbering starts with 00h, fixed and removable drive numbering with 80h, optical media numbering with 9Eh.
Optionally, you may pass a second parameter with the Open command that defines the edit mode in which to open the file or media ("in-place" or "read-only").
CreateBackup
Creates a backup of the active file in its current state.
CreateBackupEx 0 100000 650 true "F:\My backup.whx"
Creates a backup of the active disk, from sector 0 through sector 1,000,000. The backup file will be split automatically at a size of 650 MB. Compression is enabled ("true"). The output file is specified as the last parameter.
If the backup file should not be split, specify 0 as the third parameter. To disable compression, specify "false". To have the Backup Manager automatically assign a filename and place the file in the folder for backup files, specify "" as the last parameter.
Goto 0x128
Goto MyVariable
Moves the current cursor position to the hexadecimal offset 0x128. Alternatively, an existing variable (up to 8 bytes large) can be interpreted as a numeric value, too.
Move -100
Moves the current cursor position 100 bytes back (decimal).
Write "Test"
Write 0x0D0A
Write MyVariable
Writes the four ASCII characters "Test" or the two hexadecimal values "0D0A" at the current position (in overwrite mode) and moves the current position forward accordingly (i.e. by 4 bytes). Can also write the contents of a variable specified as the parameter.
Insert "Test"
Functions just as the "Write" command, but in insert mode. Must only be used with files.
Read MyVariable 10
Reads the 10 bytes from the current position into a variable named "MyVariable". If this variable does not yet exist, it will be created. Up to 16 different variables allowed. Another way to create a variable is the Assign command.
ReadLn MyVariable
Reads from the current position into a variable named "MyVariable" until the next line break is encountered. If the variable already exists, its size will be adjusted accordingly.
Close
Closes the active window without saving.
CloseAll
Closes all windows without saving.
Save
Saves changes to the file or disk in the active window.
SaveAs "C:\New Name.txt"
Saves the file in the active window under the specified path. Specify "?" as the parameter to let the user specify the destination.
SaveAll
Saves changes in all windows.
Exit
Terminates script execution and ends WinHex.
ExitIfNoFilesOpen
Aborts script execution if no files are already opened in WinHex.
Block 100 200
Block "My Variable 1" "My Variable 2"
Defines the block in the active window to run from offset 100 to offset 200 (decimal). Alternatively, existing variables (each up to 8 bytes large) can be interpreted as numeric values.
Block1 0x100
Defines the block beginning to be at the hexadecimal offset 0x100. A variable is allowed as the parameter as well.
Block2 0x200
Defines the block end to be at the hexadecimal offset 0x200. A variable is allowed as the parameter as well.
Copy
Copies the currently defined block into the clipboard. If no block is defined, it works as known from the Copy command in the Edit menu.
Cut
Cuts the currently defined block from the file and puts it into the clipboard.
Remove
Removes the currently defined block from the file.
CopyIntoNewFile "D:\New File.dat"
CopyIntoNewFile "D:\File +MyVariable+.dat"
Copies the currently defined block into the specified new file, without using the clipboard. If no block is defined, it works as known from the Copy command in the Edit menu. Can copy disk sectors as well as files. The new file will not be automatically opened in another edit window. Allows an unlimited number of "+" concatenations in the parameter. A variable name will be interpreted as an integer if not be larger than 2^24 (~16 Mio.). Useful for loops and file recovery.
Paste
Pastes the current clipboard contents at the current position in a file, without changing the current position.
WriteClipboard
Writes the current clipboard contents at the current position in a file or within disk sectors, without changing the current position, by overwriting the data at the current position.
Convert Param1 Param2
Converts the data in the active file from one format into another one. Valid parameters are ANSI, IBM, EBCDIC, Binary, HexASCII, IntelHex, and MotorolaS, in combinations as known from the conventional Convert menu command.
Encrypt "My Password"
Encrypts the active file or disk, or selected block thereof, with the specified key (up to 16 characters long) using the PC1 algorithm (128 bit).
Decrypt "My Password"
Decrypts the active file or disk.
Find "John" [MatchCase MatchWord Down Up BlockOnly SaveAllPos Unicode Wildcards]
Find 0x1234 [Down Up BlockOnly SaveAllPos Wildcards]
Searches in the active window for the name John or the hexadecimal values 0x1234, respectively, and stops at the first occurrence. Other parameters are opional. By default, WinHex searches the entire file/disk. The optional parameters work as known from usual WinHex search options.
ReplaceAll "Jon" "Don" [MatchCase MatchWord Down Up BlockOnly Unicode Wildcards]
ReplaceAll 0x0A 0x0D0A [Down Up BlockOnly Wildcards]
Replaces all occurrences of either a string or hexadecimal values in the active file with something else. Can only be applied to a disk if in in-place mode.
IfFound
A boolean value that depends on whether or not the last Find or ReplaceAll command was successful. Place commands that shall be executed if something was found after the IfFound command.
IfEqual MyVariable "constant string"
IfEqual 0x12345678 MyVariable
IfEqual MyVariable MyOtherVariable
Compares two variables, ASCII strings, or hexadecimal values at the binary level. Comparing two objects with a different length always returns False as the result. If equal, the following commands will be executed.
IfGreater 0x12345678 MyVariable
IfGreater MyVariable MyOtherVariable
Compares two variables and interprets them as integer values (64-bit signed). Such an integer comparison is not appropriate for comparing strings of different lengths alphabetically. If the first one is greater than the second one, the following commands will be executed.
Else
May occur after IfFound or IfEqual. Place commands that shall be executed if nothing was found or if the compared objects are not equal after the Else command.
EndIf
Ends conditional command execution (after IfFound or IfEqual).
{...
ExitLoop
...}
Exits a loop. A loop is defined by braces. Closing braces may be followed by an integer number in square brackets, which determines the number of loops to execute. This is may also be a variable or the keyword "unlimited" (so the loop can only be terminated with an ExitLoop command). Loops must not be nested.
Example of a loop:
{ Write "Loop" }[10] will write the word "Loop" ten times.
Label ContinueHere
Creates a label named "ContinueHere"
JumpTo ContinueHere
Continues script execution with the command following that label.
NextObj
Switches cyclically to the next open window and makes it the "active" window. E.g. if 3 windows are open, and window #3 is active, NextObj will make #1 the active window.
ForAllObjDo
The following block of script commands (until EndDo occurs) will be applied to all open files and disks.
CopyFile C:\A.dat D:\B.dat
Copies the contents of C:\A.dat into the file D:\B.dat.
MoveFile C:\A.dat D:\B.dat
Moves the file C:\A.dat to D:\B.dat.
DeleteFile C:\A.dat
Surprisingly, deletes C:\A.dat.
InitFreeSpace
InitSlackSpace
Clears free space or slack on the current logical drive, respectively, using the currently set initialization settings. InitSlackSpace switches the drive temporarily to in-place mode, thus saving all pending changes.
Assign MyVariable 12345
Assign MyVariable 0x0D0A
Assign MyVariable "I like WinHex"
Assign MyVariable MyOtherVariable
Stores the specified integer number, binary data, ASCII text, or other variable's contents in a variable named "MyVariable". If this variable does not yet exist, it will be created. Up to 16 different variables allowed. Another way to create a variable is the Read command.
Inc MyVariable
Interprets the variable as an integer (if not larger than 8 bytes) and increments it by one. Useful for loops.
Dec MyVariable
Interprets the variable as an integer (if not larger than 8 bytes) and decrements it by one.
MessageBox "Caution"
Displays a message box with the text "Caution" and offers the user an OK and a Cancel button. Pressing the Cancel button will abort script execution.
ExecuteScript "ScriptName"
Executes another script from within a running script, at the current execution point, e.g. depending on a conditional statement. Calls to other scripts may be nested. When the called script is finished, execution of the original script will be resumed with the next command. This feature can help you structure your scripts more clearly.
Turbo On
Turbo Off
In turbo mode, most screen elements are not updated during script execution and you are not able to abort (e.g. by pressing Esc). This accelerates the script by up to 75% if a lot of simple commands such as Move and NextObj are executed in a loop.
Debug
All the following commands must be confirmed individually by the user.
UseLogFile
Error messages are written into the log file "Scripting.log" in the folder for temporary files. These messages are not shown in a message box that requires user interaction. Useful especially when running scripts on unattended remote computers.
CurrentPos
GetSize
unlimited
are keywords that act as a placeholders and may be used where numeric parameters are required. On script execution, CurrentPos stands for the current offset in the active file or disk window and GetSize for its size in bytes. unlimited actually stands for the number 2,147,483,647.
附:一个sample script.whs
// WinHex sample script, demonstrating various script commands.
// Can only be executed by the evaluation version if unchanged.
MessageBox "Attention: all windows will now be closed without prompting."
CloseAll
// Create a file named "abcdefgh.dat" with 123456 bytes in the root directory of drive C:.
// Will overwrite this file in case it already exists.
Create "C:\abcdefgh.dat" 123456
MessageBox "The sample file 'abcdefgh.dat' has been created."
// Write some text at offset 0.
Write "This file was created by a WinHex sample script."
// Write 16 magic hex values at offset 0x100.
Goto 0x100
Write 0x57696E48657820697320677265617421
Move -16
// Now we are back at offset 0x100.
// Open drive C:
Open C:
// To find out whether this drive has a FAT file system, search for
// the string "FAT" in the boot sector. Could also be implemented as
// Goto 0x36
// Read "A three-character variable" 3
// IfEqual "A three-character variable" "FAT"
Block 0 511
Find "FAT" BlockOnly
IfFound
// Search for the directory entry "abcdefghdat". This only works on FAT drives.
MessageBox "Drive C: has a FAT file system. Now looking for the directory entry of 'abcdefgh.dat'."
Find "abcdefghdat"
Else
// Search for the filename "abcdefgh.dat" in Unicode, as stored on NTFS drives.
MessageBox "Drive C: does not have a FAT file system. Now looking for an NTFS entry of 'abcdefgh.dat'."
Find "abcdefgh.dat" Unicode
EndIf
// Now go back to the file.
NextObj
// We know that the only other open window is the file we created,
// since initially all other possibly open windows were closed.
// Convert the file from Binary to HexASCII and back 3 times.
{
Convert Binary HexASCII
Convert HexASCII Binary
}[3]
// Now make drive C: the active window again, to show
// that the directory entry of "abcdefgh.dat" has been
// found.
NextObj
MessageBox "Sample script execution complete. The file has been converted a few times, and its directory entry has hopefully been found in the file system."
2009年3月25日星期三
IT与命运,人生随想
写点严肃的。
我信命!我相信是命运决定的我的性格:我从不认命。
从事IT行业是很奇妙的,它给了我们更宽广、更抽象的思考事物的方式。我的脑子里常常会冒出许多天马行空的想法,在这里面,有一些是关于命运的。
偶然事件:
IT行业是建立在绝对理论基础上的。写一个程序,有一处错误,不管编译多少回,它还是会错,不会神奇地调试通过;操作系统的引导代码被破坏,不管试图启动多少回,系统也还是启动不了;数据被删除,等十天、一百天、一万年都不可能自动跑回来。
从写程序的角度看待代码世界,是不存在偶然事件的。即便是随机函数,也是由某些看似随机的外因(CPU响应时间,鼠标的位置等)引起的。人工智能也是建立在越发复杂、抽象的算法上的,也绝对没有随机性。
换到生活上来,人生的偶然性难道不是算法的复杂造成的吗?
扔一枚硬币,掉下来的是正面还是反面,在掉之前就已经决定了。当然,这可能有太多的因素组成:扔硬币人(程序里的对象)作用在硬币上的力,硬币受到的外因(如风、地球引力)......。其中扔硬币的人在这个事件中所表现的作用力也是由太多复杂的过程、变量、继承影响的,比如肌肉的表现、神经的支配,,这些原因的原因又能追溯到原因的3次方。以此递推,总会找到所有引起这枚硬币正面还是反面的原因来,而这些原因又是绝对事件,非偶然。这样看来,那扔硬币不就是必然事件了吗?
所以,命运是必然的。我一直认为只有努力才能改变命运的想法是命里早就注定的;很多人因为相信算命先生的一席话,错失大好机会,庸庸碌碌一生也是命里早就注定的。那写这篇文章看起来也是命中注定的了。
算法复杂度:
程序员在写一个程序时,常常会遇到这样的情况:确信一段代码绝对不会有漏洞了,但过一段时间却又发现了完全没有想到的错误。或者还有,在解决一个问题的时候,我们绞尽脑汁想出来一个自认为完美的算法,却在一个偶然的机会得到高人的指点,恍然大悟,自己怎么就没想到呢?
是啊。以动物的思维去看待世界,看待人,一定不像以人的思维去看待动物。也许在动物的世界里有另一种“高等”的思维,是脱离生命、价值等的思维模式。但我们不是动物,所以想不出来。当然,我以人的角度去看这个事情,本身又是局限的,相当于白说。
这样看来,每一样东西都是有思维的。人和任何事物一样,不过就是一个可以接受输入的程序段而已,挨打的时候会痛、因为扔硬币会乱想、因为乱想会写下来。那硬币也一样,扔它的时候,它会跳起来;用锤子砸它,它会变扁。当然,我不是说它有佛性,我以人的思维,还是看不透一枚硬币的思维的。
唯心论
如果我们写了一个复杂的程序,在程序里有一个复杂的类,类里封闭了大量的思维过程。再如果这个类实例化了一个对象,它可以应对大量的不同输入的处理,这样,这个对象便生动了起来。就像我们按下键盘的一个A,对象便认为它接收了A。再换个角度思考一下,如果我们用模拟的方式向对象传递一个信号,说按下了键盘上的A,那对象还是会以为外部接口按下了键盘A。
那如果这个对象是人呢?
恭喜你,程序员就是上帝了。
人常常会做梦,做梦的时候一定不会认为是在做梦,所以,保不齐现在就在梦里(别看我,也说你呢!)
程序有时候会有BUG,或者陷入异常。疯子、精神失常者会不会是另一个异常呢?但愿上帝不会结束它(她?他?)。
程序可以不断的调试、重新执行。那整个世界如果是一个复杂的程序(我想不出来程序存在哪里?),重新调试是否意味着时间可以倒流?
那时间又是什么呢?也许就是程序执行时的CPU执行流程。如果没有外部时间的参考,一台PIII在执行一段代码的过程中,对象本身不会感到慢,和P4上执行的过程一样。
程序如果是个死循环呢?
做程序的一个原则就是充分封装,以一个对象的角度看其上层调用是不现实的,最多上层安排一个猜测的过程而已。如果我是这个对象,我的所有想法都是来自上层的设计,那这些想法是真的吗?我不知道。也许上帝正关注着我写这个文章。
我信命!我相信是命运决定的我的性格:我从不认命。
从事IT行业是很奇妙的,它给了我们更宽广、更抽象的思考事物的方式。我的脑子里常常会冒出许多天马行空的想法,在这里面,有一些是关于命运的。
偶然事件:
IT行业是建立在绝对理论基础上的。写一个程序,有一处错误,不管编译多少回,它还是会错,不会神奇地调试通过;操作系统的引导代码被破坏,不管试图启动多少回,系统也还是启动不了;数据被删除,等十天、一百天、一万年都不可能自动跑回来。
从写程序的角度看待代码世界,是不存在偶然事件的。即便是随机函数,也是由某些看似随机的外因(CPU响应时间,鼠标的位置等)引起的。人工智能也是建立在越发复杂、抽象的算法上的,也绝对没有随机性。
换到生活上来,人生的偶然性难道不是算法的复杂造成的吗?
扔一枚硬币,掉下来的是正面还是反面,在掉之前就已经决定了。当然,这可能有太多的因素组成:扔硬币人(程序里的对象)作用在硬币上的力,硬币受到的外因(如风、地球引力)......。其中扔硬币的人在这个事件中所表现的作用力也是由太多复杂的过程、变量、继承影响的,比如肌肉的表现、神经的支配,,这些原因的原因又能追溯到原因的3次方。以此递推,总会找到所有引起这枚硬币正面还是反面的原因来,而这些原因又是绝对事件,非偶然。这样看来,那扔硬币不就是必然事件了吗?
所以,命运是必然的。我一直认为只有努力才能改变命运的想法是命里早就注定的;很多人因为相信算命先生的一席话,错失大好机会,庸庸碌碌一生也是命里早就注定的。那写这篇文章看起来也是命中注定的了。
算法复杂度:
程序员在写一个程序时,常常会遇到这样的情况:确信一段代码绝对不会有漏洞了,但过一段时间却又发现了完全没有想到的错误。或者还有,在解决一个问题的时候,我们绞尽脑汁想出来一个自认为完美的算法,却在一个偶然的机会得到高人的指点,恍然大悟,自己怎么就没想到呢?
是啊。以动物的思维去看待世界,看待人,一定不像以人的思维去看待动物。也许在动物的世界里有另一种“高等”的思维,是脱离生命、价值等的思维模式。但我们不是动物,所以想不出来。当然,我以人的角度去看这个事情,本身又是局限的,相当于白说。
这样看来,每一样东西都是有思维的。人和任何事物一样,不过就是一个可以接受输入的程序段而已,挨打的时候会痛、因为扔硬币会乱想、因为乱想会写下来。那硬币也一样,扔它的时候,它会跳起来;用锤子砸它,它会变扁。当然,我不是说它有佛性,我以人的思维,还是看不透一枚硬币的思维的。
唯心论
如果我们写了一个复杂的程序,在程序里有一个复杂的类,类里封闭了大量的思维过程。再如果这个类实例化了一个对象,它可以应对大量的不同输入的处理,这样,这个对象便生动了起来。就像我们按下键盘的一个A,对象便认为它接收了A。再换个角度思考一下,如果我们用模拟的方式向对象传递一个信号,说按下了键盘上的A,那对象还是会以为外部接口按下了键盘A。
那如果这个对象是人呢?
恭喜你,程序员就是上帝了。
人常常会做梦,做梦的时候一定不会认为是在做梦,所以,保不齐现在就在梦里(别看我,也说你呢!)
程序有时候会有BUG,或者陷入异常。疯子、精神失常者会不会是另一个异常呢?但愿上帝不会结束它(她?他?)。
程序可以不断的调试、重新执行。那整个世界如果是一个复杂的程序(我想不出来程序存在哪里?),重新调试是否意味着时间可以倒流?
那时间又是什么呢?也许就是程序执行时的CPU执行流程。如果没有外部时间的参考,一台PIII在执行一段代码的过程中,对象本身不会感到慢,和P4上执行的过程一样。
程序如果是个死循环呢?
做程序的一个原则就是充分封装,以一个对象的角度看其上层调用是不现实的,最多上层安排一个猜测的过程而已。如果我是这个对象,我的所有想法都是来自上层的设计,那这些想法是真的吗?我不知道。也许上帝正关注着我写这个文章。
手工杀掉双线程、感染所有EXE文件病毒
本文DOC原文、病毒样本、WINHEX脚本打包下载:
下载
作者:张宇,北亚硬盘数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
引言:这是我以前写的一篇文章,算是解决问题的一个总结,一直没有发表,虽然到现在,文中提到的病毒已经是小菜一碟了,但这个解决方法实际就是一个完整的杀毒软件最普通的杀毒算法,也算是抛砖引玉吧,不当之处请多指正。
文中涉及到的文件(除了用到的那几个软件)以及文章的DOC版已上传到附件中。
注意:压缩包里含病毒样本,测试里请断开网络在虚拟机下测试。
手动杀灭 “刘德华病毒” 顽固变种
前些日子,与一起培训的学生照过合影后回到机房,我在我的电脑中开了一个完全共享,希望他们通过网络将照片传过来。过了一会,查看共享目录时,我发现有一个名称为“我的照片”的.EXE文件,当时还纳闷,怎么快就把电子相册做好了?加上我的电脑里安装有及时更新的“卡巴斯基”,所以没多想便双击了那个“我的照片.exe”,随后电脑中出现一幅天王刘德华的照片,单击后退出了。看到并不是想要的合影时,我心想这下可能坏了。电脑正常运行,并没有特别的异常情况,但我心想,一定不会这么简单,先上网查查吧。不查不知道,一查吓一跳,原来这是一个叫做“诡秘变种S”的病毒,大家也把它称为“刘德华病毒”,这种病毒主要通过局域网进行传播,它试图把自己复制到局域网其他用户的共享文件夹里。感染病毒之后,会将自己拷贝到系统目录下,文件名为“svchost.exe”。病毒会修改exe文件的关联方式,这样用户每次运行exe文件的时候都会先运行病毒。通过病毒的接应,黑客可以远程对用户电脑进行控制,任意删除用户电脑上的文件,获取用户存储在电脑上的信息。 看到发作结果这么可怕,于是赶紧着手杀毒。卡巴斯基没有报警,看来只好用其他杀毒软件了,于是我试了试瑞星、金山等杀毒厂商提供的免费查毒功能,结果发现,没有一个可以查到。看来我所感染的这个是老式“诡秘变种S”的变种,目前还未被各杀毒厂商发现,看到其可能会获取用户资料,心里又万分焦急。无耐之下,尝试手动杀毒。经过一番努力,病毒基本处理干净,作为对大家解决病毒、木马问题的参考,写下我的处理过程。 首先作为验证,我到C盘WINDOWS目录查找是否有svchost.exe文件,没有,可能是隐藏文件,于是想显示所有文件再查。点击资源管理器中的文件夹选项后,出现如下情况:
竟然不可以修改显示“隐藏文件和系统文件”属性,看来病毒已经在注册表作了手脚。试着运行REGEDIT.EXE,可以进入,进入后查看HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\Advanced\Folder\Hidden,发现其下没有SHOWALL项,看来是病毒删除了。先按照下面注册表文件还原:Windows Registry Editor Version 5.00[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\Advanced\Folder\Hidden\SHOWALL]"RegPath"="Software\\Microsoft\\Windows\\CurrentVersion\\Explorer\\Advanced""Text"="显示所有文件和文件夹""Type"="radio""CheckedValue"=dword:00000001"ValueName"="Hidden""DefaultValue"=dword:00000002"HKeyRoot"=dword:80000001"HelpID"="shell.hlp#51105" 更改注册表后退出,再进入文件夹选项时已经出现了“显示所有文件和文件夹”的选项,选中后,立刻进入windows目录下,果然发现了病毒体svchost.exe(操作系统的svchost.exe并没有放在windows目录下),但过了一会再查看,发现又无法显示隐藏和系统文件了,删除svchost.exe文件时提示文件保护,无法删除。综合推断,病毒驻留程序会隔一段时间监视注册表的改动(其实是不管三七二十一重写特定键值)。按下“ctrl+alt+del”键进入任务管理器后查看,有多个svchost(有几个是系统核心进程),试着逐个结束,未果,看来病毒有自我保护技术(双线程或其他吧,没有具体分析) 再次进入注册表编辑器,发现启动项中已加入了键名为”microsoft”,键值为”c:\windows\svchost.exe”的运行键。同时发现果然所有的.exe文件的关联方式都被改为了“C:\WINDOWS\svchost.exe "%1" %*” 运行注册表监视程序Regmon,发现病毒会隔一段时间强行改动以下几个重要键值:自动运行、.EXE关联、是否显示隐藏文件、是否显示文件扩展名,以及添加“HKLM\SOFTWARE\mysoft”项。 驻留程序无法结束,注册表不能改动,文件又无法删除,这可该怎么办?好办,请出WINHEX->著名磁盘编辑软件,主要的解决思路是利用WINHEX对磁盘进行编辑,从而对病毒体进行破坏,导致病毒体无法正常工作。首先打开REGEDIT.EXE,导出.exe的关联项,并修改为正常(自己后期编辑也可以),以防破坏病毒体后所有EXE文件打不开。下边是必改键值的REG文件的内容:Windows Registry Editor Version 5.00[HKEY_CLASSES_ROOT\exefile\shell\open\command]@="\"%1\" %*" 带毒状态下打开WINHEX,单击”TOOLS”下的”open disk”菜单,选择”logical drives”下的”Fixed drive (c)” 打开目录浏览器(access菜单旁边,如下图)
在winhex的目录浏览器中进入WINDOWS目录,找到” svchost.exe” ,在其目录条目上双击定位到SVCHOST.EXE文件在磁盘上的开始位置。接着在开始位置单击鼠标右键,选择”beginning of block” ,再向后翻3-8个左右的扇区,找个位置单击鼠标右键,选择” end of block”。紧跟着在BLOCK区的任意一处位置单击鼠标右键,选择”fill block”,填充全0值。这时候”svchost.exe”已经被破坏。 接着重启计算机,发现弹出很多错误对话框,这是正常的,因为.exe的关联已经损坏,所以正常开机执行的启动程序都不能正常工作了。无所谓,操作系统还可以正常工作。随后直接双击我们备份好的关联.EXE的REG文件,即可运行所有.EXE文件。 运行REGEDIT,删除自动运行里病毒的启动项。 删除”C:\WINDOWS\SVCHOST.EXE” 在系统中打开隐藏文件,查找大小为759,296个字节的.EXE文件,确定其同样为病毒体时,删除。 至此病毒应该已经手动杀掉了,我在后来的几次虚拟机的试验中也确实发现已经干净了,但我真实的感染案例中却远没这么简单。 正常运行了几天吧。我要安装一个软件,其安装程序在我的E盘,转到E盘执行SETUP后,发现怎么也装不上,老提示参数错误。反复重试后,猛然发现,在双击SETUP的同时,目录下自动生成了一个半透明的隐藏文件”setup .exe”(之前杀毒后已打开显示隐藏文件开关,此”SETUP .EXE”文件名中有一空格), 对比真正的文件,发现我E盘绝大部分EXE文件都被病毒修改,我又查了一下其他分区,发现除了C盘(系统分区)以外,别的分区均有被病毒修改的.EXE文件。仔细研究后发现,病毒对.EXE的修改方法是:病毒文件+好的.EXE文件+可能的12个字节,时间等属性不变,但大小会增加。 当运行任一感染的.EXE文件后,其中的病毒体会首先执行,而后释放出正常的.EXE,执行正常的.EXE文件,执行后再将其删除,所以事实上病毒已再次发作。不得已,重复前面过程,将病毒从内存中清除出去,再着手修正感染的每个.EXE文件。要想修改每个被感染的.EXE文件,可不是件容易的事,又试了一下国内几个著名的杀毒软件,还是杀不掉,没办法,一边将病毒提交给各大杀毒厂商,一边自己动手处理。(截止此文写作,瑞星回复,他们已将笔者提交的特征码加入其新病毒库,经验证,的确已经可以查到) 由于没有很好的现成工具能处理这么一大片文件,所以再次请出WINHEX(好强大的功能),我用WINHEX提供的脚本功能做了个专杀工具,虽然WINHEX提供的语法不是太严谨,但总算是可以实现要求了。 首先我确保WINHEX没有被感染(不行可以重新安装一下),然后在C盘建立一个杀毒用的临时目录,如TEMP,然后进入命令提示符状态,执行: dir /b /s d:*.exe >c:\temp\d.ls dir /b /s e:*.exe >c:\temp\e.ls…… 然后,在TEMP目录下用记事本编写两个扩展名为.WHX的文件 //main.whx的内容: Closeall //接受列表文件,如C:\TEMP\D.LS,也可采用相对路径 GetUserInput lspath "请输入杀毒的列表文件路径:" //打开列表文件 Open lspath Assign pathcharnum 0 SetVarSize pathcharnum 2 { //从列表文件中读内容,如果遇到回车(0x0d0a)就把前面的字符加入变量中 //同时清除此段内容,由于WINHEX语法所限,先将选中的.EXE文件的字符数写在路 //径的后面(更改0x0d0a),以此限定变量的字符数 Read tempA 2 Move -1 IfEqual tempA 0x0D0A Move -1 Write pathcharnum Assign pathcharnum 0 SetVarSize pathcharnum 2 //WINHEX目前无法实现相同语法结构的嵌套,所以用调用另一脚本的方法实现 ExecuteScript "kill.whs" Else Inc pathcharnum EndIf }[unlimited] //kill.whx的内容: move -2 Read pathcharnumt 2 goto 0 Read path pathcharnumt Block 0 (pathcharnumt+1) Remove goto 0 open path Assign estimate 0 Assign TempB 0 Assign FileSize GetSize //若打开文件大小小于病毒体,直接跳过,处理下一个文件 IfGreater (0xB95ff-FileSize) 0 JumpTo ContinueHere EndIf //特征判断 block 0x100 0x10f Find 0x504500004C010800195E422A00000000 BlockOnly IfFound Inc estimate EndIf //特征判断 block 0x5e0 0x5ef Find 0x60664000203940005C3940001154496E BlockOnly IfFound Inc estimate EndIf //特征判断 block 0x1900 0x190f Find 0x010514164A00833D14164A000C0F8D4C BlockOnly IfFound Inc estimate EndIf //特征判断 block 0x9000 0x900f Find 0xC0045BC383E8048B0083E804C38D4000 BlockOnly IfFound Inc estimate EndIf //特征判断 block 0x10000 0x1000f Find 0x55F88D45D4E8A2E3FFFF668B45D46625 BlockOnly IfFound Inc estimate EndIf //特征判断 block 0x200b0 0x200bf Find 0x8BC6E86930FEFF5E5BC38BC083C00850 BlockOnly IfFound Inc estimate EndIf //特征判断 block 0x30000 0x3000f Find 0x8B08FF91CC000000EB228B45FC8B4010 BlockOnly IfFound Inc estimate EndIf //特征判断 block 0x40000 0x4000f Find 0x8BD38B83D4010000FF93D00100005F5E BlockOnly IfFound Inc estimate EndIf //特征判断 block 0x50000 0x5000f Find 0x6C7911706F44656661756C7453697A65 BlockOnly IfFound Inc estimate EndIf //特征判断 block 0x60000 0x6000f Find 0x8B10FF12837D08007407C74324010000 BlockOnly IfFound Inc estimate EndIf //特征判断,判断结尾是否是病毒填充的12个字节 block (FileSize-12) (FileSize-1) Find 0xE903000000960B0044444444 BlockOnly IfFound Assign TempB 1 EndIf //处理最后12个字节,如果符合病毒特征,移除! IfGreater estimate*TempB 10 block (FileSize-12) (FileSize-1) Remove EndIf //处理病毒附加的病毒头,如果符合病毒特征,移除! IfEqual estimate 10 block 0x0 0xB95FF Remove EndIf //保存更改 save Label ContinueHere //关闭文件 Close 编辑完这两个文件后,双击MAIN.WHX,执行WINHEX的脚本,很快脚本执行完毕,再进入磁盘查看.EXE文件时,发现病毒已被完全清除,直到现在,未发现异常情况。回想杀灭此病毒的过程,的确是花费了很大心思,写下来,希望整个流程对读者对付病毒或其他方面有帮助。
北亚数据恢复中心 张宇
http://www.sjhf.net
下载
作者:张宇,北亚硬盘数据恢复中心,转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
引言:这是我以前写的一篇文章,算是解决问题的一个总结,一直没有发表,虽然到现在,文中提到的病毒已经是小菜一碟了,但这个解决方法实际就是一个完整的杀毒软件最普通的杀毒算法,也算是抛砖引玉吧,不当之处请多指正。
文中涉及到的文件(除了用到的那几个软件)以及文章的DOC版已上传到附件中。
注意:压缩包里含病毒样本,测试里请断开网络在虚拟机下测试。
手动杀灭 “刘德华病毒” 顽固变种
前些日子,与一起培训的学生照过合影后回到机房,我在我的电脑中开了一个完全共享,希望他们通过网络将照片传过来。过了一会,查看共享目录时,我发现有一个名称为“我的照片”的.EXE文件,当时还纳闷,怎么快就把电子相册做好了?加上我的电脑里安装有及时更新的“卡巴斯基”,所以没多想便双击了那个“我的照片.exe”,随后电脑中出现一幅天王刘德华的照片,单击后退出了。看到并不是想要的合影时,我心想这下可能坏了。电脑正常运行,并没有特别的异常情况,但我心想,一定不会这么简单,先上网查查吧。不查不知道,一查吓一跳,原来这是一个叫做“诡秘变种S”的病毒,大家也把它称为“刘德华病毒”,这种病毒主要通过局域网进行传播,它试图把自己复制到局域网其他用户的共享文件夹里。感染病毒之后,会将自己拷贝到系统目录下,文件名为“svchost.exe”。病毒会修改exe文件的关联方式,这样用户每次运行exe文件的时候都会先运行病毒。通过病毒的接应,黑客可以远程对用户电脑进行控制,任意删除用户电脑上的文件,获取用户存储在电脑上的信息。 看到发作结果这么可怕,于是赶紧着手杀毒。卡巴斯基没有报警,看来只好用其他杀毒软件了,于是我试了试瑞星、金山等杀毒厂商提供的免费查毒功能,结果发现,没有一个可以查到。看来我所感染的这个是老式“诡秘变种S”的变种,目前还未被各杀毒厂商发现,看到其可能会获取用户资料,心里又万分焦急。无耐之下,尝试手动杀毒。经过一番努力,病毒基本处理干净,作为对大家解决病毒、木马问题的参考,写下我的处理过程。 首先作为验证,我到C盘WINDOWS目录查找是否有svchost.exe文件,没有,可能是隐藏文件,于是想显示所有文件再查。点击资源管理器中的文件夹选项后,出现如下情况:
竟然不可以修改显示“隐藏文件和系统文件”属性,看来病毒已经在注册表作了手脚。试着运行REGEDIT.EXE,可以进入,进入后查看HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\Advanced\Folder\Hidden,发现其下没有SHOWALL项,看来是病毒删除了。先按照下面注册表文件还原:Windows Registry Editor Version 5.00[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\Advanced\Folder\Hidden\SHOWALL]"RegPath"="Software\\Microsoft\\Windows\\CurrentVersion\\Explorer\\Advanced""Text"="显示所有文件和文件夹""Type"="radio""CheckedValue"=dword:00000001"ValueName"="Hidden""DefaultValue"=dword:00000002"HKeyRoot"=dword:80000001"HelpID"="shell.hlp#51105" 更改注册表后退出,再进入文件夹选项时已经出现了“显示所有文件和文件夹”的选项,选中后,立刻进入windows目录下,果然发现了病毒体svchost.exe(操作系统的svchost.exe并没有放在windows目录下),但过了一会再查看,发现又无法显示隐藏和系统文件了,删除svchost.exe文件时提示文件保护,无法删除。综合推断,病毒驻留程序会隔一段时间监视注册表的改动(其实是不管三七二十一重写特定键值)。按下“ctrl+alt+del”键进入任务管理器后查看,有多个svchost(有几个是系统核心进程),试着逐个结束,未果,看来病毒有自我保护技术(双线程或其他吧,没有具体分析) 再次进入注册表编辑器,发现启动项中已加入了键名为”microsoft”,键值为”c:\windows\svchost.exe”的运行键。同时发现果然所有的.exe文件的关联方式都被改为了“C:\WINDOWS\svchost.exe "%1" %*” 运行注册表监视程序Regmon,发现病毒会隔一段时间强行改动以下几个重要键值:自动运行、.EXE关联、是否显示隐藏文件、是否显示文件扩展名,以及添加“HKLM\SOFTWARE\mysoft”项。 驻留程序无法结束,注册表不能改动,文件又无法删除,这可该怎么办?好办,请出WINHEX->著名磁盘编辑软件,主要的解决思路是利用WINHEX对磁盘进行编辑,从而对病毒体进行破坏,导致病毒体无法正常工作。首先打开REGEDIT.EXE,导出.exe的关联项,并修改为正常(自己后期编辑也可以),以防破坏病毒体后所有EXE文件打不开。下边是必改键值的REG文件的内容:Windows Registry Editor Version 5.00[HKEY_CLASSES_ROOT\exefile\shell\open\command]@="\"%1\" %*" 带毒状态下打开WINHEX,单击”TOOLS”下的”open disk”菜单,选择”logical drives”下的”Fixed drive (c)” 打开目录浏览器(access菜单旁边,如下图)
在winhex的目录浏览器中进入WINDOWS目录,找到” svchost.exe” ,在其目录条目上双击定位到SVCHOST.EXE文件在磁盘上的开始位置。接着在开始位置单击鼠标右键,选择”beginning of block” ,再向后翻3-8个左右的扇区,找个位置单击鼠标右键,选择” end of block”。紧跟着在BLOCK区的任意一处位置单击鼠标右键,选择”fill block”,填充全0值。这时候”svchost.exe”已经被破坏。 接着重启计算机,发现弹出很多错误对话框,这是正常的,因为.exe的关联已经损坏,所以正常开机执行的启动程序都不能正常工作了。无所谓,操作系统还可以正常工作。随后直接双击我们备份好的关联.EXE的REG文件,即可运行所有.EXE文件。 运行REGEDIT,删除自动运行里病毒的启动项。 删除”C:\WINDOWS\SVCHOST.EXE” 在系统中打开隐藏文件,查找大小为759,296个字节的.EXE文件,确定其同样为病毒体时,删除。 至此病毒应该已经手动杀掉了,我在后来的几次虚拟机的试验中也确实发现已经干净了,但我真实的感染案例中却远没这么简单。 正常运行了几天吧。我要安装一个软件,其安装程序在我的E盘,转到E盘执行SETUP后,发现怎么也装不上,老提示参数错误。反复重试后,猛然发现,在双击SETUP的同时,目录下自动生成了一个半透明的隐藏文件”setup .exe”(之前杀毒后已打开显示隐藏文件开关,此”SETUP .EXE”文件名中有一空格), 对比真正的文件,发现我E盘绝大部分EXE文件都被病毒修改,我又查了一下其他分区,发现除了C盘(系统分区)以外,别的分区均有被病毒修改的.EXE文件。仔细研究后发现,病毒对.EXE的修改方法是:病毒文件+好的.EXE文件+可能的12个字节,时间等属性不变,但大小会增加。 当运行任一感染的.EXE文件后,其中的病毒体会首先执行,而后释放出正常的.EXE,执行正常的.EXE文件,执行后再将其删除,所以事实上病毒已再次发作。不得已,重复前面过程,将病毒从内存中清除出去,再着手修正感染的每个.EXE文件。要想修改每个被感染的.EXE文件,可不是件容易的事,又试了一下国内几个著名的杀毒软件,还是杀不掉,没办法,一边将病毒提交给各大杀毒厂商,一边自己动手处理。(截止此文写作,瑞星回复,他们已将笔者提交的特征码加入其新病毒库,经验证,的确已经可以查到) 由于没有很好的现成工具能处理这么一大片文件,所以再次请出WINHEX(好强大的功能),我用WINHEX提供的脚本功能做了个专杀工具,虽然WINHEX提供的语法不是太严谨,但总算是可以实现要求了。 首先我确保WINHEX没有被感染(不行可以重新安装一下),然后在C盘建立一个杀毒用的临时目录,如TEMP,然后进入命令提示符状态,执行: dir /b /s d:*.exe >c:\temp\d.ls dir /b /s e:*.exe >c:\temp\e.ls…… 然后,在TEMP目录下用记事本编写两个扩展名为.WHX的文件 //main.whx的内容: Closeall //接受列表文件,如C:\TEMP\D.LS,也可采用相对路径 GetUserInput lspath "请输入杀毒的列表文件路径:" //打开列表文件 Open lspath Assign pathcharnum 0 SetVarSize pathcharnum 2 { //从列表文件中读内容,如果遇到回车(0x0d0a)就把前面的字符加入变量中 //同时清除此段内容,由于WINHEX语法所限,先将选中的.EXE文件的字符数写在路 //径的后面(更改0x0d0a),以此限定变量的字符数 Read tempA 2 Move -1 IfEqual tempA 0x0D0A Move -1 Write pathcharnum Assign pathcharnum 0 SetVarSize pathcharnum 2 //WINHEX目前无法实现相同语法结构的嵌套,所以用调用另一脚本的方法实现 ExecuteScript "kill.whs" Else Inc pathcharnum EndIf }[unlimited] //kill.whx的内容: move -2 Read pathcharnumt 2 goto 0 Read path pathcharnumt Block 0 (pathcharnumt+1) Remove goto 0 open path Assign estimate 0 Assign TempB 0 Assign FileSize GetSize //若打开文件大小小于病毒体,直接跳过,处理下一个文件 IfGreater (0xB95ff-FileSize) 0 JumpTo ContinueHere EndIf //特征判断 block 0x100 0x10f Find 0x504500004C010800195E422A00000000 BlockOnly IfFound Inc estimate EndIf //特征判断 block 0x5e0 0x5ef Find 0x60664000203940005C3940001154496E BlockOnly IfFound Inc estimate EndIf //特征判断 block 0x1900 0x190f Find 0x010514164A00833D14164A000C0F8D4C BlockOnly IfFound Inc estimate EndIf //特征判断 block 0x9000 0x900f Find 0xC0045BC383E8048B0083E804C38D4000 BlockOnly IfFound Inc estimate EndIf //特征判断 block 0x10000 0x1000f Find 0x55F88D45D4E8A2E3FFFF668B45D46625 BlockOnly IfFound Inc estimate EndIf //特征判断 block 0x200b0 0x200bf Find 0x8BC6E86930FEFF5E5BC38BC083C00850 BlockOnly IfFound Inc estimate EndIf //特征判断 block 0x30000 0x3000f Find 0x8B08FF91CC000000EB228B45FC8B4010 BlockOnly IfFound Inc estimate EndIf //特征判断 block 0x40000 0x4000f Find 0x8BD38B83D4010000FF93D00100005F5E BlockOnly IfFound Inc estimate EndIf //特征判断 block 0x50000 0x5000f Find 0x6C7911706F44656661756C7453697A65 BlockOnly IfFound Inc estimate EndIf //特征判断 block 0x60000 0x6000f Find 0x8B10FF12837D08007407C74324010000 BlockOnly IfFound Inc estimate EndIf //特征判断,判断结尾是否是病毒填充的12个字节 block (FileSize-12) (FileSize-1) Find 0xE903000000960B0044444444 BlockOnly IfFound Assign TempB 1 EndIf //处理最后12个字节,如果符合病毒特征,移除! IfGreater estimate*TempB 10 block (FileSize-12) (FileSize-1) Remove EndIf //处理病毒附加的病毒头,如果符合病毒特征,移除! IfEqual estimate 10 block 0x0 0xB95FF Remove EndIf //保存更改 save Label ContinueHere //关闭文件 Close 编辑完这两个文件后,双击MAIN.WHX,执行WINHEX的脚本,很快脚本执行完毕,再进入磁盘查看.EXE文件时,发现病毒已被完全清除,直到现在,未发现异常情况。回想杀灭此病毒的过程,的确是花费了很大心思,写下来,希望整个流程对读者对付病毒或其他方面有帮助。
北亚数据恢复中心 张宇
http://www.sjhf.net
2009年3月23日星期一
一个小型数据安全解决方案
作者:张宇,北亚硬盘数据恢复中心(http://www.bysjhf.com),转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
小型企业或者数据比较重要的个人,往往在数据应用与备份方面有很大困惑,如何更安全高效、低成本地利用计算机进行数据应用是很难的。如果仅仅用一台具备单硬盘的电脑进行数据处理,明显是不安全的,逻辑故障、误操作和物理故障任何一个突发事件都会让使用者手足无措。如果用U盘、移动硬盘或者甚至用另一台电脑进行数据备份,也仅仅是降低风险而已,并未从根本上解决问题,诸如同步问题、物理故障的隐患还是会带来太多的不方便。
我们需要解决以下几个问题:避免数据灾难、备份方便、投入少,可选:加密,为此,我们设计一个简单的方案来实施。
大致附加设备:一台PC构建的NAS+Iscsi设备,含RAID控制器,用作备份空间用。
使用iscsi或nas协议将用户工作机连接到备份机上。
利用特定软件,设定备份方案向NAS设备进行数据备份。
如果有需求,辅助安全的加密手段。
NAS中应该具备千M网卡、并可以很好的构建支持RAID。一个很好的示例,可以用DELL准系统,像DELL 775,DELL SC1430,CPU及内存一般即可(NAS并不需要太大的事务处理能力),如果觉得板载的RAID性能不好的话,可以买一些支持独立的RAID卡(硬卡,含处理单元及独立缓冲,目前DELL PERC SAS 5I/6I可在千元内买到)。磁盘空间方面,可以视需求部署适当的RAID方案,可用两块硬盘部署RAID1,或者用3块以上硬盘部署RAID5。然后为这台机器安装NAS系统,如FREENAS、Openfiler。
个人终端,以WINDOWS为例,首先可以通过iscsi或samba将备份空间连至工作机,备份时可以采用Second Copy、Super.Flexible.File.Synchronizer这样的软件部署备份方案(稍后进行详述)。
安全方面,可以用基于Second Copy的加密压缩备份,或Super.Flexible.File.Synchronizer的加密备份,或者使用true crypt、pgp等加密层进行备份。
小型企业或者数据比较重要的个人,往往在数据应用与备份方面有很大困惑,如何更安全高效、低成本地利用计算机进行数据应用是很难的。如果仅仅用一台具备单硬盘的电脑进行数据处理,明显是不安全的,逻辑故障、误操作和物理故障任何一个突发事件都会让使用者手足无措。如果用U盘、移动硬盘或者甚至用另一台电脑进行数据备份,也仅仅是降低风险而已,并未从根本上解决问题,诸如同步问题、物理故障的隐患还是会带来太多的不方便。
我们需要解决以下几个问题:避免数据灾难、备份方便、投入少,可选:加密,为此,我们设计一个简单的方案来实施。
大致附加设备:一台PC构建的NAS+Iscsi设备,含RAID控制器,用作备份空间用。
使用iscsi或nas协议将用户工作机连接到备份机上。
利用特定软件,设定备份方案向NAS设备进行数据备份。
如果有需求,辅助安全的加密手段。
NAS中应该具备千M网卡、并可以很好的构建支持RAID。一个很好的示例,可以用DELL准系统,像DELL 775,DELL SC1430,CPU及内存一般即可(NAS并不需要太大的事务处理能力),如果觉得板载的RAID性能不好的话,可以买一些支持独立的RAID卡(硬卡,含处理单元及独立缓冲,目前DELL PERC SAS 5I/6I可在千元内买到)。磁盘空间方面,可以视需求部署适当的RAID方案,可用两块硬盘部署RAID1,或者用3块以上硬盘部署RAID5。然后为这台机器安装NAS系统,如FREENAS、Openfiler。
个人终端,以WINDOWS为例,首先可以通过iscsi或samba将备份空间连至工作机,备份时可以采用Second Copy、Super.Flexible.File.Synchronizer这样的软件部署备份方案(稍后进行详述)。
安全方面,可以用基于Second Copy的加密压缩备份,或Super.Flexible.File.Synchronizer的加密备份,或者使用true crypt、pgp等加密层进行备份。
2009年3月22日星期日
三种VMware数据备份和恢复方法
转自:http://server.doit.com.cn/article/2008/1126/1335170.shtml
由北亚数据恢复中心(http://www.sjhf.net)整理。
导读:服务器虚拟化,尤其是VMware形式的服务器虚拟化使IT人员获益良多,这么说一点也不为过。据我们所见,服务器虚拟化能解决服务器扩张、资源消耗、服务器扩张、能源消耗、高可用性等相关问题。
服务器虚拟化,尤其是VMware形式的服务器虚拟化使IT人员获益良多,这么说一点也不为过。据我们所见,服务器虚拟化能解决服务器扩张、资源消耗、服务器扩张、能源消耗、高可用性等相关问题。服务器虚拟化也使我们有更多的时间解决其它的迫切问题,如企业资源预案升级、存储项目再三迁移或者为什么《星舰迷航记 11》要到2009年才上映。
尽管VMware提供封装技术和抽象技术,使我们受益匪浅,但数据保护领域发生的基本变革也带来了各项挑战。即使出现了VMware虚拟化,备份人员依然是牢骚最多的IT人员。最大的挑战在于保证数据的一致性,解决VMware物理资源过度消耗的问题。
VMware能将物理服务器封装成大型的硬盘图像文件--虚拟机磁盘格式(VMDK)文件,因此我们不禁认为:备份整台服务器应该和备份这些VMDK文件(当然也包括相关的配置文件)一样简单。
但是在大多数情况下,事实并非如此。除非已经关闭虚拟机(VM),否则,在运行状态下备份VM不能覆盖所有文件。换句话说,这种备份方式不能保证数据的一致性,因而也不能保证已恢复的VM包含足够的精确信息,不能说明服务器已成功恢复。
至于资源过度消耗的问题,这是虚拟化的副作用。利用VMware使系统虚拟化的一个关键原因是,将资源消耗集中在较少的物理服务器中,从而减少大多数IT服务器架构都存在的空闲周期。但是,这么也做带来了不良影响--无法找到足够资源,使数据备份不受阻碍地运行。
备份触到了VMware内部的脆弱之处:VMware处理过量磁盘和网络I/O的能力很弱。实际上,决定是否将物理服务器虚拟化取决于物理服务器中的磁盘密度、网络I/O。毋庸置疑,备份负载是VMware服务器承担的最大负载。
但是,的确有方法能解决这些问题,并且在某些情况下,比标准的物理服务器备份和恢复方法更加出众。但是,人们对这些方法存在一些误解,对第三方备份/恢复产品提供的实施措施也存在误解。实际上,许多管理员依然缺乏有效实现备份和恢复的方法,道路充满挫折。
方法1:在每个VM中安装本地备份程序
工作原理:这是一种传统的备份方法,在每个VM中安装备份程序,就像以前在每台物理服务器中安装备份程序。如下图所示,数据通过LAN流入备份/恢复设施,以往在本地物理服务器中安装备份程序时,数据流向也如此。
这种方法的优点如下:
备份程序的安装和配置与在物理服务器中的安装和配置十分相似,所以无需专门技巧和程式变化。
恢复过程没有发生变化,与将文件恢复到物理服务器的过程十分相似。
这样,就有可能恢复文件;这一点在我们采用其它方法时显得更加重要。
也有可能实现完全备份和增量备份,同样,在我们讨论其它方法时,这一点显得尤为重要。
如果你采用专门的应用感知备份程序,如SQL或Exchange,这将有助于实现应用程序数据的一致性,由此实现的备份在应用程序上具有一致性。
这种方法的缺点如下:
由于所有的备份都在同一台服务器中运行,因而你需要十分小心,不要过度消耗VMware主机资源。
尽管服务器能封装成少量的大型VMDK文件,但备份程序对此一无所知,也就不能利用这一点提供快速的备份或恢复能力;而进行灾难恢复时,需要快速、全面地恢复服务器,从这点上讲,这种方法价值不大。
部署技巧
在物理服务器中,同时运行数据备份可能问题不大,因为物理服务器具有充足的闲置资源,但是对VMware虚拟架构而言,闲置资源已得到充分利用,多个备份操作就有可能阻塞物理服务器。从而,在进行虚拟化以后,应该修改备份手册,通过备份窗口避免资源过度重叠。
一个VM只允许一条数据流。VM的VMDK文件通常寄存在一个VMFS卷中,多条数据流操作很容易覆盖VMFS卷。因此,除非VMDK文件隔离在独立卷(RDM、 iSCSI LUN、或独立的VMFS卷)中,否则备份就应该单流运行,而不是多流运行。
方法2:ESX Service Console中安装备份程序
工作原理:这种方法是在ESX Service Console在安装备份程序,按下图备份VM中潜在的VMDK文件组。Service Console采用红帽子Linux操作系统,因此能够使用Linux备份程序。
这种方法的优点包括:
只需一个备份程序就能备份所有的VM,而不是一台VM配备一个备份程序。
通过这种方法,VM资源能完全备份,只需简单备份少量的大型VMDK文件。
图像能快速恢复,因为只需恢复大型图像,而不必查找大量的小型图像。
这种方法的缺点包括:
需要脚本才能自动关闭、快照和启动VM。为了保证备份过程应用程序数据的一致性,必须这么做。
不可能恢复文件,这种方法只能备份和恢复图像。另外,这也意味着不能实现增量备份。
VNware指出,其开发流程包括从ESX Server移除Service Console。VMware的ESX Server 3i在这一点上迈出了第一步。
部署技巧
为了保证应用程序的一致性,在备份VMDK之前应该关闭VM。
VMDK文件在备份窗口中静止不动。
很不幸,备份过程中VM失去效用。
VMDK文件利用Service Console中的备份程序进行备份。
如果不能关机,可以利用VMware快照功能拍摄运行中的VM,获取即时备份。
备份数据停留在相同的状态,因而不能保证数据的一致性。
同样,实现自动化也需要脚本。
不是所有的备份程序都支持这种方法,所以你需要事先进行调查。
对于应用程序数据一致性的备份,利用VSS使应用程序在备份之前停止运行。但是,这需要非常复杂的脚本。
你可以利用ESX Service Console 中的VCB设施,获取运行状态下虚拟机的快照:
vcbMounter设施:
创建VM的静态快照。
将快照投射到一组文件中,文件可能处于控制台的本地目录中,也可能处于LAN的远程目录中。
利用ESX控制台支持的备份软件对本地文件进行备份和恢复。
vcbRestore设施:
将VM恢复到初始站点或者其它站点,
如果你决定冒险采用脚本技术,就会发现错误校验和更正是脚本技术最难的一个方面,需要编写大量代码。
方法3:VMware集中备份(VCB-Proxy)
工作原理:这种方法涉及一组VMware设施,通常称为VMware集中备份。这种方法使集中的Windows 2003代理服务器中的非LAN备份与相同的SAN卷相连,称为ESX Server。随后,数据通过第三方备份软件传送到代理服务器中,作为后序备份。这种方法比上述两种方法更为复杂,包括以下组件:
备份代理服务器:
服务器能与VMware主机访问相同的卷。
代理服务器中加载/输出VMDK文件的图像。
这种加载/输出图像通过寄存在代理服务器中的备份程序实现备份。
VCB框架:
ESX服务器中的"同步推动器"能刷新文件系统,创建快照。
VCB代理服务器中的"vLUN推动器"允许服务器中存在VMDK文件。
采用VCB自动工作流,命令行设施(vcbMounter/vcbRestore)发挥作用。
备份软件集成模块:
模块集成到VCB框架的组件中。
VMware和备份程序都能开发并支持这种模块。
备份程序之间的集成和使用变量相对简单。
在此点击,查看采用备份代理服务器的VMware集中备份示意图。
采用备份代理服务器的VMware集中备份能够执行非LAN文件备份和非LAN图像备份。但是,这两种方法的实现途径截然不同。
VCB文件备份/恢复是在VCB代理服务器中加载VMDK文件,具体步骤如下:
1备份工作要求VCB框架获取VM快照,在VCB代理服务器中加载VB快照,加载路径包括SAN、C:mnt等。
2利用备份程序备份(完全、增量、差异备份)目录/文件。
3备份程序要求VCB框架卸载VM快照,使VM不再具有快照功能。
4通过安装在VM中的备份程序,文件经由LAN恢复到初始VM中。
在此点击,查看文件备份和恢复的VCB-Proxy工作流。
VCB图像备份/恢复是将VMDK文件输出到VCB代理服务器中,具体步骤如下:
1.备份工作要求VCB框架获取VM快照,并输出快照,输出路径包括SAN、C:mnt等。
2.系统文件等输出的图像文件通过备份程序进行备份。
3.备份软件要求VCB框架卸载VM快照,使VM不再具有快照功能。
4.利用备份程序,将输出的VM图像恢复到一个VMware能够访问的临时区域,该区域可能位于Proxy Server 或ESX Service Console,由此完成恢复工作。
5.VM图像加载到ESX主机中的指定位置。
在此点击,查看图像备份和恢复的VCB-Proxy工作流。
这种方法的优点包括:
你可以利用VCB Proxy中一个备份程序,备份所有的VM,而不必每个VM配备一个程序。
通过这种方法,VM资源能完全备份,只需简单备份少量的大型VMDK文件。
图像能快速恢复,因为只需恢复大型图像,而不必查找大量的小型图像。
将备份过程转移到VCB代理服务器中,降低了ESX服务器的开销。
这种备份方法无需LAN,在SAN中也能实现,从理论上讲,备份速度比基于LAN的备份方法要快。
这种方法的缺点包括:
能否实现自动化、能否方便地加以使用取决于第三方备份软件的能力。
如果没有某种形式的备份软件集成到备份过程中,要部署这种方法就变得非常复杂。
如果你想将文件直接恢复到VM中,就需要在VM中安装备份软件。
对于没有集成VSS的Windows系统,由VCB提供的图像备份会使数据处于相同的状态。
VCB不提供Windows系统状态的恢复机制,尽管有可能成功实现服务器完全恢复,但是如果在操作VM时,系统状态紊乱,就不能保证完全恢复。
部署技巧
请记住,VCB不是备份/恢复程序,而是一组能集成到第三方备份应用程序中的设施。
Proxy Server不是虚拟机。
VCB不能安装在虚拟中心的服务器中,也不能注册。
Proxy Server需要安装Windows 2003 Server、SP1或R2。
Proxy Server必须和ESX Servers安装在相同的LUN区域中。
VCB Proxy Server不支持多路径。
如果需要恢复文件,但你又不想为每个VM都安装备份程序,你就可以创建一个仅用于恢复的VM,这个VM包含备份和恢复程序,将文件恢复到这个VM中,然后通过网络共享将文件迁移到正确的目标VM中。
由北亚数据恢复中心(http://www.sjhf.net)整理。
导读:服务器虚拟化,尤其是VMware形式的服务器虚拟化使IT人员获益良多,这么说一点也不为过。据我们所见,服务器虚拟化能解决服务器扩张、资源消耗、服务器扩张、能源消耗、高可用性等相关问题。
服务器虚拟化,尤其是VMware形式的服务器虚拟化使IT人员获益良多,这么说一点也不为过。据我们所见,服务器虚拟化能解决服务器扩张、资源消耗、服务器扩张、能源消耗、高可用性等相关问题。服务器虚拟化也使我们有更多的时间解决其它的迫切问题,如企业资源预案升级、存储项目再三迁移或者为什么《星舰迷航记 11》要到2009年才上映。
尽管VMware提供封装技术和抽象技术,使我们受益匪浅,但数据保护领域发生的基本变革也带来了各项挑战。即使出现了VMware虚拟化,备份人员依然是牢骚最多的IT人员。最大的挑战在于保证数据的一致性,解决VMware物理资源过度消耗的问题。
VMware能将物理服务器封装成大型的硬盘图像文件--虚拟机磁盘格式(VMDK)文件,因此我们不禁认为:备份整台服务器应该和备份这些VMDK文件(当然也包括相关的配置文件)一样简单。
但是在大多数情况下,事实并非如此。除非已经关闭虚拟机(VM),否则,在运行状态下备份VM不能覆盖所有文件。换句话说,这种备份方式不能保证数据的一致性,因而也不能保证已恢复的VM包含足够的精确信息,不能说明服务器已成功恢复。
至于资源过度消耗的问题,这是虚拟化的副作用。利用VMware使系统虚拟化的一个关键原因是,将资源消耗集中在较少的物理服务器中,从而减少大多数IT服务器架构都存在的空闲周期。但是,这么也做带来了不良影响--无法找到足够资源,使数据备份不受阻碍地运行。
备份触到了VMware内部的脆弱之处:VMware处理过量磁盘和网络I/O的能力很弱。实际上,决定是否将物理服务器虚拟化取决于物理服务器中的磁盘密度、网络I/O。毋庸置疑,备份负载是VMware服务器承担的最大负载。
但是,的确有方法能解决这些问题,并且在某些情况下,比标准的物理服务器备份和恢复方法更加出众。但是,人们对这些方法存在一些误解,对第三方备份/恢复产品提供的实施措施也存在误解。实际上,许多管理员依然缺乏有效实现备份和恢复的方法,道路充满挫折。
方法1:在每个VM中安装本地备份程序
工作原理:这是一种传统的备份方法,在每个VM中安装备份程序,就像以前在每台物理服务器中安装备份程序。如下图所示,数据通过LAN流入备份/恢复设施,以往在本地物理服务器中安装备份程序时,数据流向也如此。
这种方法的优点如下:
备份程序的安装和配置与在物理服务器中的安装和配置十分相似,所以无需专门技巧和程式变化。
恢复过程没有发生变化,与将文件恢复到物理服务器的过程十分相似。
这样,就有可能恢复文件;这一点在我们采用其它方法时显得更加重要。
也有可能实现完全备份和增量备份,同样,在我们讨论其它方法时,这一点显得尤为重要。
如果你采用专门的应用感知备份程序,如SQL或Exchange,这将有助于实现应用程序数据的一致性,由此实现的备份在应用程序上具有一致性。
这种方法的缺点如下:
由于所有的备份都在同一台服务器中运行,因而你需要十分小心,不要过度消耗VMware主机资源。
尽管服务器能封装成少量的大型VMDK文件,但备份程序对此一无所知,也就不能利用这一点提供快速的备份或恢复能力;而进行灾难恢复时,需要快速、全面地恢复服务器,从这点上讲,这种方法价值不大。
部署技巧
在物理服务器中,同时运行数据备份可能问题不大,因为物理服务器具有充足的闲置资源,但是对VMware虚拟架构而言,闲置资源已得到充分利用,多个备份操作就有可能阻塞物理服务器。从而,在进行虚拟化以后,应该修改备份手册,通过备份窗口避免资源过度重叠。
一个VM只允许一条数据流。VM的VMDK文件通常寄存在一个VMFS卷中,多条数据流操作很容易覆盖VMFS卷。因此,除非VMDK文件隔离在独立卷(RDM、 iSCSI LUN、或独立的VMFS卷)中,否则备份就应该单流运行,而不是多流运行。
方法2:ESX Service Console中安装备份程序
工作原理:这种方法是在ESX Service Console在安装备份程序,按下图备份VM中潜在的VMDK文件组。Service Console采用红帽子Linux操作系统,因此能够使用Linux备份程序。
这种方法的优点包括:
只需一个备份程序就能备份所有的VM,而不是一台VM配备一个备份程序。
通过这种方法,VM资源能完全备份,只需简单备份少量的大型VMDK文件。
图像能快速恢复,因为只需恢复大型图像,而不必查找大量的小型图像。
这种方法的缺点包括:
需要脚本才能自动关闭、快照和启动VM。为了保证备份过程应用程序数据的一致性,必须这么做。
不可能恢复文件,这种方法只能备份和恢复图像。另外,这也意味着不能实现增量备份。
VNware指出,其开发流程包括从ESX Server移除Service Console。VMware的ESX Server 3i在这一点上迈出了第一步。
部署技巧
为了保证应用程序的一致性,在备份VMDK之前应该关闭VM。
VMDK文件在备份窗口中静止不动。
很不幸,备份过程中VM失去效用。
VMDK文件利用Service Console中的备份程序进行备份。
如果不能关机,可以利用VMware快照功能拍摄运行中的VM,获取即时备份。
备份数据停留在相同的状态,因而不能保证数据的一致性。
同样,实现自动化也需要脚本。
不是所有的备份程序都支持这种方法,所以你需要事先进行调查。
对于应用程序数据一致性的备份,利用VSS使应用程序在备份之前停止运行。但是,这需要非常复杂的脚本。
你可以利用ESX Service Console 中的VCB设施,获取运行状态下虚拟机的快照:
vcbMounter设施:
创建VM的静态快照。
将快照投射到一组文件中,文件可能处于控制台的本地目录中,也可能处于LAN的远程目录中。
利用ESX控制台支持的备份软件对本地文件进行备份和恢复。
vcbRestore设施:
将VM恢复到初始站点或者其它站点,
如果你决定冒险采用脚本技术,就会发现错误校验和更正是脚本技术最难的一个方面,需要编写大量代码。
方法3:VMware集中备份(VCB-Proxy)
工作原理:这种方法涉及一组VMware设施,通常称为VMware集中备份。这种方法使集中的Windows 2003代理服务器中的非LAN备份与相同的SAN卷相连,称为ESX Server。随后,数据通过第三方备份软件传送到代理服务器中,作为后序备份。这种方法比上述两种方法更为复杂,包括以下组件:
备份代理服务器:
服务器能与VMware主机访问相同的卷。
代理服务器中加载/输出VMDK文件的图像。
这种加载/输出图像通过寄存在代理服务器中的备份程序实现备份。
VCB框架:
ESX服务器中的"同步推动器"能刷新文件系统,创建快照。
VCB代理服务器中的"vLUN推动器"允许服务器中存在VMDK文件。
采用VCB自动工作流,命令行设施(vcbMounter/vcbRestore)发挥作用。
备份软件集成模块:
模块集成到VCB框架的组件中。
VMware和备份程序都能开发并支持这种模块。
备份程序之间的集成和使用变量相对简单。
在此点击,查看采用备份代理服务器的VMware集中备份示意图。
采用备份代理服务器的VMware集中备份能够执行非LAN文件备份和非LAN图像备份。但是,这两种方法的实现途径截然不同。
VCB文件备份/恢复是在VCB代理服务器中加载VMDK文件,具体步骤如下:
1备份工作要求VCB框架获取VM快照,在VCB代理服务器中加载VB快照,加载路径包括SAN、C:mnt等。
2利用备份程序备份(完全、增量、差异备份)目录/文件。
3备份程序要求VCB框架卸载VM快照,使VM不再具有快照功能。
4通过安装在VM中的备份程序,文件经由LAN恢复到初始VM中。
在此点击,查看文件备份和恢复的VCB-Proxy工作流。
VCB图像备份/恢复是将VMDK文件输出到VCB代理服务器中,具体步骤如下:
1.备份工作要求VCB框架获取VM快照,并输出快照,输出路径包括SAN、C:mnt等。
2.系统文件等输出的图像文件通过备份程序进行备份。
3.备份软件要求VCB框架卸载VM快照,使VM不再具有快照功能。
4.利用备份程序,将输出的VM图像恢复到一个VMware能够访问的临时区域,该区域可能位于Proxy Server 或ESX Service Console,由此完成恢复工作。
5.VM图像加载到ESX主机中的指定位置。
在此点击,查看图像备份和恢复的VCB-Proxy工作流。
这种方法的优点包括:
你可以利用VCB Proxy中一个备份程序,备份所有的VM,而不必每个VM配备一个程序。
通过这种方法,VM资源能完全备份,只需简单备份少量的大型VMDK文件。
图像能快速恢复,因为只需恢复大型图像,而不必查找大量的小型图像。
将备份过程转移到VCB代理服务器中,降低了ESX服务器的开销。
这种备份方法无需LAN,在SAN中也能实现,从理论上讲,备份速度比基于LAN的备份方法要快。
这种方法的缺点包括:
能否实现自动化、能否方便地加以使用取决于第三方备份软件的能力。
如果没有某种形式的备份软件集成到备份过程中,要部署这种方法就变得非常复杂。
如果你想将文件直接恢复到VM中,就需要在VM中安装备份软件。
对于没有集成VSS的Windows系统,由VCB提供的图像备份会使数据处于相同的状态。
VCB不提供Windows系统状态的恢复机制,尽管有可能成功实现服务器完全恢复,但是如果在操作VM时,系统状态紊乱,就不能保证完全恢复。
部署技巧
请记住,VCB不是备份/恢复程序,而是一组能集成到第三方备份应用程序中的设施。
Proxy Server不是虚拟机。
VCB不能安装在虚拟中心的服务器中,也不能注册。
Proxy Server需要安装Windows 2003 Server、SP1或R2。
Proxy Server必须和ESX Servers安装在相同的LUN区域中。
VCB Proxy Server不支持多路径。
如果需要恢复文件,但你又不想为每个VM都安装备份程序,你就可以创建一个仅用于恢复的VM,这个VM包含备份和恢复程序,将文件恢复到这个VM中,然后通过网络共享将文件迁移到正确的目标VM中。
2009年3月18日星期三
用CONVERT 命令转换 FAT到 NTFS,合适吗?
作者:张宇,北亚硬盘数据恢复中心(http://www.bysjhf.com/),转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
CONVERT做完之后,不管分区有多大,每簇大小一定是512字节。原因嘛,实际上是程序员懒得考虑太多,直接转成每扇区大小1个簇最简单,但带来的问题就是文件系统切割单位太小,太散。管理起来效率会下降,寻址时不能以大块为单位,效率与安全性都不是太好。
所以如果FAT转NTFS,最好还是把数据COPY出来,再格式化成NTFS,再COPY进去。这样簇大小按分区大小有效地设置,比较均衡。
CONVERT做完之后,不管分区有多大,每簇大小一定是512字节。原因嘛,实际上是程序员懒得考虑太多,直接转成每扇区大小1个簇最简单,但带来的问题就是文件系统切割单位太小,太散。管理起来效率会下降,寻址时不能以大块为单位,效率与安全性都不是太好。
所以如果FAT转NTFS,最好还是把数据COPY出来,再格式化成NTFS,再COPY进去。这样簇大小按分区大小有效地设置,比较均衡。
2009年3月17日星期二
磁盘加密技术保障数据安全之七种武器
转自:http://security.ctocio.com.cn/securitycomment/431/8116931.shtml
北亚数据恢复中心整理(http://www.bysjhf.com)
TruCrypt、PGP、FreeOTFE、BitLocker、DriveCrypt和7-Zip,这些加密程序提供了异常可靠的实时加密功能,可以为你确保数据安全,避免数据丢失、被偷以及被窥视。
很少有IT专业人士还需要数据安全方面的培训,但是我们常常听说这样的事件:电脑或者硬盘被偷或丢失,里面存储了明文格式的数据,没有经过加密。
幸好,实时数据加密如今不再是某种奇异、成本高昂的技术。有些加密程序不是仅仅对单个文件进行加密,还能在文件里面、甚至直接在分区上创建虚拟磁盘,写入到虚拟磁盘上的任何数据都自动进行加密。在现代的硬件上,加密所需的开销极小;再也不需要使用专用硬件来进行加密。
本文介绍了用于创建及管理加密卷的应用程序,从Windows Vista自带的BitLocker加密程序,到用于加密电子邮件和即时消息的性能成熟的PGP桌面套件。你甚至不用花钱,就能获得异常可靠、良好实现的整个磁盘加密功能——不过在企业环境下,像可管理性或者支持服务这些特性完全值得花钱购买。
工具一、TrueCrypt 5.1a
费用:免费/开源
网址:www.truecrypt.org
TrueCrypt有足够充足的理由成为你最先试用的整个磁盘或者虚拟卷加密解决方案。除了免费和开源这两大优点外,该程序编写巧妙,非常易用,还有丰富的数据保护功能,是对整个系统(包括操作系统分区)进行加密的一种有效方法。
TrueCrypt让你可以选择先进加密标准(AES)、Serpent和Twofish等算法,这些算法可以单独使用,也可以采用不同组合(名为“级联”);还可选择Whirlpool、SHA-512和RIPEMD-160等散列算法。实际的加密有三种基本方法:可以把文件作为虚拟加密卷安装上去;可以把整个磁盘分区或者物理驱动器变成加密卷;还可以加密工作中的Windows操作系统卷,不过存在一些局限性。
加密卷可以用密码来保护;作为一个选项,也可以用密钥文件来保护,从而加强安全——比如可移动USB驱动器上的文件,这样你就可以建立一种双因子验证。如果创建了一个独立的虚拟卷,可以使用任何大小或者命名惯例的文件。该文件由TrueCrypt本身创建而成,然后经格式化,确保它看上去与随机数据毫无区别。
TrueCrypt的目的在于,任何经过加密的卷或者硬盘不会一眼就能看出来。没有明显的卷头、所需文件扩展名或者其他识别标记。唯一的例外就是加密的引导卷,引导卷里面有TrueCrypt引导装入程序——但这个产品将来的版本不可能隐藏整个卷、使用USB拇指驱动器或者光盘上的外部引导装入程序。说到那里,你也有可能创建在“旅行者模式”下使用的自我加密的USB驱动器——里面有TrueCrypt可执行文件的拷贝,可在任何机器上安装上去及运行,只要用户拥有管理员权限。
TrueCrypt还包括了所谓的“似是而非的否认”(plausible deniability)特性,最重要的就是能够把一个卷隐藏在另一个卷里面。隐藏卷有自己的密码,你没有办法确定某个TrueCrypt卷里面是不是隐藏了另一个卷。不过,如果你把太多的数据写入到外面那个卷,可能会破坏那个隐藏卷——但是作为一项保护措施,TrueCrypt提供了一个选项:你在安装外面那个卷时,可以把隐藏卷作为只读卷安装上去。
如果你在使用系统磁盘加密,实际的加密过程需要一段时间,不过这个过程可以暂停,需要时恢复加密(你可能在晚上需要对上锁房间里面的PC进行这种操作)。这个程序会坚持要求创建急救光盘,那样万一遇到灾难,可以用来引导电脑(一个缺点是:你无法对从非Windows引导装入程序来实现双引导的Windows系统进行加密。)
工具二、Windows Vista BitLocker
费用:包含在Vista终极版和Vista企业版内
网址:technet.microsoft.com/en-us/windowsvista/aa905065.aspx
只有Vista的企业版和终极版才有Vista自带的BitLocker,它是专门为了执行系统卷加密而设计的。它的初衷不是主要用于加密可移动卷,也无法像本文介绍的其他产品那样让你可以创建虚拟加密卷。它在开发当初就考虑到了集中管理,通过活动目录和组策略来实现管理。
不像TrueCrypt的系统磁盘加密,设置BitLocker需要目标系统中至少有两个卷:一个卷用来存放引导装入程序,另一个卷用来存放加密的系统文件。现有系统可使用BitLocker驱动器准备工具(如今微软为支持BitLocker的系统提供了这个额外工具)重新进行分区;但如果你在处理没有准备好的系统,也可以手动设置分区。
用BitLocker对卷进行加密时,会出现三个基本选择,涉及如何授权用户来访问加密卷。如果电脑有可信计算模块(TPM),那么它可以结合个人身份识别号(PIN)代码一起使用。第二个选择是创建一个可移动USB驱动器,里面含有授权数据,然后该数据与PIN结合使用,但使用这种方法的前提是相应电脑可以从USB连接的设备引导。如果你决定用这种方法,BitLocker会在磁盘加密前进行引导测试,确保系统可从USB设备引导。第三个选择就是用户只要输入PIN,不过这个PIN会相当长(25个字符以上),而且只能由操作系统来分配。
与其他任何整个磁盘加密系统一样,最慢的部分实际上是对驱动器进行加密;我那75GB硬盘容量的笔记本电脑大约用了三个半小时才加密完毕。幸好,BitLocker可以在其他工作处理的同时,在后台执行这项任务;甚至可以关闭系统,然后以后需要时恢复加密过程(我的建议是:晚上就让电脑留在上锁的房间,进行加密)。如果管理员需要访问或者解密某个卷,该卷的加密密钥也可保存到活动目录存储库中。如果你不在活动目录域中,也可以手动把密钥备份到文件中——当然,该文件应严加保护。
最后,尽管BitLocker最初的保护对象仅仅是操作系统卷,但也可以通过Vista的命令行界面,手动用它对非系统卷进行加密。
工具三、Dekart Private Disk 1.2
费用:每个用户45美元
网址:www.dekart.com
虽然Dekart Private Disk功能上类似其他加密程序,但坦率地说,至少有一项特性使得它不值得推荐。
首先,Dekart Private Disk的功能组合只比本文介绍的两款免费/开源产品实用了一点。用户可以创建虚拟加密卷、备份加密磁盘的卷头、根据用户活动来控制磁盘的安装及卸载,等等。惟一真正重要、而其他产品没有的特性就是“磁盘防火墙”(Disk Firewall),你可以用来授予或拒绝某些程序访问加密卷。
最能表明Private Disk在开发当初没有真正考虑安全的地方在于“恢复选项”(recovery option),它试图通过对密码实施蛮力(brute-force attack)攻击来确定私密磁盘的密码。任何专业的加密产品根本不会有这样的功能。这好比你为前门买了把锁定插销,发现它还带了一套撬锁工具——“生怕你丢了钥匙”。
既然在其他地方免费就能获得Private Disk的绝大部分特性,说不定其他地方得到了更好的实现,就很难对这种收费程序表示认可。
工具四、DriveCrypt
费用:每个用户59.95欧元(88.73美元)
网址:www.securstar.com
SecureStar公司的DriveCrypt其主要功能类似TrueCrypt和下面介绍的FreeOTFE——你可以从文件或者整个磁盘来创建加密容器、把一个加密驱动器隐藏在另一个里面,等等。至于比较先进的功能,比如整个磁盘加密,需要添加DriveCrypt PlusPack(185美元)。至于DriveCrypt提供的额外功能值不值得购买,那是仁者见仁的问题,因为许多人觉得免费产品具有的功能组合同样够用了。
如果你之前用过类似产品,那么标准版DriveCrypt的大部分加密功能表现会如你所料。可以在文件或者分区中创建虚拟加密磁盘、一段时间没有使用后自动锁住磁盘,还能在磁盘里面创建隐藏磁盘。DriveCrypt还让你可以把该产品的之前版本(ScramDisk和E4M)创建的磁盘安装上去,所以如果你从这两个版本程序中的某一个迁移到新版本,不会觉得备受冷落。
它具有免费产品没有的一些功能,包括能够对现有加密磁盘随意调整容量大小以及管理员密钥代管服务(不过后者在TrueCrypt和FreeOTFE中也能实现,只需手动备份卷头)。
DriveCrypt特有的另一项特性就是:你可以创建“DKF访问文件”,该文件允许第三方不需要卷密码,就可以访问加密卷。DKF密钥可以附加各种限制——它可以使用自己的密码(与你自有磁盘上的密码无关)、X天后到期失效,或者只能在某个时间段有效。这样,就有可能为访问加密驱动器提供一定的控制权。
要注意的是:默认状态下,该程序使用分区号0x74来标记已经过加密的整个分区——这样,该程序就比较容易识别及安装加密分区,但也意味着可能敌意的第三方极容易知道某个卷由DriveCrypt经过了加密。幸好,你可以通过设置程序选项来挫败这种行为……你可能应该这样,因为只有你才应当知道什么是加密容器、什么不是。
DriveCrypt最吸引人的地方就是能够把.WAV文件转变成用隐匿技术来加密的容器,无论文件是从光盘上抓过来的,还是重新创建的。每个样本的4位或者8位用于存储数据,所以一个700MB大的.WAV文件(长度相当于一张音乐光盘)可用来存储350MB或者175MB。因而生成的文件仍可以播放,但音频质量会受到一定程度的影响。(注意事项:使用普通光盘音乐文件恐怕不是个好主意,因为攻击者即便不能解密,也可以拿来光盘上抓过来的内容与你的文件进行比对,确定里面有没有隐藏数据。自己录音也许更好。)
工具五、FreeOTFE 3.00
费用:免费/开源
网址:www.freeotfe.org
FreeOTFE(OTFE的意思是“实时加密”)在许多方面与TureCrypt很相似——它提供了许多同样的特性,只是实施时有些地方略有不同;它还有一个版本使用条件非常宽松的软件许可证。
创建新卷的过程再次与TrueCrypt相似:有向导程序指导你完成整个过程,并且在每个步骤提供了相关选项。FreeOTFE有着一系列更丰富的选项,这些选项涉及卷的随机数据串(salt)与散列的长度、密码、密钥和磁盘扇区系统,不过对大多数用户而言,使用默认选择就可以了。有些选项主要是为了向后兼容而提供的,比如现已过时的MD2和MD4散列函数——新创建的硬盘使用SHA512或者更好的函数。
TrueCrypt似乎所没有的另一个出色特性是,卷安装上去后以及卷卸载前后,可以运行任意脚本——比如清除临时文件或者取证时用到的文件(以免被人抓住把柄)。对Linux用户而言另一项方便的特性就是,能够使用自带的Linux文件系统加密驱动器,比如Crypttoloop、dm-crypt和LUKS。
与TrueCrypt一样,你也可以选择创建独立的密钥文件,但这种机制有点不同。TrueCrypt用于卷的密钥文件可以是任何文件,因为它使用了只读方式。FreeOTFE是从头开始创建密钥文件,用于存储卷的元数据块,密钥文件可能放在USB闪存盘上,以进一步增强物理安全。用户为新卷生成随机数据时,可以选择使用微软的CryptoAPI函数、通过鼠标移动生成的数据以增强随机性,或者是两者都用。
另外与TrueCrypt一样,FreeOTFE可以用来在一个加密卷中隐藏另一个加密卷,但是这个过程稍稍复杂一些。用户需要手动指定“字节偏移”值,该值描述了隐藏卷将位于何处。如果你不知道偏移值(以及隐藏卷的密码),就根本无法把隐藏卷安装上去。这还有可能把加密卷隐藏到未加密卷中,不过有点难度。
FreeOTFE特别注重移植性。该程序的用户设置可以保存到用户自己的配置文件,也可以用全局方式来保存(即保存到该程序目录)。另外与TrueCrypt一样,FreeOTFE也有“移植模式”——因而可以把FreeOTFE可执行文件和加密卷放到可移动磁盘上,那样可以在另一台电脑上使用,即使这台电脑上面没有安装FreeOTFE。最后,FreeOTFE可供基于Windows Mobile 6的个人数字助理(PDA)使用;台式电脑上创建或者使用的卷可以在PDA上使用,反之亦然。
工具六、PGP Desktop专业版
费用:每个用户199美元
网址:www.pgp.com
PGP Desktop提供了一整套加密工具,而开发这些工具的初衷是为了尽可能完美地与Windows系统集成,不管使用怎样的程序组合(不过这条规则也有几个例外)。它最适合这种用户:寻找广泛 的加密范围,并且愿意花些钱来购买功能完备的产品。
该程序的主界面有五个基本部分:密钥管理、邮件、压缩、磁盘管理和网络共享(NetShare)。密钥管理部分是可能开始入手的地方——你可以在此创建新的加密密钥、从外部的密钥环(keyring)导入现有密钥、发布密钥到PGP的全局密钥存储库(还可以搜索存储库里面的其他密钥),等等。
邮件部分控制着PGP Desktop如何处理电子邮件。在默认状态下,PGP Desktop能够对标准的SMTP/POP电子邮件、Exchange/MAPI邮件以及Lotus Notes邮件进行加密。PGP Desktop可代理及监控双向传送的电子邮件,并且在需要时采取行动,而不是改动电子邮件客户端。如果发送给你的邮件使用你密钥环中的密钥进行了加密,邮件会自动解密。还可以创建策略,规定拦截及加密多少邮件——比方说,发送到除某个域外其他所有域的邮件可用明文格式发送。即时消息(IM)加密系统(也通过本地代理系统来工作)仅支持美国在线的Instant Messenger(AIM)和Trillian;使用AIM协议的其他程序可以使用,但PGP不能为它们作出保证。IM加密对每次登录都使用1024位的一次性RSA密钥;邮件采用AES 256位对称密钥来加密。
PGP Zip选项卡让你可以创建加密存档,这些存档可以在另一头用PGP来解压,或者封装成自解压存档。因而生成的存档还可以用口令短语或者接收方的密钥(如果接收方有密钥)进行签名及加密。如果只是用来创建密码保护、经过加密的文档,那不需要整个PGP套件——你可以使用许多独立的压缩程序来完成这项工作,但签名和密钥使用等特性通常是其他程序所没有的。
PGP Disk是套件中的整个磁盘或者虚拟卷加密解决方案。虚拟卷用起来很像TrueCrypt或者FreeOTFE:卷可以在任何文件中;但如果使用PGP,相应的某个卷(或多个卷)既可以用口令短语来保护,还可以用用户密钥来加密(使用AES、CAST5或者Twofish等算法)。
如果你使用了整个磁盘加密,可以在加密过程中选择几个选项:最大CPU占用率,目的是节省时间;电源故障安全选项,以便加密过程中万一出现断电,防止系统受到破坏。加密磁盘可以使用TPM硬件(如果你有这种硬件)或者USB闪存盘来存储密钥文件,也可以两者结合使用。PGP Disk另外有一个出色的特性:数据粉碎工具,类似自由软件Eraser产品。它可以清除文件,也可以只清除现有磁盘上的空余空间。
网络共享特性(PGP Desktop Storage和PGP Desktop Corporate这两个版本有该特性)让你可以共享便携式驱动器或者网络连接驱动器上的加密文件。所有解密在用户端进行,所以任何敏感信息绝对不会以明文格式传送,也用不着在文件服务器上安装特殊软件。网络共享还能与活动目录集成,以便对谁可以访问哪些信息实行细粒度管理。还可以对指定受保护文件夹外面的单个文件进行加密,不过这项特性需要单独启用(默认状态下该功能是禁用的)。
PGP Desktop并非只作为独立程序来使用——它还可以由企业环境下的PGP中央服务器程序(PGP Universal)来管理。如果你打算先在单个系统上使用,然后迁移到更集中管理的环境,那么PGP Desktop专业版是个很好的选择。
工具七、7-Zip
费用:免费/开源
网址:www.7-Zip.org
你可能认为开源归档程序7-Zip与本文介绍的其他程序不在同一档次,但如果你只是寻找临时应急的方法来创建经过加密、密码保护的存档,它其实是个不错的选择。7-Zip也能创建自解压存档,所以接收方不需要有7-Zip——只要你们事先约定好,任何密码都可以。不过,它本身并不支持任何一种双因子验证。另外为了提高安全性,创建存档时,一定要选择“加密文件名”选项。
结论
大多数想要保护磁盘的基本解决方案的人可能会试一试TrueCrypt(或者最接近它的FreeOTFE),尤其是鉴于前者提供了整个磁盘、引导卷的加密。PGP Desktop也添加了其他许多工具,对不仅需要加密磁盘上的内容、还希望加密电子邮件和即时消息的用户来说,这是个不错的选择。BitLocker的一大优点是,它是Vista自带的一项特性,可通过活动目录来进行集中管理。而DriveCrypt也有一些可能有用的隐匿和访问管理功能。7-Zip是创建经过加密、密码保护的存档的一种简单方法。遗憾的是,Dekart Private Disk很难称得上是专业的加密解决方案,因为它包括了一项荒谬的特性:可以对你交给该程序来保护的卷进行蛮力攻击。
北亚数据恢复中心整理(http://www.bysjhf.com)
TruCrypt、PGP、FreeOTFE、BitLocker、DriveCrypt和7-Zip,这些加密程序提供了异常可靠的实时加密功能,可以为你确保数据安全,避免数据丢失、被偷以及被窥视。
很少有IT专业人士还需要数据安全方面的培训,但是我们常常听说这样的事件:电脑或者硬盘被偷或丢失,里面存储了明文格式的数据,没有经过加密。
幸好,实时数据加密如今不再是某种奇异、成本高昂的技术。有些加密程序不是仅仅对单个文件进行加密,还能在文件里面、甚至直接在分区上创建虚拟磁盘,写入到虚拟磁盘上的任何数据都自动进行加密。在现代的硬件上,加密所需的开销极小;再也不需要使用专用硬件来进行加密。
本文介绍了用于创建及管理加密卷的应用程序,从Windows Vista自带的BitLocker加密程序,到用于加密电子邮件和即时消息的性能成熟的PGP桌面套件。你甚至不用花钱,就能获得异常可靠、良好实现的整个磁盘加密功能——不过在企业环境下,像可管理性或者支持服务这些特性完全值得花钱购买。
工具一、TrueCrypt 5.1a
费用:免费/开源
网址:www.truecrypt.org
TrueCrypt有足够充足的理由成为你最先试用的整个磁盘或者虚拟卷加密解决方案。除了免费和开源这两大优点外,该程序编写巧妙,非常易用,还有丰富的数据保护功能,是对整个系统(包括操作系统分区)进行加密的一种有效方法。
TrueCrypt让你可以选择先进加密标准(AES)、Serpent和Twofish等算法,这些算法可以单独使用,也可以采用不同组合(名为“级联”);还可选择Whirlpool、SHA-512和RIPEMD-160等散列算法。实际的加密有三种基本方法:可以把文件作为虚拟加密卷安装上去;可以把整个磁盘分区或者物理驱动器变成加密卷;还可以加密工作中的Windows操作系统卷,不过存在一些局限性。
加密卷可以用密码来保护;作为一个选项,也可以用密钥文件来保护,从而加强安全——比如可移动USB驱动器上的文件,这样你就可以建立一种双因子验证。如果创建了一个独立的虚拟卷,可以使用任何大小或者命名惯例的文件。该文件由TrueCrypt本身创建而成,然后经格式化,确保它看上去与随机数据毫无区别。
TrueCrypt的目的在于,任何经过加密的卷或者硬盘不会一眼就能看出来。没有明显的卷头、所需文件扩展名或者其他识别标记。唯一的例外就是加密的引导卷,引导卷里面有TrueCrypt引导装入程序——但这个产品将来的版本不可能隐藏整个卷、使用USB拇指驱动器或者光盘上的外部引导装入程序。说到那里,你也有可能创建在“旅行者模式”下使用的自我加密的USB驱动器——里面有TrueCrypt可执行文件的拷贝,可在任何机器上安装上去及运行,只要用户拥有管理员权限。
TrueCrypt还包括了所谓的“似是而非的否认”(plausible deniability)特性,最重要的就是能够把一个卷隐藏在另一个卷里面。隐藏卷有自己的密码,你没有办法确定某个TrueCrypt卷里面是不是隐藏了另一个卷。不过,如果你把太多的数据写入到外面那个卷,可能会破坏那个隐藏卷——但是作为一项保护措施,TrueCrypt提供了一个选项:你在安装外面那个卷时,可以把隐藏卷作为只读卷安装上去。
如果你在使用系统磁盘加密,实际的加密过程需要一段时间,不过这个过程可以暂停,需要时恢复加密(你可能在晚上需要对上锁房间里面的PC进行这种操作)。这个程序会坚持要求创建急救光盘,那样万一遇到灾难,可以用来引导电脑(一个缺点是:你无法对从非Windows引导装入程序来实现双引导的Windows系统进行加密。)
工具二、Windows Vista BitLocker
费用:包含在Vista终极版和Vista企业版内
网址:technet.microsoft.com/en-us/windowsvista/aa905065.aspx
只有Vista的企业版和终极版才有Vista自带的BitLocker,它是专门为了执行系统卷加密而设计的。它的初衷不是主要用于加密可移动卷,也无法像本文介绍的其他产品那样让你可以创建虚拟加密卷。它在开发当初就考虑到了集中管理,通过活动目录和组策略来实现管理。
不像TrueCrypt的系统磁盘加密,设置BitLocker需要目标系统中至少有两个卷:一个卷用来存放引导装入程序,另一个卷用来存放加密的系统文件。现有系统可使用BitLocker驱动器准备工具(如今微软为支持BitLocker的系统提供了这个额外工具)重新进行分区;但如果你在处理没有准备好的系统,也可以手动设置分区。
用BitLocker对卷进行加密时,会出现三个基本选择,涉及如何授权用户来访问加密卷。如果电脑有可信计算模块(TPM),那么它可以结合个人身份识别号(PIN)代码一起使用。第二个选择是创建一个可移动USB驱动器,里面含有授权数据,然后该数据与PIN结合使用,但使用这种方法的前提是相应电脑可以从USB连接的设备引导。如果你决定用这种方法,BitLocker会在磁盘加密前进行引导测试,确保系统可从USB设备引导。第三个选择就是用户只要输入PIN,不过这个PIN会相当长(25个字符以上),而且只能由操作系统来分配。
与其他任何整个磁盘加密系统一样,最慢的部分实际上是对驱动器进行加密;我那75GB硬盘容量的笔记本电脑大约用了三个半小时才加密完毕。幸好,BitLocker可以在其他工作处理的同时,在后台执行这项任务;甚至可以关闭系统,然后以后需要时恢复加密过程(我的建议是:晚上就让电脑留在上锁的房间,进行加密)。如果管理员需要访问或者解密某个卷,该卷的加密密钥也可保存到活动目录存储库中。如果你不在活动目录域中,也可以手动把密钥备份到文件中——当然,该文件应严加保护。
最后,尽管BitLocker最初的保护对象仅仅是操作系统卷,但也可以通过Vista的命令行界面,手动用它对非系统卷进行加密。
工具三、Dekart Private Disk 1.2
费用:每个用户45美元
网址:www.dekart.com
虽然Dekart Private Disk功能上类似其他加密程序,但坦率地说,至少有一项特性使得它不值得推荐。
首先,Dekart Private Disk的功能组合只比本文介绍的两款免费/开源产品实用了一点。用户可以创建虚拟加密卷、备份加密磁盘的卷头、根据用户活动来控制磁盘的安装及卸载,等等。惟一真正重要、而其他产品没有的特性就是“磁盘防火墙”(Disk Firewall),你可以用来授予或拒绝某些程序访问加密卷。
最能表明Private Disk在开发当初没有真正考虑安全的地方在于“恢复选项”(recovery option),它试图通过对密码实施蛮力(brute-force attack)攻击来确定私密磁盘的密码。任何专业的加密产品根本不会有这样的功能。这好比你为前门买了把锁定插销,发现它还带了一套撬锁工具——“生怕你丢了钥匙”。
既然在其他地方免费就能获得Private Disk的绝大部分特性,说不定其他地方得到了更好的实现,就很难对这种收费程序表示认可。
工具四、DriveCrypt
费用:每个用户59.95欧元(88.73美元)
网址:www.securstar.com
SecureStar公司的DriveCrypt其主要功能类似TrueCrypt和下面介绍的FreeOTFE——你可以从文件或者整个磁盘来创建加密容器、把一个加密驱动器隐藏在另一个里面,等等。至于比较先进的功能,比如整个磁盘加密,需要添加DriveCrypt PlusPack(185美元)。至于DriveCrypt提供的额外功能值不值得购买,那是仁者见仁的问题,因为许多人觉得免费产品具有的功能组合同样够用了。
如果你之前用过类似产品,那么标准版DriveCrypt的大部分加密功能表现会如你所料。可以在文件或者分区中创建虚拟加密磁盘、一段时间没有使用后自动锁住磁盘,还能在磁盘里面创建隐藏磁盘。DriveCrypt还让你可以把该产品的之前版本(ScramDisk和E4M)创建的磁盘安装上去,所以如果你从这两个版本程序中的某一个迁移到新版本,不会觉得备受冷落。
它具有免费产品没有的一些功能,包括能够对现有加密磁盘随意调整容量大小以及管理员密钥代管服务(不过后者在TrueCrypt和FreeOTFE中也能实现,只需手动备份卷头)。
DriveCrypt特有的另一项特性就是:你可以创建“DKF访问文件”,该文件允许第三方不需要卷密码,就可以访问加密卷。DKF密钥可以附加各种限制——它可以使用自己的密码(与你自有磁盘上的密码无关)、X天后到期失效,或者只能在某个时间段有效。这样,就有可能为访问加密驱动器提供一定的控制权。
要注意的是:默认状态下,该程序使用分区号0x74来标记已经过加密的整个分区——这样,该程序就比较容易识别及安装加密分区,但也意味着可能敌意的第三方极容易知道某个卷由DriveCrypt经过了加密。幸好,你可以通过设置程序选项来挫败这种行为……你可能应该这样,因为只有你才应当知道什么是加密容器、什么不是。
DriveCrypt最吸引人的地方就是能够把.WAV文件转变成用隐匿技术来加密的容器,无论文件是从光盘上抓过来的,还是重新创建的。每个样本的4位或者8位用于存储数据,所以一个700MB大的.WAV文件(长度相当于一张音乐光盘)可用来存储350MB或者175MB。因而生成的文件仍可以播放,但音频质量会受到一定程度的影响。(注意事项:使用普通光盘音乐文件恐怕不是个好主意,因为攻击者即便不能解密,也可以拿来光盘上抓过来的内容与你的文件进行比对,确定里面有没有隐藏数据。自己录音也许更好。)
工具五、FreeOTFE 3.00
费用:免费/开源
网址:www.freeotfe.org
FreeOTFE(OTFE的意思是“实时加密”)在许多方面与TureCrypt很相似——它提供了许多同样的特性,只是实施时有些地方略有不同;它还有一个版本使用条件非常宽松的软件许可证。
创建新卷的过程再次与TrueCrypt相似:有向导程序指导你完成整个过程,并且在每个步骤提供了相关选项。FreeOTFE有着一系列更丰富的选项,这些选项涉及卷的随机数据串(salt)与散列的长度、密码、密钥和磁盘扇区系统,不过对大多数用户而言,使用默认选择就可以了。有些选项主要是为了向后兼容而提供的,比如现已过时的MD2和MD4散列函数——新创建的硬盘使用SHA512或者更好的函数。
TrueCrypt似乎所没有的另一个出色特性是,卷安装上去后以及卷卸载前后,可以运行任意脚本——比如清除临时文件或者取证时用到的文件(以免被人抓住把柄)。对Linux用户而言另一项方便的特性就是,能够使用自带的Linux文件系统加密驱动器,比如Crypttoloop、dm-crypt和LUKS。
与TrueCrypt一样,你也可以选择创建独立的密钥文件,但这种机制有点不同。TrueCrypt用于卷的密钥文件可以是任何文件,因为它使用了只读方式。FreeOTFE是从头开始创建密钥文件,用于存储卷的元数据块,密钥文件可能放在USB闪存盘上,以进一步增强物理安全。用户为新卷生成随机数据时,可以选择使用微软的CryptoAPI函数、通过鼠标移动生成的数据以增强随机性,或者是两者都用。
另外与TrueCrypt一样,FreeOTFE可以用来在一个加密卷中隐藏另一个加密卷,但是这个过程稍稍复杂一些。用户需要手动指定“字节偏移”值,该值描述了隐藏卷将位于何处。如果你不知道偏移值(以及隐藏卷的密码),就根本无法把隐藏卷安装上去。这还有可能把加密卷隐藏到未加密卷中,不过有点难度。
FreeOTFE特别注重移植性。该程序的用户设置可以保存到用户自己的配置文件,也可以用全局方式来保存(即保存到该程序目录)。另外与TrueCrypt一样,FreeOTFE也有“移植模式”——因而可以把FreeOTFE可执行文件和加密卷放到可移动磁盘上,那样可以在另一台电脑上使用,即使这台电脑上面没有安装FreeOTFE。最后,FreeOTFE可供基于Windows Mobile 6的个人数字助理(PDA)使用;台式电脑上创建或者使用的卷可以在PDA上使用,反之亦然。
工具六、PGP Desktop专业版
费用:每个用户199美元
网址:www.pgp.com
PGP Desktop提供了一整套加密工具,而开发这些工具的初衷是为了尽可能完美地与Windows系统集成,不管使用怎样的程序组合(不过这条规则也有几个例外)。它最适合这种用户:寻找广泛 的加密范围,并且愿意花些钱来购买功能完备的产品。
该程序的主界面有五个基本部分:密钥管理、邮件、压缩、磁盘管理和网络共享(NetShare)。密钥管理部分是可能开始入手的地方——你可以在此创建新的加密密钥、从外部的密钥环(keyring)导入现有密钥、发布密钥到PGP的全局密钥存储库(还可以搜索存储库里面的其他密钥),等等。
邮件部分控制着PGP Desktop如何处理电子邮件。在默认状态下,PGP Desktop能够对标准的SMTP/POP电子邮件、Exchange/MAPI邮件以及Lotus Notes邮件进行加密。PGP Desktop可代理及监控双向传送的电子邮件,并且在需要时采取行动,而不是改动电子邮件客户端。如果发送给你的邮件使用你密钥环中的密钥进行了加密,邮件会自动解密。还可以创建策略,规定拦截及加密多少邮件——比方说,发送到除某个域外其他所有域的邮件可用明文格式发送。即时消息(IM)加密系统(也通过本地代理系统来工作)仅支持美国在线的Instant Messenger(AIM)和Trillian;使用AIM协议的其他程序可以使用,但PGP不能为它们作出保证。IM加密对每次登录都使用1024位的一次性RSA密钥;邮件采用AES 256位对称密钥来加密。
PGP Zip选项卡让你可以创建加密存档,这些存档可以在另一头用PGP来解压,或者封装成自解压存档。因而生成的存档还可以用口令短语或者接收方的密钥(如果接收方有密钥)进行签名及加密。如果只是用来创建密码保护、经过加密的文档,那不需要整个PGP套件——你可以使用许多独立的压缩程序来完成这项工作,但签名和密钥使用等特性通常是其他程序所没有的。
PGP Disk是套件中的整个磁盘或者虚拟卷加密解决方案。虚拟卷用起来很像TrueCrypt或者FreeOTFE:卷可以在任何文件中;但如果使用PGP,相应的某个卷(或多个卷)既可以用口令短语来保护,还可以用用户密钥来加密(使用AES、CAST5或者Twofish等算法)。
如果你使用了整个磁盘加密,可以在加密过程中选择几个选项:最大CPU占用率,目的是节省时间;电源故障安全选项,以便加密过程中万一出现断电,防止系统受到破坏。加密磁盘可以使用TPM硬件(如果你有这种硬件)或者USB闪存盘来存储密钥文件,也可以两者结合使用。PGP Disk另外有一个出色的特性:数据粉碎工具,类似自由软件Eraser产品。它可以清除文件,也可以只清除现有磁盘上的空余空间。
网络共享特性(PGP Desktop Storage和PGP Desktop Corporate这两个版本有该特性)让你可以共享便携式驱动器或者网络连接驱动器上的加密文件。所有解密在用户端进行,所以任何敏感信息绝对不会以明文格式传送,也用不着在文件服务器上安装特殊软件。网络共享还能与活动目录集成,以便对谁可以访问哪些信息实行细粒度管理。还可以对指定受保护文件夹外面的单个文件进行加密,不过这项特性需要单独启用(默认状态下该功能是禁用的)。
PGP Desktop并非只作为独立程序来使用——它还可以由企业环境下的PGP中央服务器程序(PGP Universal)来管理。如果你打算先在单个系统上使用,然后迁移到更集中管理的环境,那么PGP Desktop专业版是个很好的选择。
工具七、7-Zip
费用:免费/开源
网址:www.7-Zip.org
你可能认为开源归档程序7-Zip与本文介绍的其他程序不在同一档次,但如果你只是寻找临时应急的方法来创建经过加密、密码保护的存档,它其实是个不错的选择。7-Zip也能创建自解压存档,所以接收方不需要有7-Zip——只要你们事先约定好,任何密码都可以。不过,它本身并不支持任何一种双因子验证。另外为了提高安全性,创建存档时,一定要选择“加密文件名”选项。
结论
大多数想要保护磁盘的基本解决方案的人可能会试一试TrueCrypt(或者最接近它的FreeOTFE),尤其是鉴于前者提供了整个磁盘、引导卷的加密。PGP Desktop也添加了其他许多工具,对不仅需要加密磁盘上的内容、还希望加密电子邮件和即时消息的用户来说,这是个不错的选择。BitLocker的一大优点是,它是Vista自带的一项特性,可通过活动目录来进行集中管理。而DriveCrypt也有一些可能有用的隐匿和访问管理功能。7-Zip是创建经过加密、密码保护的存档的一种简单方法。遗憾的是,Dekart Private Disk很难称得上是专业的加密解决方案,因为它包括了一项荒谬的特性:可以对你交给该程序来保护的卷进行蛮力攻击。
2009年3月16日星期一
打造了一把安全的锁,不料把自己也锁在了里面
[个人随笔]
作者:张宇,北亚硬盘数据恢复中心(http://www.bysjhf.com/),转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
有人曾经说过,没有绝对的安全,只要破解它所花费的代价远高于其收益就是安全的了。从这个意义上讲,安全还真不能做得太绝了。不幸的是,我被自己的安全意识涮了一回。。
早在2004年,对一大堆的密码管理搞得我头晕眼花,当时为了安全考虑,多数的密码设置的都是随机字符,太多了,大脑就记不下来了。记在文本文件里、邮箱里、还是抄到本子上,都感觉不够安全。
于是,就找了个密码管理器,用的是雪狐密码管理器(免费版的)。但能让我后来悔死的是,为了安全,我用了一个从来没用过的密码,而且,坚决不在任何地方使用这个密码,也不告诉任何人。当然,为了自己能记得住,密码没有用随机生成的,而是和我密切相关的一些信息的组合。
当我记了大量的密码后,用到2006年的某个时间时,软件提示到期了。升级好后,好像软件又不怎么支持WIN2003(我一直是用WINDOWS 2003的),一次使用密码管理器后,竟然把密码库丢失了,差点让我崩溃。当然,亏得我是搞数据恢复的,这个还不是太难的事情。因此也摸了下软件的算法。
这个软件使用的数据库是TinyDB,在数据库内用用户设定的密码进行了加密,读数据时直接以加密方式读取,同时上层再用ZIP加密压缩一下这个库,密码相同。这就是作者提到的双重加密,工作时,先将ZIP解压生成临时TinyDB加密库进行读取,更新后再重新压缩,删除过程文件。因加密与解密的过程存在很多删除、创建文件的过程,所以在突发性的断电等操作时,可能会损坏数据库。
研究之后,有点不想用的感觉了。一是不好支持我的操作系统;二是免费软件还是不太健壮;三是ZIP的密码即使暴力破解也比较容易,双重密码其实更脆弱了(只要解了一个,另一个密码一样出来了,弄巧成拙了),另外也感觉这样记得太麻烦了,懒得处理了。所以,就按密码用途分类批量改了后,逼着自己记下几个算了。另外一些不常用的(其实有些非常非常重要),就记在这个库里不动它了。
到了2009年,忽然需要用到以前的一个重要密码,重新打开原来的雪狐密码管器(当然,是把时间改到2006年以前),竟然。。。竟然。。。。竟然不记得密码了。天晕地暗啊,当时的感觉完全是一个字:囧。郁闷死我了,无耐之下只好尝试搜刮忘记了,结果试了几天都没有试出来。我都快崩溃了。那个痛恨啊!
想尽了所有的办法,还是没办法想得起来,却忽然发现自己曾经记过一个提示,猜了半天,确定原来的密码里有我当时的出租屋的固定电话号码(8位固定电话)。于是费力气找回原来的号码(幸亏现在是2009年,再过几年,这个任务可能也完不成了,汗!),但无论如何组合也还是解不开。
于是,于是我真得火大了,决定用ZIP密码暴力破解方式搞定它。我确信原来的密码不会超过16位,猜测自己也不会用复杂的特殊字符。在定义好规则后,通过Advanced Archive Password Recovery里统计,发现需要近1年的时间。1年就1年吧,放到我的服务器上,让他跑一年,也要搞定它,哼!
既然确定密码里有原来的电话号码,就加个MASK吧。设好后?12345678掩码后(假设电话号码是12345678,我原来的密码是这样的规则,但前面的?是多少位的,是什么,我不知道),就等待着悲壮的暴破了。
一种长歌当哭的感觉啊。。。。。。
。。。。。。
等等!不对!屏幕上好像有反映。
我KAO,竟然屏幕上已经大大地跳出了对话框,密码是+12345678。我倒!
弱智的我,竟然只是在数字前加了一个“+”号。看来我真是大大高估了自己了。
游戏人生啊。
收获一下吧:
1、ZIP的密码加密算法很不健壮,我测试了一下,对全数据9位的密码群举,全部完成只需30多秒,太可怕了。看来以后真应该全用PGP 或者至少RAR的加密了。
2、密码还是不要按安全专家的建议,每个密码都不相同,都是乱字符,同时还一段时间后换,个人感觉可能会很累。当然,如果是商业用途,另当别论了。
作者:张宇,北亚硬盘数据恢复中心(http://www.bysjhf.com/),转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
有人曾经说过,没有绝对的安全,只要破解它所花费的代价远高于其收益就是安全的了。从这个意义上讲,安全还真不能做得太绝了。不幸的是,我被自己的安全意识涮了一回。。
早在2004年,对一大堆的密码管理搞得我头晕眼花,当时为了安全考虑,多数的密码设置的都是随机字符,太多了,大脑就记不下来了。记在文本文件里、邮箱里、还是抄到本子上,都感觉不够安全。
于是,就找了个密码管理器,用的是雪狐密码管理器(免费版的)。但能让我后来悔死的是,为了安全,我用了一个从来没用过的密码,而且,坚决不在任何地方使用这个密码,也不告诉任何人。当然,为了自己能记得住,密码没有用随机生成的,而是和我密切相关的一些信息的组合。
当我记了大量的密码后,用到2006年的某个时间时,软件提示到期了。升级好后,好像软件又不怎么支持WIN2003(我一直是用WINDOWS 2003的),一次使用密码管理器后,竟然把密码库丢失了,差点让我崩溃。当然,亏得我是搞数据恢复的,这个还不是太难的事情。因此也摸了下软件的算法。
这个软件使用的数据库是TinyDB,在数据库内用用户设定的密码进行了加密,读数据时直接以加密方式读取,同时上层再用ZIP加密压缩一下这个库,密码相同。这就是作者提到的双重加密,工作时,先将ZIP解压生成临时TinyDB加密库进行读取,更新后再重新压缩,删除过程文件。因加密与解密的过程存在很多删除、创建文件的过程,所以在突发性的断电等操作时,可能会损坏数据库。
研究之后,有点不想用的感觉了。一是不好支持我的操作系统;二是免费软件还是不太健壮;三是ZIP的密码即使暴力破解也比较容易,双重密码其实更脆弱了(只要解了一个,另一个密码一样出来了,弄巧成拙了),另外也感觉这样记得太麻烦了,懒得处理了。所以,就按密码用途分类批量改了后,逼着自己记下几个算了。另外一些不常用的(其实有些非常非常重要),就记在这个库里不动它了。
到了2009年,忽然需要用到以前的一个重要密码,重新打开原来的雪狐密码管器(当然,是把时间改到2006年以前),竟然。。。竟然。。。。竟然不记得密码了。天晕地暗啊,当时的感觉完全是一个字:囧。郁闷死我了,无耐之下只好尝试搜刮忘记了,结果试了几天都没有试出来。我都快崩溃了。那个痛恨啊!
想尽了所有的办法,还是没办法想得起来,却忽然发现自己曾经记过一个提示,猜了半天,确定原来的密码里有我当时的出租屋的固定电话号码(8位固定电话)。于是费力气找回原来的号码(幸亏现在是2009年,再过几年,这个任务可能也完不成了,汗!),但无论如何组合也还是解不开。
于是,于是我真得火大了,决定用ZIP密码暴力破解方式搞定它。我确信原来的密码不会超过16位,猜测自己也不会用复杂的特殊字符。在定义好规则后,通过Advanced Archive Password Recovery里统计,发现需要近1年的时间。1年就1年吧,放到我的服务器上,让他跑一年,也要搞定它,哼!
既然确定密码里有原来的电话号码,就加个MASK吧。设好后?12345678掩码后(假设电话号码是12345678,我原来的密码是这样的规则,但前面的?是多少位的,是什么,我不知道),就等待着悲壮的暴破了。
一种长歌当哭的感觉啊。。。。。。
。。。。。。
等等!不对!屏幕上好像有反映。
我KAO,竟然屏幕上已经大大地跳出了对话框,密码是+12345678。我倒!
弱智的我,竟然只是在数字前加了一个“+”号。看来我真是大大高估了自己了。
游戏人生啊。
收获一下吧:
1、ZIP的密码加密算法很不健壮,我测试了一下,对全数据9位的密码群举,全部完成只需30多秒,太可怕了。看来以后真应该全用PGP 或者至少RAR的加密了。
2、密码还是不要按安全专家的建议,每个密码都不相同,都是乱字符,同时还一段时间后换,个人感觉可能会很累。当然,如果是商业用途,另当别论了。
2009年3月15日星期日
对磁盘做完整镜像(按扇区对扇区备份)的目的
作者:张宇,北亚硬盘数据恢复中心(http://www.bysjhf.com ),转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
磁盘完整镜像的目的大致有几个:
1、对非WINDOWS的操作系统或工控系统进行备份,以实现迁移或当操作系统损坏后还原。
2、对裸分区、加密分区或非正规分区进行备份。
3、备份数据时,希望很容易保留原字符集状态、权限、安全描述等。
4、ISCSI磁盘、SAN磁盘、虚拟机虚拟磁盘与物理硬盘做系统测试、迁移时可以利用此方法。
5、当源存储介质处于不稳定状态时,为了改名不稳定状态的进一步蔓延,做完整的备份。这种方式有时候优于COPY,因COPY会多次读取某个扇区(比如节点区、主目录区等),如果这些扇区是不稳定的,或者正好处于磁信息不稳定区,COPY可能会导致硬盘快速损坏。
6、进行数据迁移。当源介质里的文件量很大,接近总空间,同时文件数目又非常多时。常规的COPY或TAR会花费极多的时间(因为要反复递归文件系统),如果用镜像,与文件无关,而且是连续读取,IO速度会快得多。一个简单的经验,如果一个WINDOWS分区,大小为100G,放了几百万或上千万个文件,如果COPY可能一天也完不成,但如果是全分区镜像,在普通的服务器上可能不到半小时。
7、取证功能。很多计算机取证是需要对原盘进行完整取证的。
8、数据恢复中提供一份COPY以供恢复。很多情况下,源设备的数据出现故障(数据删除、数据丢失、文件系统异常、数据库异常等),但设备还要继续工作(比如服务还要跑,或者数据是存储上的一个LUN),无法直接对设备进行处理,就需要将状态尽快保存下来,完整镜像就是做这个的。
9、数据恢复中为保证数据安全,以镜像提供冗余。特别重要的数据,如果需要进行数据恢复时,担心在恢复的过程中源介质物理或逻辑损坏,可能需要做一份完整的镜像COPY,以确保万无一失。
10、数据恢复中,如果某些结构包含物理坏扇区,无法修复。可以镜像到另外一块好介质后,再修复那些坏结构。
11、其他。
备份方式见:
如何对硬盘做完整的全盘镜像? (http://zhangyu.blog.51cto.com/197148/138974)
磁盘完整镜像的目的大致有几个:
1、对非WINDOWS的操作系统或工控系统进行备份,以实现迁移或当操作系统损坏后还原。
2、对裸分区、加密分区或非正规分区进行备份。
3、备份数据时,希望很容易保留原字符集状态、权限、安全描述等。
4、ISCSI磁盘、SAN磁盘、虚拟机虚拟磁盘与物理硬盘做系统测试、迁移时可以利用此方法。
5、当源存储介质处于不稳定状态时,为了改名不稳定状态的进一步蔓延,做完整的备份。这种方式有时候优于COPY,因COPY会多次读取某个扇区(比如节点区、主目录区等),如果这些扇区是不稳定的,或者正好处于磁信息不稳定区,COPY可能会导致硬盘快速损坏。
6、进行数据迁移。当源介质里的文件量很大,接近总空间,同时文件数目又非常多时。常规的COPY或TAR会花费极多的时间(因为要反复递归文件系统),如果用镜像,与文件无关,而且是连续读取,IO速度会快得多。一个简单的经验,如果一个WINDOWS分区,大小为100G,放了几百万或上千万个文件,如果COPY可能一天也完不成,但如果是全分区镜像,在普通的服务器上可能不到半小时。
7、取证功能。很多计算机取证是需要对原盘进行完整取证的。
8、数据恢复中提供一份COPY以供恢复。很多情况下,源设备的数据出现故障(数据删除、数据丢失、文件系统异常、数据库异常等),但设备还要继续工作(比如服务还要跑,或者数据是存储上的一个LUN),无法直接对设备进行处理,就需要将状态尽快保存下来,完整镜像就是做这个的。
9、数据恢复中为保证数据安全,以镜像提供冗余。特别重要的数据,如果需要进行数据恢复时,担心在恢复的过程中源介质物理或逻辑损坏,可能需要做一份完整的镜像COPY,以确保万无一失。
10、数据恢复中,如果某些结构包含物理坏扇区,无法修复。可以镜像到另外一块好介质后,再修复那些坏结构。
11、其他。
备份方式见:
如何对硬盘做完整的全盘镜像? (http://zhangyu.blog.51cto.com/197148/138974)
2009年3月13日星期五
对硬盘做镜像,按位与按文件有什么区别?
作者:张宇,北亚硬盘数据恢复中心(http://www.datahf.net/),转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
[网友问题]
对硬盘做镜像时,听说有按位与按文件两种,都有什么特点?都是用在什么情况下的?GHOST是哪种方式?
[回答]
备份工作的按位(实际上是按扇区)转存意味着与文件系统无关。数据源是什么样子、有多大,目标就是什么样子,就有多大。即使没有分区、或者无法识别的分区,或者分区逻辑结构有错误,都可以完整的(包括逻辑错误)一起备份到目标设备上。
按文件转存意思是要对文件系统解释后,只按文件的方式提取到目标设备上。这个转存程序必须可以解释对应的文件系统,同时不会提取非文件数据。他的数据量也取决于源设备文件总和,文件越多,需要转移的数据就越多。另外,以文件转存的方式在源与目标的物理位置上并不一一对应,就像从源盘把所有文件拷贝进目标设备一样,源盘的文件组织方式、物理排序、空间占用上也不必与目标设备相同。这种转存也不会把磁盘里的自由空间转移过去。
GHOST不加参数,默认的是以文件转存。所以,当系统中占用空间越大,GHOST备份出来的包越大。如果是分区(硬盘)对分区(硬盘),也是占用文件越多,花得时间越多。GHOST本身不对自由空间做转存,同时必须是GHOST所能识别的文件系统,所以GHOST不支持JFS、VXFS等特殊的文件系统,也无法备份非MBR类分区表管理的硬盘数据。GHOST不加参数时,不适合用在数据恢复领域。
通常按位转存是最彻底的转存方式,适合最完整的备份,比如数据恢复前的备份、非WINDOWS系统的备份,或者有特殊结构的备份,但要求空间较大。按文件转存适合对已知文件系统的批量文件备份。
2009年3月12日星期四
[答网友问]如何恢复盘阵数据?
作者:张宇,北亚服务器数据恢复中心(http://www.datahf.net),转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
[问题] 我单位有台ibM DS400磁盘阵列,接到一台IBM服务器上,从我的电脑中可以看到有两个大容量分区,但是偶尔一次(可能是断电以后),看不到其中一个大容量分区,怀疑有一组阵列掉了. 用SERVERAID 7 启动服务器,查看结果如图1234,对有红X的ID1硬盘进行“Identify Physical drive 1"操作时提示:“could not blink the device lights” 该阵列共两组,每组5块硬盘,现在刚接通电源时所有的硬盘灯都会亮一下,但是自检完成后,只有第一组的前四块硬盘灯在闪. 请问,如何在不损害现有数据的基础上恢复磁盘阵列?
附图:http://zhangyu.blog.51cto.com/attachment/200903/197148_1236853239.jpg
[回答] 这种情况比较常见,导致的原因很多,有可能是硬盘损坏、RAID信息丢失等。如果RAID信息丢失,数据是可以恢复的,通过图与你的描述不难看出,是两组RAID,每组RAID各自划分一个LOGICAL DRIVER,具体怎么组织的,暂时还不确定,但如果硬盘没有故障,只需通过专业的数据恢复手段即可恢复。
如果硬盘有的故障,要分析是哪方面的原因,通常SCSI硬盘可能有的故障有:坏道、固件损坏,磁头/电机损坏等。坏道与固件损坏通常都可以恢复数据,但磁头/电机损坏就需要开盘更换损坏件,决定成功率的因素较多。RAID出故障后,硬盘磁头/电机损坏的概率很低,这个不必太担心。 从专业的角度看,对你的情况给出的建议是: 1、如果可能先对硬盘做完整备份,备份方式见:http://www.datahf.net/jjfa/110557309.html 2、如果完全备份好后,可以试着用SERVERAID光盘引导进去,做一下强制上线,或者按原来的RAID结构重建第二组RAID。(当然前提是系统还看得到硬盘)有关风险,参见:http://zhangyu.blog.51cto.com/197148/132999 3、如果还是不行。建议带镜像找专业数据恢复公司处理一下。
4、数据恢复后,再新建RAID,把数据拷回去。
[问题] 我单位有台ibM DS400磁盘阵列,接到一台IBM服务器上,从我的电脑中可以看到有两个大容量分区,但是偶尔一次(可能是断电以后),看不到其中一个大容量分区,怀疑有一组阵列掉了. 用SERVERAID 7 启动服务器,查看结果如图1234,对有红X的ID1硬盘进行“Identify Physical drive 1"操作时提示:“could not blink the device lights” 该阵列共两组,每组5块硬盘,现在刚接通电源时所有的硬盘灯都会亮一下,但是自检完成后,只有第一组的前四块硬盘灯在闪. 请问,如何在不损害现有数据的基础上恢复磁盘阵列?
附图:http://zhangyu.blog.51cto.com/attachment/200903/197148_1236853239.jpg
{kind=link}
[回答] 这种情况比较常见,导致的原因很多,有可能是硬盘损坏、RAID信息丢失等。如果RAID信息丢失,数据是可以恢复的,通过图与你的描述不难看出,是两组RAID,每组RAID各自划分一个LOGICAL DRIVER,具体怎么组织的,暂时还不确定,但如果硬盘没有故障,只需通过专业的数据恢复手段即可恢复。
如果硬盘有的故障,要分析是哪方面的原因,通常SCSI硬盘可能有的故障有:坏道、固件损坏,磁头/电机损坏等。坏道与固件损坏通常都可以恢复数据,但磁头/电机损坏就需要开盘更换损坏件,决定成功率的因素较多。RAID出故障后,硬盘磁头/电机损坏的概率很低,这个不必太担心。 从专业的角度看,对你的情况给出的建议是: 1、如果可能先对硬盘做完整备份,备份方式见:http://www.datahf.net/jjfa/110557309.html 2、如果完全备份好后,可以试着用SERVERAID光盘引导进去,做一下强制上线,或者按原来的RAID结构重建第二组RAID。(当然前提是系统还看得到硬盘)有关风险,参见:http://zhangyu.blog.51cto.com/197148/132999 3、如果还是不行。建议带镜像找专业数据恢复公司处理一下。
4、数据恢复后,再新建RAID,把数据拷回去。
2009年3月11日星期三
在LINUX环境中,哪种文件系统存储更安全?
作者:张宇,北亚服务器数据恢复中心(http://www.datahf.net/),转载请联系作者,如果实在不想联系作者,至少请保留版权,谢谢。
[问题]
昨天我转载的一文中,提到了对于ext3 reiserfs xfs jfs文件系统不同读写性能的比较。见:http://zhangyu.blog.51cto.com/197148/137389
结论方面,我并不完全同意,但真没精力做那样系统的测试(很敬佩那位老外作者),从文件系统的设计看,那篇文章的测试结果相对是比较符合我的判断的。只是测试并未针对异常操作、崩溃保护方面,文中提到的也很少。
我以我个人看法,谈谈ext3 reiserfs xfs三种文件系统的安全性(jfs了解不多),泛泛而谈,应该有不当之处,欢迎提供不同的看法,以便改正。
ext3是多数LINUX上默认的文件系统,也是从传统UNIX文件系统的结构上演变而来的,文件系统设计得非常简单明了,以不同的块组进行数据、节点、块组表的组织。优点是很简单,尤其适用于频繁删除/增加文件、同时每级文件下的文件总数不多的文件系统。
因EXT3 B树的概念用得较少,在目录检索方面很差,所以同一组目录下不能放太多文件,目录结构也尽可能不能太复杂。
EXT3的日志功能设计很差,经常会遇到实然断电后,文件系统损坏的情况,实际上ext3对日志的检验、还原方面做得还很不够。
EXT3采用的数据存储方式相当表格化,格式化时就确定了固定数目的inode,并分配好了空间,当然会导致空间的大浪费,同时当文件太多,达到上限时,文件系统也无法负担。
EXT3采用全索引的方式对数据存储区域进行索引管理,所以,大量的文件碎片在EXT3上并不会导致严重的数据风险,随机寻址会更快。当然,浪费也会大一些。
总得看,EXT3并不是一个很安全的文件系统,如果从数据存储安全的角度看,并不推荐。
REISERFS是一个算法敏捷的文件系统,无处不在的树结构使得索引、遍历的适应范围极大,一个上几千万个文件的文件系统,通常也只需要约4级索引就可以到达。但因索引以整个文件系统中所有的节点为单位组织(一颗树),所以即使访问一个文件,复杂程序也不会很低。所以很容易理解的,MOUNT的时间会更长(读取一个根目录就需要从整个树的根读到叶,同时根目录节点并不是索引B树的根节点,也是普通的一个叶节点,这点和其他文件系统很不相同),同时目录节点有机地整合在整个节点树里,并以HASH为索引键值。
reiserfs的上述主要特征决定了,它在处理少量文件时的优势并不明显,反而会更慢,同时因复杂程度带来更强的不稳定性。但在处理大量文件时,它的稳定性也不会再下降多少,同时树的特征与目录节点的特征,遍历目录结构的性能也不会下降多少。所以特别适合大量文件(邮件系统、大量文件的网站服务器)的使用环境。
另外,reiserfs也是一种日志文件系统,但日志能力并不很强,日志方面我分析得不多,只从结构方面看,比EXT3的好一点(更加结构化了)。
xfs本身是SGI用在IRIX上的一种文件系统,设计结构感觉滴水不漏,随处可见的分层寻址机制(和REISERFS的设计可是大相径庭),让系统可以更快,更高效得处理指定文件。同时,XFS在寻址上大量运用位操作,这也使得处理大文件时效率更高。
xfs在目录结构组织方面比较类似于ext3,目录也是以普通数据文件的方式进行存储与管理,这样在应付大量文件读取时,索引性能稍差一些。
xfs文件系统的日志功能据其他资料讲相对要强一些(本人未作分析),通常不容易崩溃。
从数据删除与格式化角度看,XFS与REISERFS在删除与格式化后,都有机会完整恢复(并不清除节点里的关键信息)。但EXT3恢复的难度就会大很多(清除节点)。
简单的结论,XFS在文件数目不是特别多的情况下是较可靠的。REISERFS在大量小文件的文件系统(超过百万文件,且多数文件小于1MB)上是首选的。
本文出自 “张宇(数据恢复)” 博客,转载请与作者联系!
[问题]
昨天我转载的一文中,提到了对于ext3 reiserfs xfs jfs文件系统不同读写性能的比较。见:http://zhangyu.blog.51cto.com/197148/137389
结论方面,我并不完全同意,但真没精力做那样系统的测试(很敬佩那位老外作者),从文件系统的设计看,那篇文章的测试结果相对是比较符合我的判断的。只是测试并未针对异常操作、崩溃保护方面,文中提到的也很少。
我以我个人看法,谈谈ext3 reiserfs xfs三种文件系统的安全性(jfs了解不多),泛泛而谈,应该有不当之处,欢迎提供不同的看法,以便改正。
ext3是多数LINUX上默认的文件系统,也是从传统UNIX文件系统的结构上演变而来的,文件系统设计得非常简单明了,以不同的块组进行数据、节点、块组表的组织。优点是很简单,尤其适用于频繁删除/增加文件、同时每级文件下的文件总数不多的文件系统。
因EXT3 B树的概念用得较少,在目录检索方面很差,所以同一组目录下不能放太多文件,目录结构也尽可能不能太复杂。
EXT3的日志功能设计很差,经常会遇到实然断电后,文件系统损坏的情况,实际上ext3对日志的检验、还原方面做得还很不够。
EXT3采用的数据存储方式相当表格化,格式化时就确定了固定数目的inode,并分配好了空间,当然会导致空间的大浪费,同时当文件太多,达到上限时,文件系统也无法负担。
EXT3采用全索引的方式对数据存储区域进行索引管理,所以,大量的文件碎片在EXT3上并不会导致严重的数据风险,随机寻址会更快。当然,浪费也会大一些。
总得看,EXT3并不是一个很安全的文件系统,如果从数据存储安全的角度看,并不推荐。
REISERFS是一个算法敏捷的文件系统,无处不在的树结构使得索引、遍历的适应范围极大,一个上几千万个文件的文件系统,通常也只需要约4级索引就可以到达。但因索引以整个文件系统中所有的节点为单位组织(一颗树),所以即使访问一个文件,复杂程序也不会很低。所以很容易理解的,MOUNT的时间会更长(读取一个根目录就需要从整个树的根读到叶,同时根目录节点并不是索引B树的根节点,也是普通的一个叶节点,这点和其他文件系统很不相同),同时目录节点有机地整合在整个节点树里,并以HASH为索引键值。
reiserfs的上述主要特征决定了,它在处理少量文件时的优势并不明显,反而会更慢,同时因复杂程度带来更强的不稳定性。但在处理大量文件时,它的稳定性也不会再下降多少,同时树的特征与目录节点的特征,遍历目录结构的性能也不会下降多少。所以特别适合大量文件(邮件系统、大量文件的网站服务器)的使用环境。
另外,reiserfs也是一种日志文件系统,但日志能力并不很强,日志方面我分析得不多,只从结构方面看,比EXT3的好一点(更加结构化了)。
xfs本身是SGI用在IRIX上的一种文件系统,设计结构感觉滴水不漏,随处可见的分层寻址机制(和REISERFS的设计可是大相径庭),让系统可以更快,更高效得处理指定文件。同时,XFS在寻址上大量运用位操作,这也使得处理大文件时效率更高。
xfs在目录结构组织方面比较类似于ext3,目录也是以普通数据文件的方式进行存储与管理,这样在应付大量文件读取时,索引性能稍差一些。
xfs文件系统的日志功能据其他资料讲相对要强一些(本人未作分析),通常不容易崩溃。
从数据删除与格式化角度看,XFS与REISERFS在删除与格式化后,都有机会完整恢复(并不清除节点里的关键信息)。但EXT3恢复的难度就会大很多(清除节点)。
简单的结论,XFS在文件数目不是特别多的情况下是较可靠的。REISERFS在大量小文件的文件系统(超过百万文件,且多数文件小于1MB)上是首选的。
本文出自 “张宇(数据恢复)” 博客,转载请与作者联系!
2009年3月10日星期二
Linux各种文件系统(ext3,ReiserFS,jfs,xfs)的性能
转自:http://hi.baidu.com/xuzhi1977/blog/item/c5869758dfafbade9d82040a.html
北亚数据恢复中心(http://www.datahf.net)张宇略作整理。
下面是原文:
以下文章是我自己翻译的,后面有英文的原文。不当之处,敬请指教.
应该不是太新的文章,但是我我是2006-07-12的上午才看到的。哎........
2006-07-12 15:00 翻译完成
--------------------------------------------------------------------------------------------------------------
肠子都悔青了,昨天刚刚新加的硬盘上面的文件系统还是被我搞成了ext3。如果我能造一天注意到这篇文章的话........
----------------------------------------------------------------------------------------------------------------
Debian Administration
System Administration Tips and Resources
现在还可以得到的许多Linux filesystems 比较,但是他们中大多数是古老的,基于为人任务的或者在更老的情况下完成。 这篇基准测试文基于与老一代的适合一台文件服务器的11项硬件(奔腾II/III,EIDE硬盘)。
从最初编制到出版,文章已经产生许多变化,意见和建议改进。我目前正努力进行一些新的试验。(回答在原文范围的问题)。
结果将在大约在(2006年5月8日)可提供
汉斯
为什么要做基准测试?
我发现quantitative and reproductible benchmark基准使用2.6.x kernel。
Benoit在2003年在有512 MB RAM 的PIII 500服务器上使用大文件(1 + GB)实现12次试验。 这次试验信息十分丰富,但是结果对2.6.x kernel开始,主要适用于底座, 专门操作大的锉(例如,多媒体,科学,数据库)。
Piszcz 在2006年实现21项任务(有768 MB RAM 和一个400GBEIDE-133硬盘在PIII-500 模拟多种文件操作)。到目前为止,这测试看起来是在2.6.x kernel上的最全面的工作。 但是, 很多任务是人造的(例如, 复制和删除10,000个空目录,新建10,000个文件,递归分割文件),把这些结论应用到现实世界可能是无意义的。
因此, 这里测试的基准的目标是验证一些Piszcz(2006)的结论, 通过专门应用于现实世界在小型企业文件服务器(看见任务描述)里找到。
测试基础
* Hardware Processor : Intel Celeron 533
* RAM : 512MB RAM PC100
* Motherboard : ASUS P2B
* Hard drive : WD Caviar SE 160GB (EIDE 100, 7200 RPM, 8MB Cache)
* Controller : ATA/133 PCI (Silicon Image)
* OS Debian Etch (kernel 2.6.15), distribution upgraded . April 18, 2006
* All optional daemons killed (cron,ssh,saMBa,etc.)
* Filesystems Ext3 (e2fsprogs 1.38)
* ReiserFS (reiserfsprogs 1.3.6.19)
* JFS (jfsutils 1.1.8)
* XFS (xfsprogs 2.7.14)
选择的测试任务描述
*在一个大文件(ISO 镜像文件,700 MB)的从第2个磁盘复制到这个试验磁盘
*再从在另一个位置再复制这个 ISO 一次
*删除这个ISO 的两个副本
*操作一文件树(有7500 文件,900 目录,1.9GB),从第2 磁盘复制到这个试验磁盘
*再从在另一个位置再复制这个文件树 一次
*删除这个文件树的两个副本
*用递归的方法遍历文件树目录和文件树的全部内容,复制到这个试验磁盘
*匹配通配符,在文件树查找具体的文件
*用(mkfs) 建立filesystem(全部FS都使用默认值)
*mount filesystem
*Umount filesystem
上述11项任务(从建立filesystem到umounting filesystem)的顺序,编写为Bash .运行完成3 次(报告平均成绩)。 每个顺序花费大约7分种,完成任务的时间用秒计算, GNU time utility (version 1.7) 记录任务时的CPU 的利用百分比。
结果
分区能力
(在filesystem 创造之后)初始化分区并重新划分block的过程里,Ext3有最差的初始利用率(92.77%), 其它的filesystem 几乎可是使用全部的容量(ReiserFS = 99.83%,JFS = 99.82%,XFS = 99.95%)。
结论: 为了使用你的分区的的最大容量,选择ReiserFS,JFS或者XFS。
建立文件系统,mount和unmounting
在20GB的分区创造filesystem测试,划分为Ext3带14.7秒, 与为相比其他filesystem多2秒或更少。(ReiserFS = 2.2,JFS = 1.3,XFS = 0.7)。
不过,挂载ReiserFS 要比其他的FS多花费5-15倍时间(2.3秒)(Ext3 = 0.2, JFS = 0.2, XFS = 0.5),umount以及要比其他的FS多花费2 倍时间(0.4秒)。
所有的FS都花费差不多CPU占用来创建FS(59%(ReiserFS) -74%(JFS)),挂载FS(在6和9%之间)。 不过,Ext3 和XFS多用2倍的CPU占用 给umount(37% 和45%), ReiserFS和JFS(14% 和27%)。
结论: 对创建FS性能和mounting/unmounting来说,选择JFS或者XFS。
大文件操作性能(ISO image,700 MB)
把大文件复制到Ext3(38.2秒)和ReiserFS(41.8), 要比JFS和XFS(35.1和34.8)需要更多时间。使用XFS有助于提高在相同的磁盘上复制相同的文件(XFS=33.1,Ext3 = 37.3,JFS = 39.4,ReiserFS = 43.9)相比。 在JFS和XFS上删除那些ISO 大约要快100 倍(0.02秒),(ReiserFS1.5秒,Ext32.5秒)!所有FS复制时的CPU利用(在46和51%之间),再复制时(在38%到50%之间)。当其他FS使用大约10%时,ReiserFS使用49%的CPU。 比他FS大约少5到10%),JFS使用较少的CPU。
结论: 对大文件操作性能来说,最好选择JFS或者XFS。 如果你需要使CPU利用减到最小,更推荐JFS。
目录树(7500个文件,900份目录,1.9GB)的操作
最初复制目录树时,Ext3(158.3秒)和XFS(166.1秒)更迅速, ReiserFS和JFS(172.1和180.1)。在第二次复制的时候有相似的结果。(Ext3=120秒,XFS = 135.2,ReiserFS = 136.9 和JFS = 151)。但是, 移动目录树时Ext3(22秒)相比ReiserFS(8.2秒, XFS(10.5秒)和JFS(12.5秒))大约多2倍时间!所有FS在复制和再复制目录树时都使用较多的CPU (复制在27和36%之间),(再复制在29%-JFS和45%-ReiserFS之间)。
令人吃惊,ReiserFS 和XFS使用更多的CPU 删除目录树(86% 和65%), 而其他FS只使用大约15%的(Ext3和JFS)。再次,与任何其他FS相比较,JFS的明显使用较少CPU。 当有较多的数量较小页面时适合ReiserFS。这个差别在目录树的再复制和移动里的ReiserFS将有更高的速度。
结论:对在大容量的目录树操作来说,选择Ext3或者XFS。 来自其他作者的基准测试已经证明如果使用ReiserFS,对大量的小文件更为合适。但是,目前包括各种各样尺寸(10KB在5 MB)数千文件的目录树操作上,建议使用Ext3或者XFS可能获得更好的性能。如果JFS的CPU占用减到最小,这种FS带着相当高的性能。
目录列表和文件查找
递归显示目录的目录列表,ReiserFS(1.4秒)和XFS更迅速的1.8), Ext3和JFS(2.5和3.1)。文件查找有着相同的结果。在文件查找项目, ReiserFS(0.8秒)相比XFS(2.8)和Ext3(4.6秒)和JFS(5秒)更迅速。 Ext3和JFS有更好CPU占用:目录列表(35%),文件查找(6%)。 XFS目录列表(70%)使用更多的CPU,文件查找(10%)。 ReiserFS 看起来是占用CPU最多的FS,目录列表71%,文件查找36% 。
结论: 结果表明那, 对于这些CPU占用任务来说,(ext3和JFS)filesystems 能更少的使用CPU的。 XFS作为好备选,带有相对适中的性能和CPU的占用。
总的结论
这些结果从Piszcz(2006)关于分解的Ext3,ReiserFS的磁盘能力报告一样。 这两篇文章两篇已经显示JFS是最低的CPU利用的FS。 最后,这份报告看起来没有显示出ReiserFS的high page faults activity
由于一个分区只能有一个filesystem,认识每种filesystem的优缺点很重要。如果,以这篇文章的全部测试为基准, XFS看起来是家庭或者小型企业最适合的应用于文件服务器的filesystem:
*它使用你的服务器硬盘(s)的拥有最大的容量
*创建FS,mount和unmount很迅速
*操作大文件最迅速的FS(>500 MB)
*这FS得第二名地方给经营关于许多在适度尺寸文件和目录小
*在CPU占用和目录列表或者文件搜寻性能之间比较平衡,
*没有最小CPU要求,老一代硬件也可十分接受
Piszcz(2006)当时没有明确推荐XFS,他只是说:"就个人来说,我仍然愿意选择同时具备性能和可伸缩性的XFS"。 现在我只能支持这个结论。
参考
贝努瓦,M.(2003)。 Linux 文件系统基准。
Piszcz,J.(2006)。 基准问题测试Filesystems第二部分。 Linux Gazette, 122 (January 2006)。
以下是原文
-----------------------------------------------------------------------
Debian Administration
System Administration Tips and Resources
[ About Archive FAQ Hall of Fame Search Tagged Articles
Filesystems (ext3, reiser, xfs, jfs) comparison . Debian Etch
There are a lot of Linux filesystems comparisons available but most of them are anecdotal, based . artificial tasks or completed under older kernels. This benchmark essay is based . 11 real-world tasks appropriate for a file server with older generation hardware (Pentium II/III, EIDE hard-drive).
Since its initial publication, this article has generated
a lot of questions, comments and suggestions to improve it.
Consequently, I'm currently working hard . a new batch of tests
to answer as many questions as possible (within the original scope
of the article).
Results will be available in about two weeks (May 8, 2006)
Many thanks for your interest and keep in touch with
Debian-Administration.org!
Hans
Why another benchmark test?
I found two quantitative and reproductible benchmark testing studies using the 2.6.x kernel (see References). Benoit (2003) implemented 12 tests using large files (1+ GB) . a Pentium II 500 server with 512MB RAM. This test was quite informative but results are beginning to aged (kernel 2.6.0) and mostly applied to settings which manipulate exclusively large files (e.g., multimedia, scientific, databases).
Piszcz (2006) implemented 21 tasks simulating a variety of file operations . a PIII-500 with 768MB RAM and a 400GB EIDE-133 hard disk. To date, this testing appears to be the most comprehensive work . the 2.6 kernel. However, since many tasks were "artificial" (e.g., copying and removing 10 000 empty directories, touching 10 000 files, splitting files recursively), it may be difficult to transfer some conclusions to real-world settings.
Thus, the objective of the present benchmark testing is to complete some Piszcz (2006) conclusions, by focusing exclusively . real-world operations found in small-business file servers (see Tasks de.ion).
Test settings
* Hardware Processor : Intel Celeron 533
* RAM : 512MB RAM PC100
* Motherboard : ASUS P2B
* Hard drive : WD Caviar SE 160GB (EIDE 100, 7200 RPM, 8MB Cache)
* Controller : ATA/133 PCI (Silicon Image)
* OS Debian Etch (kernel 2.6.15), distribution upgraded . April 18, 2006
* All optional daemons killed (cron,ssh,saMBa,etc.)
* Filesystems Ext3 (e2fsprogs 1.38)
* ReiserFS (reiserfsprogs 1.3.6.19)
* JFS (jfsutils 1.1.8)
* XFS (xfsprogs 2.7.14)
De.ion of selected tasks
* Operations . a large file (ISO image, 700MB) Copy ISO from a second disk to the test disk
* Recopy ISO in another location . the test disk
* Remove both copies of ISO
* Operations . a file tree (7500 files, 900 directories, 1.9GB) Copy file tree from a second disk to the test disk
* Recopy file tree in another location . the test disk
* Remove both copies of file tree
* Operations into the file tree List recursively all contents of the file tree and save it . the test disk
* Find files matching a specific wildcard into the file tree
* Operations . the file system Creation of the filesystem (mkfs) (all FS were created with default values)
* Mount filesystem
* Umount filesystem
The sequence of 11 tasks (from creation of FS to umounting FS) was run as a Bash . which was completed three times (the average is reported). Each sequence takes about 7 min. Time to complete task (in secs), percentage of CPU dedicated to task and number of major/minor page faults during task were computed by the GNU time utility (version 1.7).
RESULTS
Partition capacity
Initial (after filesystem creation) and residual (after removal of all files) partition capacity was computed as the ratio of number of available blocks by number of blocks . the partition. Ext3 has the worst inital capacity (92.77%), while others FS preserve almost full partition capacity (ReiserFS = 99.83%, JFS = 99.82%, XFS = 99.95%). Interestingly, the residual capacity of Ext3 and ReiserFS was identical to the initial, while JFS and XFS lost about 0.02% of their partition capacity, suggesting that these FS can dynamically grow but do not completely return to their inital state (and size) after file removal.
Conclusion : To use the maximum of your partition capacity, choose ReiserFS, JFS or XFS.
File system creation, mounting and unmounting
The creation of FS . the 20GB test partition took 14.7 secs for Ext3, compared to 2 secs or less for other FS (ReiserFS = 2.2, JFS = 1.3, XFS = 0.7). However, the ReiserFS took 5 to 15 times longer to mount the FS (2.3 secs) when compared to other FS (Ext3 = 0.2, JFS = 0.2, XFS = 0.5), and also 2 times longer to umount the FS (0.4 sec). All FS took comparable amounts of CPU to create FS (between 59% - ReiserFS and 74% - JFS) and to mount FS (between 6 and 9%). However, Ex3 and XFS took about 2 times more CPU to umount (37% and 45%), compared to ReiserFS and JFS (14% and 27%).
Conclusion : For quick FS creation and mounting/unmounting, choose JFS or XFS.
Operations . a large file (ISO image, 700MB)
The initial copy of the large file took longer . Ext3 (38.2 secs) and ReiserFS (41.8) when compared to JFS and XFS (35.1 and 34.8). The recopy . the same disk advantaged the XFS (33.1 secs), when compared to other FS (Ext3 = 37.3, JFS = 39.4, ReiserFS = 43.9). The ISO removal was about 100 times faster . JFS and XFS (0.02 sec for both), compared to 1.5 sec for ReiserFS and 2.5 sec for Ext3! All FS took comparable amounts of CPU to copy (between 46 and 51%) and to recopy ISO (between 38% to 50%). The ReiserFS used 49% of CPU to remove ISO, when other FS used about 10%. There was a clear trend of JFS to use less CPU than any other FS (about 5 to 10% less). The number of minor page faults was quite similar between FS (ranging from 600 - XFS to 661 - ReiserFS).
Conclusion : For quick operations . large files, choose JFS or XFS. If you need to minimize CPU usage, prefer JFS.
Operations . a file tree (7500 files, 900 directories, 1.9GB)
The initial copy of the tree was quicker for Ext3 (158.3 secs) and XFS (166.1) when compared to ReiserFS and JFS (172.1 and 180.1). Similar results were observed during the recopy . the same disk, which advantaged the Ext3 (120 secs) compared to other FS (XFS = 135.2, ReiserFS = 136.9 and JFS = 151). However, the tree removal was about 2 times longer for Ext3 (22 secs) when compared to ReiserFS (8.2 secs), XFS (10.5 secs) and JFS (12.5 secs)! All FS took comparable amounts of CPU to copy (between 27 and 36%) and to recopy the file tree (between 29% - JFS and 45% - ReiserFS). Surprisingly, the ReiserFS and the XFS used significantly more CPU to remove file tree (86% and 65%) when other FS used about 15% (Ext3 and JFS). Again, there was a clear trend of JFS to use less CPU than any other FS. The number of minor page faults was significantly higher for ReiserFS (total = 5843) when compared to other FS (1400 to 1490). This difference appears to come from a higher rate (5 to 20 times) of page faults for ReiserFS in recopy and removal of file tree.
Conclusion : For quick operations . large file tree, choose Ext3 or XFS. Benchmarks from other authors have supported the use of ReiserFS for operations . large number of small files. However, the present results . a tree comprising thousands of files of various size (10KB to 5MB) suggest than Ext3 or XFS may be more appropriate for real-world file server operations. Even if JFS minimize CPU usage, it should be noted that this FS comes with significantly higher latency for large file tree operations.
Directory listing and file search into the previous file tree
The complete (recursive) directory listing of the tree was quicker for ReiserFS (1.4 secs) and XFS (1.8) when compared to Ext3 and JFS (2.5 and 3.1). Similar results were observed during the file search, where ReiserFS (0.8 sec) and XFS (2.8) yielded quicker results compared to Ext3 (4.6 secs) and JFS (5 secs). Ext3 and JFS took comparable amounts of CPU for directory listing (35%) and file search (6%). XFS took more CPU for directory listing (70%) but comparable amount for file search (10%). ReiserFS appears to be the most CPU-intensive FS, with 71% for directory listing and 36% for file search. Again, the number of minor page faults was 3 times higher for ReiserFS (total = 1991) when compared to other FS (704 to 712).
Conclusion : Results suggest that, for these tasks, filesystems can be regrouped as (a) quick and more CPU-intensive (ReiserFS and XFS) or (b) slower but less CPU-intensive (ext3 and JFS). XFS appears as a good compromise, with relatively quick results, moderate usage of CPU and acceptable rate of page faults.
OVERALL CONCLUSION
These results replicate previous observations from Piszcz (2006) about reduced disk capacity of Ext3, longer mount time of ReiserFS and longer FS creation of Ext3. Moreover, like this report, both reviews have observed that JFS is the lowest CPU-usage FS. Finally, this report appeared to be the first to show the high page faults activity of ReiserFS . most usual file operations.
While recognizing the relative merits of each filesystem, .ly .e filesystem can be install for each partition/disk. Based . all testing done for this benchmark essay, XFS appears to be the most appropriate filesystem to install . a file server for home or small-business needs :
* It uses the maximum capacity of your server hard disk(s)
* It is the quickest FS to create, mount and unmount
* It is the quickest FS for operations . large files (>500MB)
* This FS gets a good second place for operations . a large number of small to moderate-size files and directories
* It constitutes a good CPU vs time compromise for large directory listing or file search
* It is not the least CPU demanding FS but its use of system ressources is quite acceptable for older generation hardware
While Piszcz (2006) did not explicitly recommand XFS, he concludes that "Personally, I still choose XFS for filesystem performance and scalability". I can .ly support this conclusion.
References
Benoit, M. (2003). Linux File System Benchmarks.
Piszcz, J. (2006). Benchmarking Filesystems Part II. Linux Gazette, 122 (January 2006).
Comment . this article
北亚RAID数据恢复中心张宇简单整理:
文件系统 ext3 reiserfs jfs xfs
mkfs后利用率 92.77% 99.83% 99.82% 99.95%
mkfsr耗时 14.7秒 2.2秒 1.3秒 0.7秒
mount耗时 0.2秒 2.3秒 0.2秒 0.5秒
大文件操作 37.3秒 43.9秒 39.4秒 33.1秒
目录树操作 158.3秒 172.1秒 180.1秒 166.1秒
目录列表和文件查找 2.5秒 1.4秒 2.5秒 1.8秒
北亚数据恢复中心(http://www.datahf.net)张宇略作整理。
下面是原文:
以下文章是我自己翻译的,后面有英文的原文。不当之处,敬请指教.
应该不是太新的文章,但是我我是2006-07-12的上午才看到的。哎........
2006-07-12 15:00 翻译完成
--------------------------------------------------------------------------------------------------------------
肠子都悔青了,昨天刚刚新加的硬盘上面的文件系统还是被我搞成了ext3。如果我能造一天注意到这篇文章的话........
----------------------------------------------------------------------------------------------------------------
Debian Administration
System Administration Tips and Resources
现在还可以得到的许多Linux filesystems 比较,但是他们中大多数是古老的,基于为人任务的或者在更老的情况下完成。 这篇基准测试文基于与老一代的适合一台文件服务器的11项硬件(奔腾II/III,EIDE硬盘)。
从最初编制到出版,文章已经产生许多变化,意见和建议改进。我目前正努力进行一些新的试验。(回答在原文范围的问题)。
结果将在大约在(2006年5月8日)可提供
汉斯
为什么要做基准测试?
我发现quantitative and reproductible benchmark基准使用2.6.x kernel。
Benoit在2003年在有512 MB RAM 的PIII 500服务器上使用大文件(1 + GB)实现12次试验。 这次试验信息十分丰富,但是结果对2.6.x kernel开始,主要适用于底座, 专门操作大的锉(例如,多媒体,科学,数据库)。
Piszcz 在2006年实现21项任务(有768 MB RAM 和一个400GBEIDE-133硬盘在PIII-500 模拟多种文件操作)。到目前为止,这测试看起来是在2.6.x kernel上的最全面的工作。 但是, 很多任务是人造的(例如, 复制和删除10,000个空目录,新建10,000个文件,递归分割文件),把这些结论应用到现实世界可能是无意义的。
因此, 这里测试的基准的目标是验证一些Piszcz(2006)的结论, 通过专门应用于现实世界在小型企业文件服务器(看见任务描述)里找到。
测试基础
* Hardware Processor : Intel Celeron 533
* RAM : 512MB RAM PC100
* Motherboard : ASUS P2B
* Hard drive : WD Caviar SE 160GB (EIDE 100, 7200 RPM, 8MB Cache)
* Controller : ATA/133 PCI (Silicon Image)
* OS Debian Etch (kernel 2.6.15), distribution upgraded . April 18, 2006
* All optional daemons killed (cron,ssh,saMBa,etc.)
* Filesystems Ext3 (e2fsprogs 1.38)
* ReiserFS (reiserfsprogs 1.3.6.19)
* JFS (jfsutils 1.1.8)
* XFS (xfsprogs 2.7.14)
选择的测试任务描述
*在一个大文件(ISO 镜像文件,700 MB)的从第2个磁盘复制到这个试验磁盘
*再从在另一个位置再复制这个 ISO 一次
*删除这个ISO 的两个副本
*操作一文件树(有7500 文件,900 目录,1.9GB),从第2 磁盘复制到这个试验磁盘
*再从在另一个位置再复制这个文件树 一次
*删除这个文件树的两个副本
*用递归的方法遍历文件树目录和文件树的全部内容,复制到这个试验磁盘
*匹配通配符,在文件树查找具体的文件
*用(mkfs) 建立filesystem(全部FS都使用默认值)
*mount filesystem
*Umount filesystem
上述11项任务(从建立filesystem到umounting filesystem)的顺序,编写为Bash .运行完成3 次(报告平均成绩)。 每个顺序花费大约7分种,完成任务的时间用秒计算, GNU time utility (version 1.7) 记录任务时的CPU 的利用百分比。
结果
分区能力
(在filesystem 创造之后)初始化分区并重新划分block的过程里,Ext3有最差的初始利用率(92.77%), 其它的filesystem 几乎可是使用全部的容量(ReiserFS = 99.83%,JFS = 99.82%,XFS = 99.95%)。
结论: 为了使用你的分区的的最大容量,选择ReiserFS,JFS或者XFS。
建立文件系统,mount和unmounting
在20GB的分区创造filesystem测试,划分为Ext3带14.7秒, 与为相比其他filesystem多2秒或更少。(ReiserFS = 2.2,JFS = 1.3,XFS = 0.7)。
不过,挂载ReiserFS 要比其他的FS多花费5-15倍时间(2.3秒)(Ext3 = 0.2, JFS = 0.2, XFS = 0.5),umount以及要比其他的FS多花费2 倍时间(0.4秒)。
所有的FS都花费差不多CPU占用来创建FS(59%(ReiserFS) -74%(JFS)),挂载FS(在6和9%之间)。 不过,Ext3 和XFS多用2倍的CPU占用 给umount(37% 和45%), ReiserFS和JFS(14% 和27%)。
结论: 对创建FS性能和mounting/unmounting来说,选择JFS或者XFS。
大文件操作性能(ISO image,700 MB)
把大文件复制到Ext3(38.2秒)和ReiserFS(41.8), 要比JFS和XFS(35.1和34.8)需要更多时间。使用XFS有助于提高在相同的磁盘上复制相同的文件(XFS=33.1,Ext3 = 37.3,JFS = 39.4,ReiserFS = 43.9)相比。 在JFS和XFS上删除那些ISO 大约要快100 倍(0.02秒),(ReiserFS1.5秒,Ext32.5秒)!所有FS复制时的CPU利用(在46和51%之间),再复制时(在38%到50%之间)。当其他FS使用大约10%时,ReiserFS使用49%的CPU。 比他FS大约少5到10%),JFS使用较少的CPU。
结论: 对大文件操作性能来说,最好选择JFS或者XFS。 如果你需要使CPU利用减到最小,更推荐JFS。
目录树(7500个文件,900份目录,1.9GB)的操作
最初复制目录树时,Ext3(158.3秒)和XFS(166.1秒)更迅速, ReiserFS和JFS(172.1和180.1)。在第二次复制的时候有相似的结果。(Ext3=120秒,XFS = 135.2,ReiserFS = 136.9 和JFS = 151)。但是, 移动目录树时Ext3(22秒)相比ReiserFS(8.2秒, XFS(10.5秒)和JFS(12.5秒))大约多2倍时间!所有FS在复制和再复制目录树时都使用较多的CPU (复制在27和36%之间),(再复制在29%-JFS和45%-ReiserFS之间)。
令人吃惊,ReiserFS 和XFS使用更多的CPU 删除目录树(86% 和65%), 而其他FS只使用大约15%的(Ext3和JFS)。再次,与任何其他FS相比较,JFS的明显使用较少CPU。 当有较多的数量较小页面时适合ReiserFS。这个差别在目录树的再复制和移动里的ReiserFS将有更高的速度。
结论:对在大容量的目录树操作来说,选择Ext3或者XFS。 来自其他作者的基准测试已经证明如果使用ReiserFS,对大量的小文件更为合适。但是,目前包括各种各样尺寸(10KB在5 MB)数千文件的目录树操作上,建议使用Ext3或者XFS可能获得更好的性能。如果JFS的CPU占用减到最小,这种FS带着相当高的性能。
目录列表和文件查找
递归显示目录的目录列表,ReiserFS(1.4秒)和XFS更迅速的1.8), Ext3和JFS(2.5和3.1)。文件查找有着相同的结果。在文件查找项目, ReiserFS(0.8秒)相比XFS(2.8)和Ext3(4.6秒)和JFS(5秒)更迅速。 Ext3和JFS有更好CPU占用:目录列表(35%),文件查找(6%)。 XFS目录列表(70%)使用更多的CPU,文件查找(10%)。 ReiserFS 看起来是占用CPU最多的FS,目录列表71%,文件查找36% 。
结论: 结果表明那, 对于这些CPU占用任务来说,(ext3和JFS)filesystems 能更少的使用CPU的。 XFS作为好备选,带有相对适中的性能和CPU的占用。
总的结论
这些结果从Piszcz(2006)关于分解的Ext3,ReiserFS的磁盘能力报告一样。 这两篇文章两篇已经显示JFS是最低的CPU利用的FS。 最后,这份报告看起来没有显示出ReiserFS的high page faults activity
由于一个分区只能有一个filesystem,认识每种filesystem的优缺点很重要。如果,以这篇文章的全部测试为基准, XFS看起来是家庭或者小型企业最适合的应用于文件服务器的filesystem:
*它使用你的服务器硬盘(s)的拥有最大的容量
*创建FS,mount和unmount很迅速
*操作大文件最迅速的FS(>500 MB)
*这FS得第二名地方给经营关于许多在适度尺寸文件和目录小
*在CPU占用和目录列表或者文件搜寻性能之间比较平衡,
*没有最小CPU要求,老一代硬件也可十分接受
Piszcz(2006)当时没有明确推荐XFS,他只是说:"就个人来说,我仍然愿意选择同时具备性能和可伸缩性的XFS"。 现在我只能支持这个结论。
参考
贝努瓦,M.(2003)。 Linux 文件系统基准。
Piszcz,J.(2006)。 基准问题测试Filesystems第二部分。 Linux Gazette, 122 (January 2006)。
以下是原文
-----------------------------------------------------------------------
Debian Administration
System Administration Tips and Resources
[ About Archive FAQ Hall of Fame Search Tagged Articles
Filesystems (ext3, reiser, xfs, jfs) comparison . Debian Etch
There are a lot of Linux filesystems comparisons available but most of them are anecdotal, based . artificial tasks or completed under older kernels. This benchmark essay is based . 11 real-world tasks appropriate for a file server with older generation hardware (Pentium II/III, EIDE hard-drive).
Since its initial publication, this article has generated
a lot of questions, comments and suggestions to improve it.
Consequently, I'm currently working hard . a new batch of tests
to answer as many questions as possible (within the original scope
of the article).
Results will be available in about two weeks (May 8, 2006)
Many thanks for your interest and keep in touch with
Debian-Administration.org!
Hans
Why another benchmark test?
I found two quantitative and reproductible benchmark testing studies using the 2.6.x kernel (see References). Benoit (2003) implemented 12 tests using large files (1+ GB) . a Pentium II 500 server with 512MB RAM. This test was quite informative but results are beginning to aged (kernel 2.6.0) and mostly applied to settings which manipulate exclusively large files (e.g., multimedia, scientific, databases).
Piszcz (2006) implemented 21 tasks simulating a variety of file operations . a PIII-500 with 768MB RAM and a 400GB EIDE-133 hard disk. To date, this testing appears to be the most comprehensive work . the 2.6 kernel. However, since many tasks were "artificial" (e.g., copying and removing 10 000 empty directories, touching 10 000 files, splitting files recursively), it may be difficult to transfer some conclusions to real-world settings.
Thus, the objective of the present benchmark testing is to complete some Piszcz (2006) conclusions, by focusing exclusively . real-world operations found in small-business file servers (see Tasks de.ion).
Test settings
* Hardware Processor : Intel Celeron 533
* RAM : 512MB RAM PC100
* Motherboard : ASUS P2B
* Hard drive : WD Caviar SE 160GB (EIDE 100, 7200 RPM, 8MB Cache)
* Controller : ATA/133 PCI (Silicon Image)
* OS Debian Etch (kernel 2.6.15), distribution upgraded . April 18, 2006
* All optional daemons killed (cron,ssh,saMBa,etc.)
* Filesystems Ext3 (e2fsprogs 1.38)
* ReiserFS (reiserfsprogs 1.3.6.19)
* JFS (jfsutils 1.1.8)
* XFS (xfsprogs 2.7.14)
De.ion of selected tasks
* Operations . a large file (ISO image, 700MB) Copy ISO from a second disk to the test disk
* Recopy ISO in another location . the test disk
* Remove both copies of ISO
* Operations . a file tree (7500 files, 900 directories, 1.9GB) Copy file tree from a second disk to the test disk
* Recopy file tree in another location . the test disk
* Remove both copies of file tree
* Operations into the file tree List recursively all contents of the file tree and save it . the test disk
* Find files matching a specific wildcard into the file tree
* Operations . the file system Creation of the filesystem (mkfs) (all FS were created with default values)
* Mount filesystem
* Umount filesystem
The sequence of 11 tasks (from creation of FS to umounting FS) was run as a Bash . which was completed three times (the average is reported). Each sequence takes about 7 min. Time to complete task (in secs), percentage of CPU dedicated to task and number of major/minor page faults during task were computed by the GNU time utility (version 1.7).
RESULTS
Partition capacity
Initial (after filesystem creation) and residual (after removal of all files) partition capacity was computed as the ratio of number of available blocks by number of blocks . the partition. Ext3 has the worst inital capacity (92.77%), while others FS preserve almost full partition capacity (ReiserFS = 99.83%, JFS = 99.82%, XFS = 99.95%). Interestingly, the residual capacity of Ext3 and ReiserFS was identical to the initial, while JFS and XFS lost about 0.02% of their partition capacity, suggesting that these FS can dynamically grow but do not completely return to their inital state (and size) after file removal.
Conclusion : To use the maximum of your partition capacity, choose ReiserFS, JFS or XFS.
File system creation, mounting and unmounting
The creation of FS . the 20GB test partition took 14.7 secs for Ext3, compared to 2 secs or less for other FS (ReiserFS = 2.2, JFS = 1.3, XFS = 0.7). However, the ReiserFS took 5 to 15 times longer to mount the FS (2.3 secs) when compared to other FS (Ext3 = 0.2, JFS = 0.2, XFS = 0.5), and also 2 times longer to umount the FS (0.4 sec). All FS took comparable amounts of CPU to create FS (between 59% - ReiserFS and 74% - JFS) and to mount FS (between 6 and 9%). However, Ex3 and XFS took about 2 times more CPU to umount (37% and 45%), compared to ReiserFS and JFS (14% and 27%).
Conclusion : For quick FS creation and mounting/unmounting, choose JFS or XFS.
Operations . a large file (ISO image, 700MB)
The initial copy of the large file took longer . Ext3 (38.2 secs) and ReiserFS (41.8) when compared to JFS and XFS (35.1 and 34.8). The recopy . the same disk advantaged the XFS (33.1 secs), when compared to other FS (Ext3 = 37.3, JFS = 39.4, ReiserFS = 43.9). The ISO removal was about 100 times faster . JFS and XFS (0.02 sec for both), compared to 1.5 sec for ReiserFS and 2.5 sec for Ext3! All FS took comparable amounts of CPU to copy (between 46 and 51%) and to recopy ISO (between 38% to 50%). The ReiserFS used 49% of CPU to remove ISO, when other FS used about 10%. There was a clear trend of JFS to use less CPU than any other FS (about 5 to 10% less). The number of minor page faults was quite similar between FS (ranging from 600 - XFS to 661 - ReiserFS).
Conclusion : For quick operations . large files, choose JFS or XFS. If you need to minimize CPU usage, prefer JFS.
Operations . a file tree (7500 files, 900 directories, 1.9GB)
The initial copy of the tree was quicker for Ext3 (158.3 secs) and XFS (166.1) when compared to ReiserFS and JFS (172.1 and 180.1). Similar results were observed during the recopy . the same disk, which advantaged the Ext3 (120 secs) compared to other FS (XFS = 135.2, ReiserFS = 136.9 and JFS = 151). However, the tree removal was about 2 times longer for Ext3 (22 secs) when compared to ReiserFS (8.2 secs), XFS (10.5 secs) and JFS (12.5 secs)! All FS took comparable amounts of CPU to copy (between 27 and 36%) and to recopy the file tree (between 29% - JFS and 45% - ReiserFS). Surprisingly, the ReiserFS and the XFS used significantly more CPU to remove file tree (86% and 65%) when other FS used about 15% (Ext3 and JFS). Again, there was a clear trend of JFS to use less CPU than any other FS. The number of minor page faults was significantly higher for ReiserFS (total = 5843) when compared to other FS (1400 to 1490). This difference appears to come from a higher rate (5 to 20 times) of page faults for ReiserFS in recopy and removal of file tree.
Conclusion : For quick operations . large file tree, choose Ext3 or XFS. Benchmarks from other authors have supported the use of ReiserFS for operations . large number of small files. However, the present results . a tree comprising thousands of files of various size (10KB to 5MB) suggest than Ext3 or XFS may be more appropriate for real-world file server operations. Even if JFS minimize CPU usage, it should be noted that this FS comes with significantly higher latency for large file tree operations.
Directory listing and file search into the previous file tree
The complete (recursive) directory listing of the tree was quicker for ReiserFS (1.4 secs) and XFS (1.8) when compared to Ext3 and JFS (2.5 and 3.1). Similar results were observed during the file search, where ReiserFS (0.8 sec) and XFS (2.8) yielded quicker results compared to Ext3 (4.6 secs) and JFS (5 secs). Ext3 and JFS took comparable amounts of CPU for directory listing (35%) and file search (6%). XFS took more CPU for directory listing (70%) but comparable amount for file search (10%). ReiserFS appears to be the most CPU-intensive FS, with 71% for directory listing and 36% for file search. Again, the number of minor page faults was 3 times higher for ReiserFS (total = 1991) when compared to other FS (704 to 712).
Conclusion : Results suggest that, for these tasks, filesystems can be regrouped as (a) quick and more CPU-intensive (ReiserFS and XFS) or (b) slower but less CPU-intensive (ext3 and JFS). XFS appears as a good compromise, with relatively quick results, moderate usage of CPU and acceptable rate of page faults.
OVERALL CONCLUSION
These results replicate previous observations from Piszcz (2006) about reduced disk capacity of Ext3, longer mount time of ReiserFS and longer FS creation of Ext3. Moreover, like this report, both reviews have observed that JFS is the lowest CPU-usage FS. Finally, this report appeared to be the first to show the high page faults activity of ReiserFS . most usual file operations.
While recognizing the relative merits of each filesystem, .ly .e filesystem can be install for each partition/disk. Based . all testing done for this benchmark essay, XFS appears to be the most appropriate filesystem to install . a file server for home or small-business needs :
* It uses the maximum capacity of your server hard disk(s)
* It is the quickest FS to create, mount and unmount
* It is the quickest FS for operations . large files (>500MB)
* This FS gets a good second place for operations . a large number of small to moderate-size files and directories
* It constitutes a good CPU vs time compromise for large directory listing or file search
* It is not the least CPU demanding FS but its use of system ressources is quite acceptable for older generation hardware
While Piszcz (2006) did not explicitly recommand XFS, he concludes that "Personally, I still choose XFS for filesystem performance and scalability". I can .ly support this conclusion.
References
Benoit, M. (2003). Linux File System Benchmarks.
Piszcz, J. (2006). Benchmarking Filesystems Part II. Linux Gazette, 122 (January 2006).
Comment . this article
北亚RAID数据恢复中心张宇简单整理:
文件系统 ext3 reiserfs jfs xfs
mkfs后利用率 92.77% 99.83% 99.82% 99.95%
mkfsr耗时 14.7秒 2.2秒 1.3秒 0.7秒
mount耗时 0.2秒 2.3秒 0.2秒 0.5秒
大文件操作 37.3秒 43.9秒 39.4秒 33.1秒
目录树操作 158.3秒 172.1秒 180.1秒 166.1秒
目录列表和文件查找 2.5秒 1.4秒 2.5秒 1.8秒
订阅:
博文 (Atom)